
The Invisible Web (aka Deep Web) is that humoungous slice of the Internet’s web pages that traditional search engines either have not indexed or cannot index. Often, if they cannot index a page, it’s because the page is database-driven and requires a human trigger before it is rendered in your web browser. For example, you may have to ask a question, such as “show me all the job listings for project manager,” using an HTML form to enter information. In other instances, access to a web page requires authorization such as username and password.
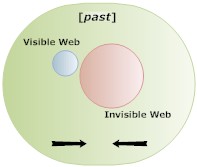 The end result is that only a relatively small slice of the Internet is indexed. Google may have the noble goal of indexing all the Earth’s information, but it’s an understatement to say that this will take some time – especially when the Invisible Web’s page already outnumber the Visible Web.
The end result is that only a relatively small slice of the Internet is indexed. Google may have the noble goal of indexing all the Earth’s information, but it’s an understatement to say that this will take some time – especially when the Invisible Web’s page already outnumber the Visible Web.
My own research into the Invisible Web shows that, not surprisingly, no one seems to have have an accurate figure as to how many pages are part of the Invisible Web since this number is constantly growing and never truly calculated. Approximations vary greatly. (I’m not mentioning anything here because the numbers I came across are several years old, and the mass of blogs created since have expanded the Invisible Web greatly.)
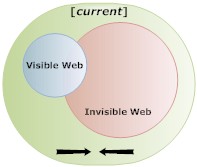 The fact is, it really doesn’t matter how many pages are invisible, just that they are so. Some traditional search engines and some of the great number of Web 2.0 search engines [Read/Write Web] (over 100 at last count), are making a noble attempt at indexing content that would otherwise remain “invisible”. There are also other ways, too, to expose the Invisible Web. Here are a few ways, which exclude passworded pages:
The fact is, it really doesn’t matter how many pages are invisible, just that they are so. Some traditional search engines and some of the great number of Web 2.0 search engines [Read/Write Web] (over 100 at last count), are making a noble attempt at indexing content that would otherwise remain “invisible”. There are also other ways, too, to expose the Invisible Web. Here are a few ways, which exclude passworded pages:
- List important pages in some sort of sitemap or site index.
- Bookmark pages at social bookmarking and promote at community news sites. Here are just a few (apologies that it’s not comprehensive).
- Del.icio.us.
- Digg.
- Netscape.
- Newsvine.
- Reddit.
- Shuzak.
- Stumbleupon.
- Yahoo! MyWeb.
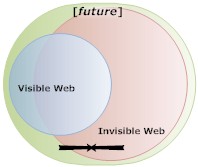 In other words, create links to invisible pages from visible (indexed) pages wherever you can. Most spiders will follow your links at their leisure and if they can index the currently invisible pages, they will.
In other words, create links to invisible pages from visible (indexed) pages wherever you can. Most spiders will follow your links at their leisure and if they can index the currently invisible pages, they will.
Of course, some engines are trying to make it easier to access currently invisible content. Enth.com offers access into database-driven content (not just web pages) by converting an English query into a database query. The datasets are currently limited and the results are not very accurate, but it’s a start.
My Computer Science Master’s Thesis was to have been on NQLs (Natural Query Languages) with a GIS (Geographical Information System) interface. My research predated my experience with online search engines, and my preliminary conclusion back in 1994 (I didnt finish) was in favor of English-like query. (Actually, I’d recommend something more phonetic like Esperanto.) We would, however, need a better understanding of how to parse the queries into something usable by computers. That would be the biggest hurdle.
Thirteen years later, I’m not entirely sure how much further we’ve gotten with NQLs for online search engines, if only because I haven’t maintained my research.
Still, I feel strongly that we’ll get to a point where we can speak queries and have a computer respond accurately. Though some like this cannot come about in a single generation of technology and research.
Whatever features and functionality today’s search engines offer us, whether voice-based or not, have to be refined in successive generations. Then, I think, much of our invisible online content will be easier to index and thus easier to retrieve through queries, making search so much better.
