
Are you tired of typing into your browser “Google.com”? Would you like to enter something else, but still get the same results as if you went to Google.com? … How about XXXDisc.net?
Heather Paulson noticed something odd during a test of the SEM/SEO/AM research service Syntryx, which is currently in beta.
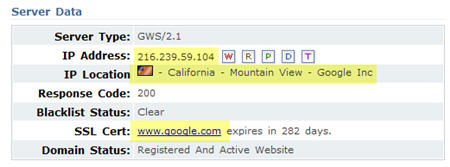
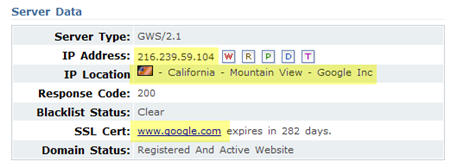
She stumbled across a site at the domain XXXDisc.net that shows weird stuff in the Who-Is records of domain name registrars. The other odd thing about the site is that it appears to be the search engine Google.com. The main part of the Who-Is record also seems to confirm that this site belongs to Google.
The site is hosted on a server with a number of other sites that have questionable content, to say it carefully. This is of course very unlikely. Another thing that is odd, is the fact that the site does not show the universal search navigation bar, but the old links above the search box to select the type of search you want to do (Web, Images, etc.). It also does not show a “sign-in” link to logon to your Google account and it has a link beneath the search box to http://www.google.com/ncr and the anchor text “Go to Google.com”.
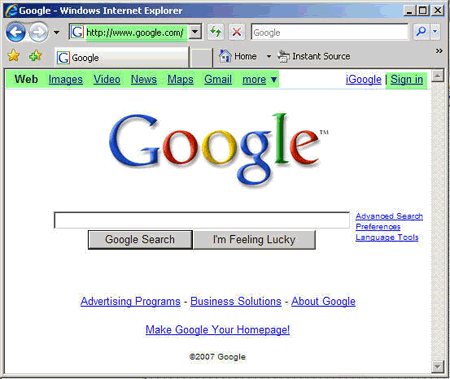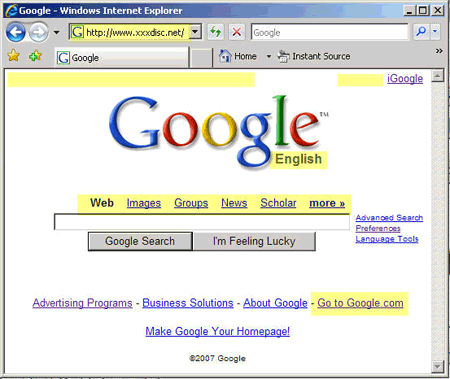
You can do searches and browse around to most of the content of the Google.com website while actually being on the XXXDisc.net site. That this is confusing, even for search marketers is not surprising.
I think that there are only two possible explanations for this. The first and most likely one is that the xxdisc.net site IS pulling the code from Google.com. It looks like a simple DNS forwarder to Google’s data center 39-GV (IP 216.239.59.104). The sites DNS Server is DNS1.NAME-SERVICES.COM.
If you ping the domain, it shows the real IP, which is 69.25.142.3 and not he Google data center IP. “No reverse DNS set” for that IP is the response, if I try to do a reverse lookup via online tools like the ones from DomainTools.com or by using the Windows tool “nslookup” on my local machine.
You can do a domain forwarding to any other domain (website) you want to, even if you don’t own the domain. There are common uses for this, most of the times for sub domains. Like this one. It is a sub domain of cumbrowski.com and even looks like my site. However, it is not my site and actually hosted and operated by somebody else. The “Branded Feed” option from (now Google’s) FeedBurner is another example of that.
It is not limited to sub domains and can be done with the top domain as well. A common use for that is the domain forwarding of other domains you own (e.g. your brand names and/or trademarks or TLD variations of the same domain name (e.g. .org, .net, .info)) for your business to your primary website domain (e.g. YouBusiness.com).
The registrant of the xxxdisc.net domain is a person in Zimbabwe.
High Av Video co
cosomer lee (123user AT hiavgirl DOT net)
+263.123555777
Fax: +263.123456777
West wood street 213# linken road
mogan, 432229
ZW
It does not seem to be a malicious attempt by that person to do something sneaky. He just does not use that domain yet and instead of having a parking service throwing up some stuff (e.g. ads) does he simply redirect to Google.
However, that Google (the site code) allows that the Google.com site is pulled via a different domain name that is not owned by Google is a big oversight by Google. Somebody with malicious intentions could use it for bad things. The Google site uses relative URLs, which keeps the user on the different domain.
I checked the logins, they redirect to Google.com, which is good, and because that prevents that, the login cookie is being created on that non-Google domain.
In addition, a link appears on the Homepage that reads. “Go to Google.com”, but that is not enough IMO. Google should (301) redirect any request to their sites if the domain is not the real Google domain or at least if it is not one of their domain properties.
This is not that easy, if the second explanation is true. This explanation of the site would not explain the weird information in the Who-Is record for that domain though.
It could be the case that the a script is running on that domain that takes all requests, then does a HTTP request to Google in the background on the server side and then returns the results as is or as an altered version to the end user in his browser.
I doubt that this is happening though. It redirects to Google from some of the links, I mentioned already the login links and other links that do not refer to secured sections of the site, such as the links on the Google products page, link to the actual Google domain. A scripter would have caught those and changed to local URLs on his domain.
If there is another plausable explaination that explains these things and a reason why Google would allow this to happen, I am curious to learn about it. What do you think?
Update 8/5/2007 11:00 pm PST: Important! Read the comments to this post below. It is getting even fuzzier.
Cheers!
Carsten Cumbrowski
Free Internet Marketing Resources Portal.
