

After starting to learn Python late last year, I’ve found myself putting into practice what I’ve been learning more and more for my daily tasks as an SEO professional.
This ranges from fairly simple tasks such as comparing how things such as word count or status codes have changed over time, to analysis pieces including internal linking and log file analysis.
In addition, Python has been really helpful:
- For working with large data sets.
- For files that would usually crash Excel and require complex analysis to extract any meaningful insights.
How Python Can Help With Technical SEO
Python empowers SEO professionals in a number of ways due to its ability to automate repetitive, low-level tasks that typically take a lot of time to complete.
This means we have more time (and energy) to spend on important strategic work and optimization efforts that cannot be automated.
It also enables us to work more efficiently with large amounts of data in order to make more data-driven decisions, which can in turn provide valuable returns on our work, and our clients’ work.
In fact, a study from McKinsey Global Institute found that data-driven organizations were 23 times more likely to acquire customers and six times as likely to retain those customers.
It’s also really helpful for backing up any ideas or strategies you have because you can quantify it with the data that you have and make decisions based on that, while also having more leverage power when trying to get things implemented.
Adding Python to Your SEO Workflow
The best way to add Python into your workflow is to:
- Think about what can be automated, especially when performing tedious tasks.
- Identify any gaps in the analysis work you are performing, or have completed.
I have found that another useful way to get started learning is to use the data you already have access to, and extract valuable insights from it using Python.
This is how I have learned most of the things I will be sharing in this article.
Learning Python isn’t necessary in order to become a good SEO pro, but if you’re interested in finding more about how it can help get ready to jump in.
What You Need to Get Started
In order to get the best results from this article there are a few things you will need:
- Some data from a website (e.g., a crawl of your website, Google Analytics, or Google Search Console data).
- An IDE (Integrated Development Environment) to run code on, for getting started I would recommend Google Colab or Jupyter Notebook.
- An open mind. This is perhaps the most important thing, don’t be afraid to break something or make mistakes, finding the cause of an issue and ways to fix it is a big part of what we do as SEO professionals, so applying this same mentality to learning Python is helpful to take any pressure off.
1. Trying Out Libraries
A great place to get started is to try out some of the many libraries which are available to use in Python.
There are a lot of libraries to explore, but three that I find most useful for SEO related tasks are Pandas, Requests, and Beautiful Soup.
Pandas
Pandas is a Python library used for working with table data, it allows for high-level data manipulation where the key data structure is a DataFrame.
DataFrames are essentially Pandas’ version of an Excel spreadsheet, however, it is not limited to Excel’s row and byte limits and also much faster and therefore efficient compared to Excel.

The best way to get started with Pandas is to take a simple CSV of data, for example, a crawl of your website, and save this within Python as a DataFrame.
Once you have this store you’ll be able to perform a number of different analysis tasks, including aggregating, pivoting, and cleaning data.
import pandas as pd
df = pd.read_csv("/file_name/and_path")
df.head
Requests
The next library is called Requests, which is used to make HTTP requests in Python.
It uses different request methods such as GET and POST to make a request, with the results being stored in Python.
One example of this in action is a simple GET request of URL, this will print out the status code of a page, which can then be used to create a simple decision-making function.
import requests
#Print HTTP response from page
response = requests.get('https://www.deepcrawl.com')
print(response)
#Create decision making function
if response.status_code == 200:
print('Success!')
elif response.status_code == 404:
print('Not Found.')
You can also use different requests, such as headers, which displays useful information about the page such as the content type and a time limit on how long it took to cache the response.
#Print page header response headers = response.headers print(headers) #Extract item from header response response.headers['Content-Type']

There is also the ability to simulate a specific user agent, such as Googlebot, in order to extract the response this specific bot will see when crawling the page.
headers = {'User-Agent': 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)'}
ua_response = requests.get('https://www.deepcrawl.com/', headers=headers)
print(ua_response)
Beautiful Soup
The final library is called Beautiful Soup, which is used to extract data from HTML and XML files.
It’s most often used for web scraping as it can transform an HTML document into different Python objects.
For example, you can take a URL and using Beautiful Soup, together with the Requests library, extract the title of the page.
#Beautiful Soup from bs4 import BeautifulSoup import requests #Request URL to extract elements from url= 'https://www.deepcrawl.com/knowledge/technical-seo-library/' req = requests.get(url) soup = BeautifulSoup(req.text, "html.parser") #Print title from webpage title = soup.title print(title)
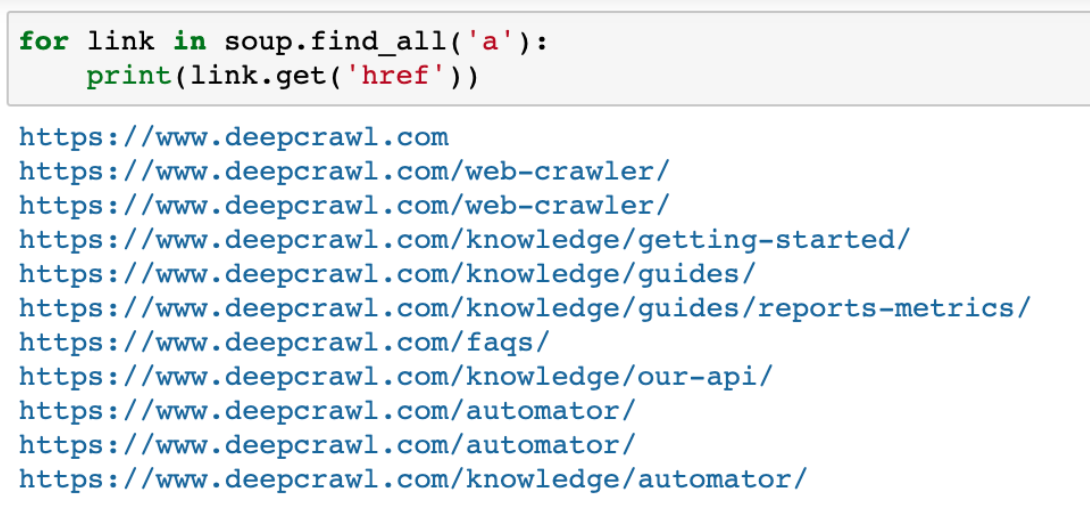
Additionally, Beautiful Soup enables you to extract other elements from a page such as all a href links that are found on the page.
for link in soup.find_all('a'):
print(link.get('href'))
2. Segmenting Pages
The first task involves segmenting a website’s pages, which is essentially grouping pages together in categories dependent on their URL structure or page title.
Start by using simple regex to break the site up into different segments based on their URL:
segment_definitions = [
[(r'\/blog\/'), 'Blog'],
[(r'\/technical-seo-library\/'), 'Technical SEO Library'],
[(r'\/hangout-library\/'), 'Hangout Library'],
[(r'\/guides\/'), 'Guides'],
]
Next, we add a small function that will loop through the list of URLs and assign each URL with a category, before adding these segments to a new column within the DataFrame which contains the original URL list.
use_segment_definitions = True
def segment(url):
if use_segment_definitions == True:
for segment_definition in segment_definitions:
if re.findall(segment_definition[0], url):
return segment_definition[1]
return 'Other'
df['segment'] = df['url'].apply(lambda x: get_segment(x))

There is also a way to segment pages without having to manually create the segments, using the URL structure. This will grab the folder that is contained after the main domain in order to categorize each URL.
Again, this will add a new column to our DataFrame with the segment that was generated.
def get_segment(url):
slug = re.search(r'https?:\/\/.*?\//?([^\/]*)\/', url)
if slug:
return slug.group(1)
else:
return 'None'
# Add a segment column, and make into a category
df['segment'] = df['url'].apply(lambda x: get_segment(x))

3. Redirect Relevancy
This task is something I would have never thought about doing if I wasn’t aware of what was possible using Python.
Following a migration, when redirects were put in place, we wanted to find out if the redirect mapping was accurate by reviewing if the category and depth of each page had changed or remained the same.
This involved taking a pre and post-migration crawl of the site and segmenting each page based on their URL structure, as mentioned above.
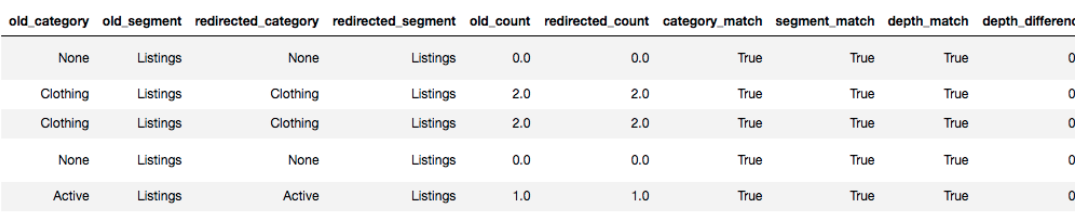
Following this I used some simple comparison operators, which are built into Python, to determine if the category and depth for each URL had changed.
df['category_match'] = df['old_category'] == (df['redirected_category']) df['segment_match'] = df['old_segment'] == (df['redirected_segment']) df['depth_match'] = df['old_count'] == (df['redirected_count']) df['depth_difference'] = df['old_count'] - (df['redirected_count'])
As this is essentially an automated script, it will run through each URL to determine if the category or depth has changed and output the results as a new DataFrame.
The new DataFrame will include additional columns displaying True if they match, or False if they don’t.
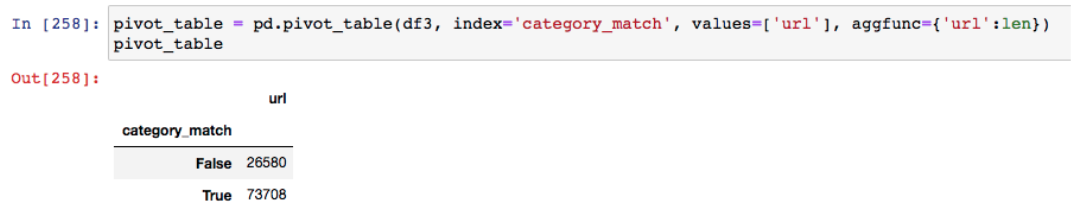
And just like in Excel, the Pandas library enables you to pivot data based on an index from the original DataFrame.
For example, to get a count of how many URLs had matching categories following the migration.
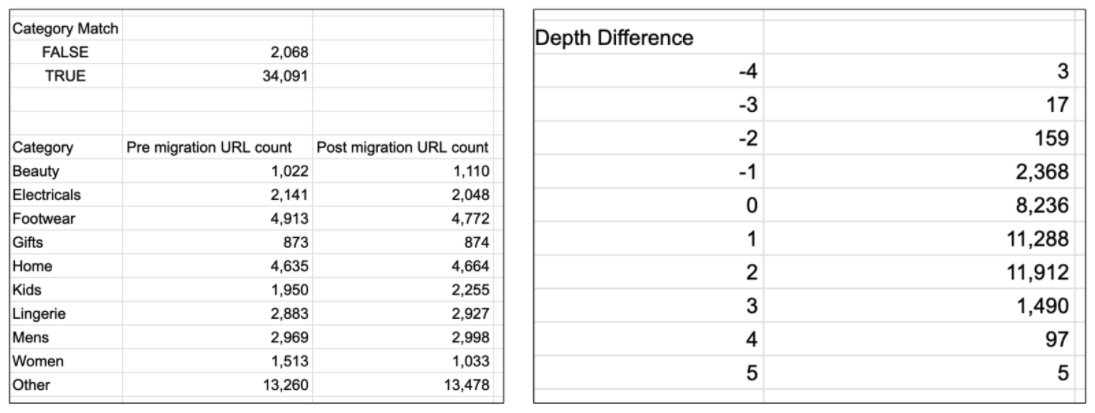
This analysis will enable you to review the redirect rules that have been set and identify if there are any categories with a big difference pre and post-migration which might need further investigation.
4. Internal Link Analysis
Analyzing internal links is important to identify which sections of the site are linked to the most, as well as discover opportunities to improve internal linking across a site.
In order to perform this analysis, we only need some columns of data from a web crawl, for example, any metric displaying links in and links out between pages.
Again, we want to segment this data in order to determine the different categories of a website and analyze the linking between them.
internal_linking_pivot['followed_links_in_count'] = (internal_linking_pivot['followed_links_in_count']).apply('{:.1f}'.format)
internal_linking_pivot['links_in_count'] = (internal_linking_pivot2['links_in_count']).apply('{:.1f}'.format)
internal_linking_pivot['links_out_count'] = (internal_linking_pivot['links_out_count']).apply('{:.1f}'.format)
internal_linking_pivot
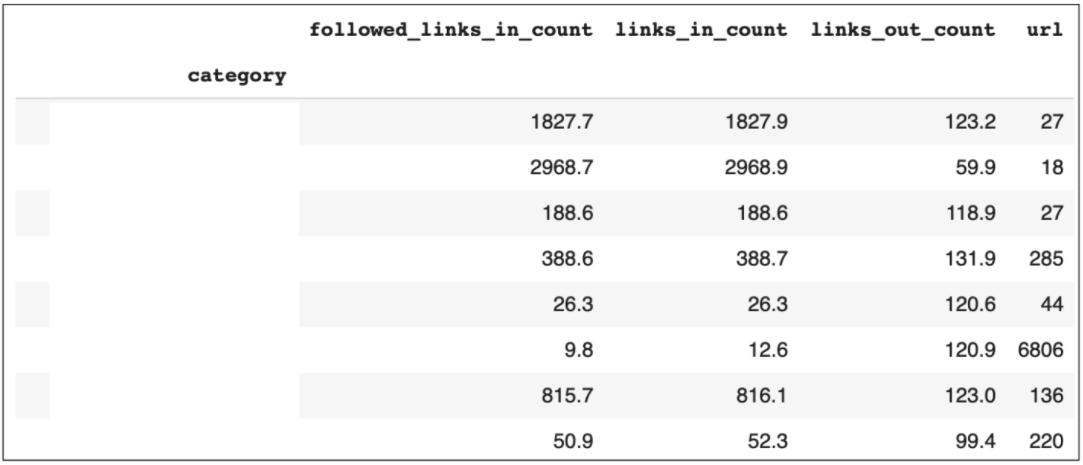
Pivot tables are really useful for this analysis, as we can pivot on the category in order to calculate the total number of internal links for each.
Python also allows us to perform mathematical functions in order to get a count, sum, or mean of any numerical data we have.
5. Log File Analysis
Another important analysis piece is related to log files, and the data we are able to collect for these in a number of different tools.
Some useful insights you can extract include identifying which areas of a site are crawled the most by Googlebot and monitoring any changes to the number of requests over time.
In addition, they can also be used to see how many non-indexable or broken pages are still receiving bot hits in order to address any potential issues with crawl budget.
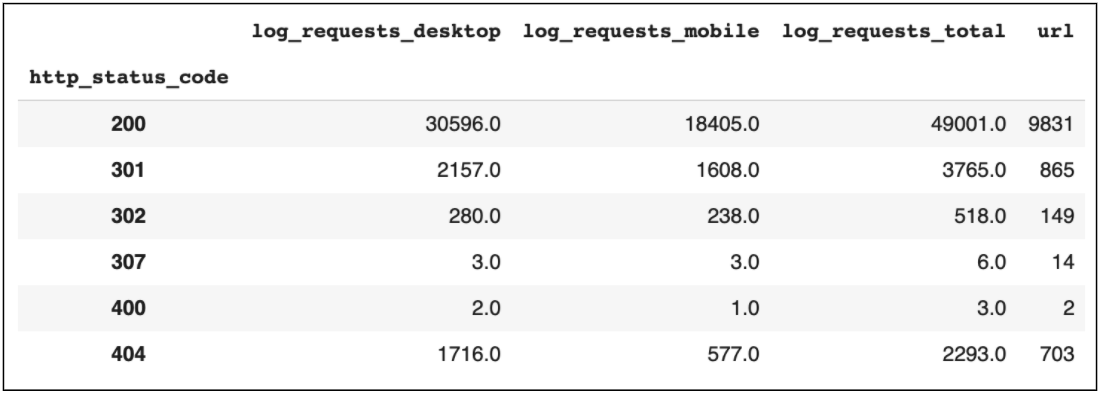
Again, the easiest way to perform this analysis is to segment the URLs based on the category they sit under and use pivot tables to generate a count, or average, for each segment.
If you are able to access historic log file data, there is also the possibility to monitor how Google’s visits to your website have changed over time.
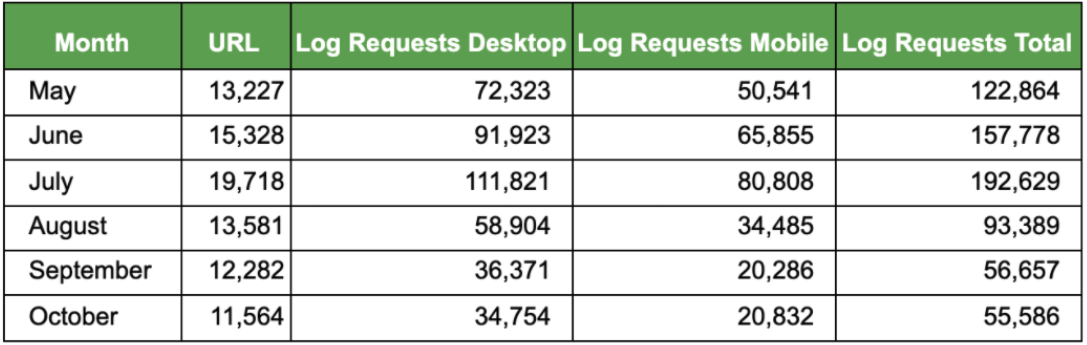
There are also great visualization libraries available within Python, such as Matplotlib and Seaborn, which allow you to create bar charts or line graphs to plot the raw data into easy to follow charts displaying comparisons or trends over time.
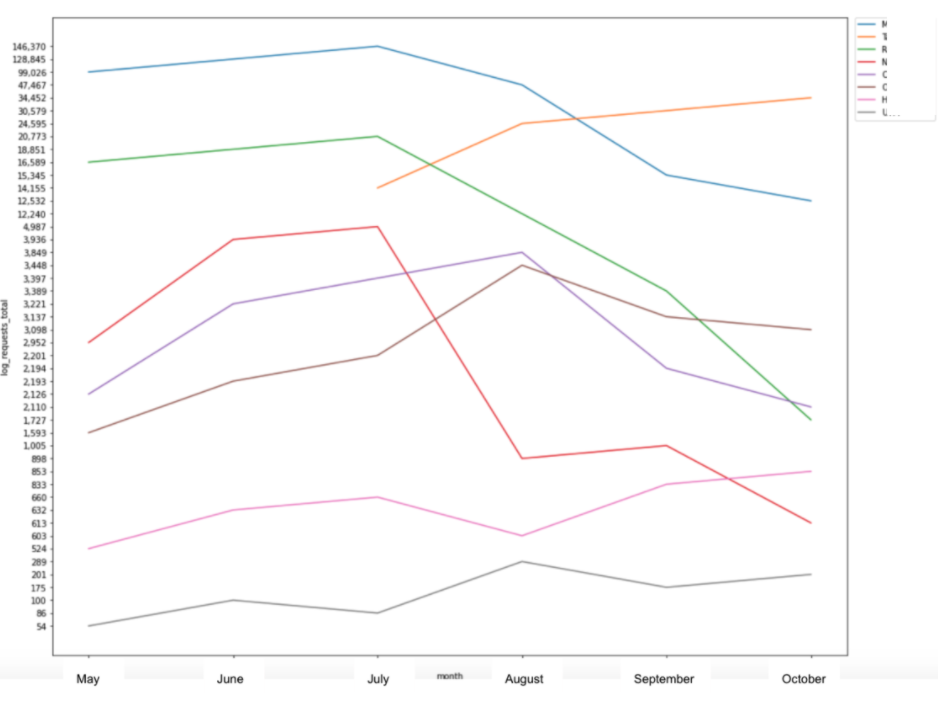
6. Merging Data
With the Pandas library, there is also the ability to combine DataFrames based on a shared column, for example, URL.
Some examples of useful merges for SEO purposes include combining data from a web crawl with conversion data that is collected within Google Analytics.
This will take each URL to match upon and display the data from both sources within one table.
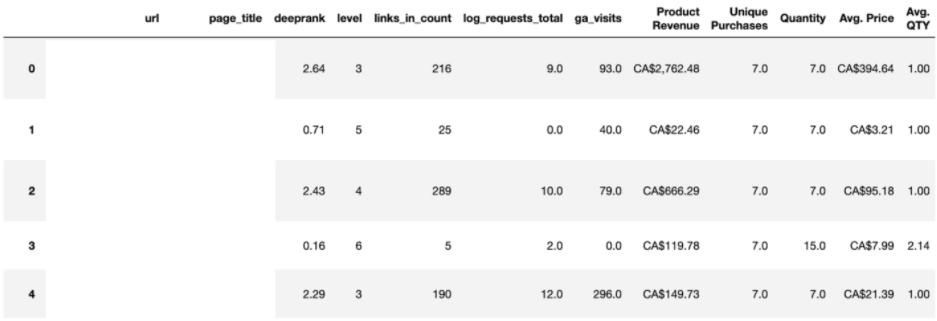
Merging data in this way helps to provide more insights into top-performing pages, while also identifying pages that are not performing as well as you are expecting.
Merge Types
There are a couple of different ways to merge data in Python, the default is an inner merge where the merge will occur on values that exist in both the left and right DataFrames.
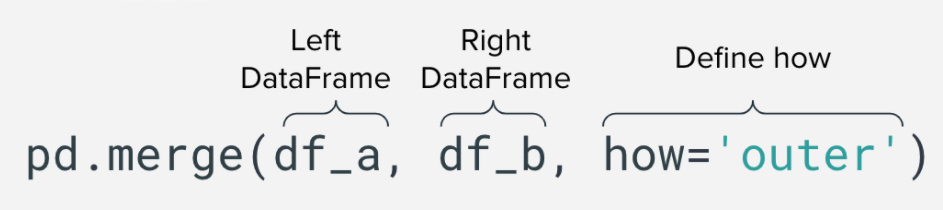
However, you can also perform an outer merge which will return all the rows from the left DataFrame, and all rows from the right DataFrame and match them where possible.
As well as a right merge, or left merge which will merge all matching rows and keep those that don’t match if they are present in either the right or left merge respectively.
7. Google Trends
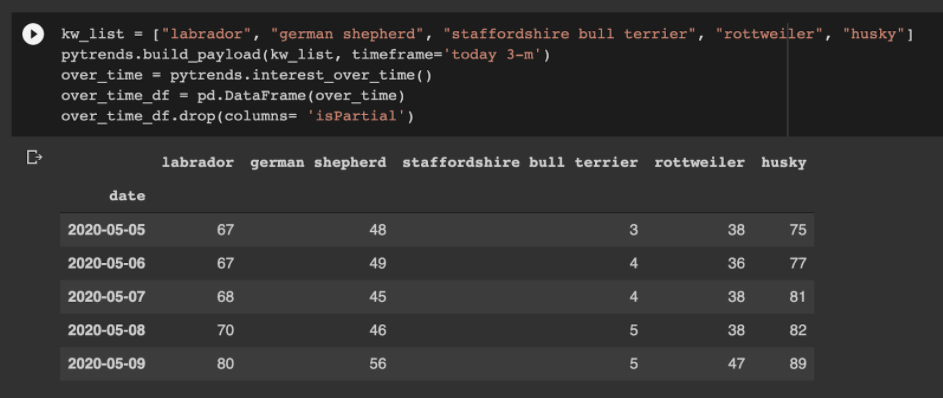
There is also a great library available called PyTrends, which essentially allows you to collect Google Trends data at scale with Python.
There are several API methods available to extract different types of data.
One example is to track search interest over-time for up to 5 keywords at once.
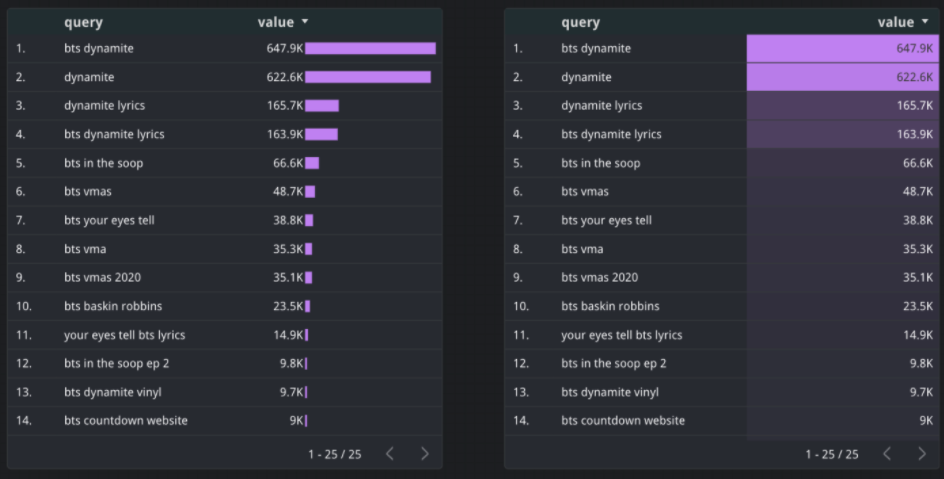
Another useful method is to return related queries for a certain topic, this will display a Google Trends score between 0-100, as well as a percentage showing how much interest the keyword has increased over time.
This data can be easily added to a Google Sheet document in order to display within a Google Data Studio Dashboard.
In Conclusion
These projects have helped me to save a lot of time on manual analysis work, while also allowing me to discover even more insights from all of the data that I have access to.
I hope this has given you some inspiration for SEO projects you can get started with to kickstart your Python learning.
I’d love to hear how you get on if you decide to try any of these and I’ve included all of the above projects within this Github repository.
More Resources:
- How to Predict Content Success with Python
- An Introduction to Natural Language Processing with Python for SEOs
- Advanced Technical SEO: A Complete Guide
Image Credits
All screenshots taken by author, December 2020
