

In 2006, Google patented a Browseable Fact Repository, which was an early version of what would develop into Google’s Knowledge Graph.
It was a collection of facts related to entities, with identification numbers associated with those entities.
This knowledge base was built by the Google Annotation Framework team headed by Andrew Hogue at Google.
He was also responsible for managing the acquisition of MetaWeb, and the knowledge base Freebase that came with MetaWeb. That acquisition took place in July of 2010.
Google has published a new patent application on July 16, 2020, for what appears to be a similar knowledge base, referred to as a personalized entity repository.
This patent includes many more details and more information than the one on the Browseable Fact Repository.
A lot has happened in how Google crawls facts and uses entity information since 2006. They have matured in how they are building their knowledge graph and the knowledge bases behind it.
Last year, I wrote a post called Entity Extractions for Knowledge Graphs at Google which tackled how Google is working toward extracting entity information from webpages and triples of information about those entities in a Subject-Verb-Object format that is:
- About how one entity might be related to another entity (Bryce Harper Plays baseball for the Philadelphia Phillies).
- About attributes of entities (Bryce Harper was born October 16, 1992).
- Or about classifications of Entities (Bryce Harper is an American Professional Baseball Player).
Google has been using knowledge base sources such as Freebase and Wikipedia to identify entities, attributes of entities, and classifications for entities.
However, the search engine appears to be interested in collecting that kind of information from other sources on the web, other than just knowledge bases that are human-edited resources.
This is to possibly use sources that scale on a web-sized basis.
In addition to broadening the sources of information that Google collects to more than just knowledge bases, Google introduced the idea that they could create mini-knowledge graphs to answer specific queries, which I wrote about in Answering Questions Using Knowledge Graphs.
In addition to building mini-knowledge graphs for individual queries, another patent I wrote about told us that Google might create mini-knowledge graphs that were user-specific.
At the end of 2019, I wrote a post called User-Specific Knowledge Graphs to Support Queries and Predictions about a patent named Structured user graph to support querying and predictions.
This patent told us that while several user-specific knowledge graphs could be created, they could be bundled together (without user identifiable information into a universal knowledge graph.
A Google white paper was published in October 2019 on a similar topic, titled Personal Knowledge Graphs: A Research Agenda.
That has been an interesting evolution behind knowledge graphs.
This summer, a patent application was published that also describes collecting more personal information from searchers that reminded me of that early fact repository.
Additionally, it describes a knowledge base that could be the collection of information behind Google’s Knowledge Graph.
Personalized Predictions & Assistance Using A Personalized Entity Repository
By understanding the content viewed by and actions taken by a user, the mobile device can build a much better user experience (e.g., offering personalized predictions and assistance to the user).
That is what we are told is the purpose behind this patent.
Part of that understanding of the content and actions involves identifying and classifying entities recognized in the content of the device screen.
Those entities may exist in an entity repository, such as a knowledge base or vision model, which stores facts and information about entities.
We are told that large, public entity repositories may include millions of such entities.
Most computing devices, especially mobile computing devices like smartphones and tablets, have limited storage and would use the entity repository via a connection with a server.
Advantages of Using a Personalized Entity Repository
The patent tells us that these are the advantages of following the process in the patent.
- Generating fixed sets of entities enables the system to provide personal or custom entity repositories in a scalable way.
- The customized entity repository can aid with on-device text analysis and image analysis to support user assistance capabilities even without connectivity to a network.
- The user may control the resources dedicated to the personal entity repository and the system may automatically determine which sets best utilize the allocated resources.
- The system may predict which sets are most relevant to a user, based on several factors specific to the user and/or the personal computing device, such as location, time of day, signals from other computing devices associated with the user or known to the device, recent activity on the computing device, etc.
- Implementations may support versioning of the sets so that a change that restructures the information in the set does not break applications that use the set.
How a Personalized Entity Repository Is Constructed
An entity repository is broken into several fixed sets or slices.
These sets that are:
- Location-based
- Topic-based
- Action-based
- Functional
We see those entity sets in a flowchart from the patent:
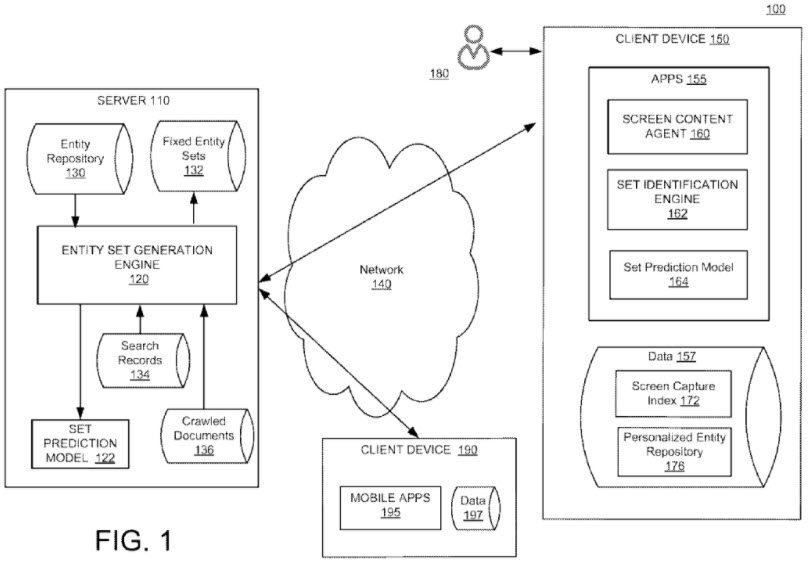
The system may determine the sets at a server and provide only those sets to a client device that are relevant to that client.
The sets downloaded to the client are a personalized entity repository that can be accessed without connecting to the server.
The client device may include a set identification engine.
The set identification engine may include a prediction model that predicts one or more sets given some text, images, or other features.
The prediction model may be used to determine which sets are most beneficial to the user.
The set identification engine may also track the location of the user to determine which location sets may be most relevant.
Sets may be ranked for the user of the client device based on several contexts (e.g., based on the user’s location, a user’s search history, content the user has been viewing on the device, time of day, signals from other devices, etc.)
Examples of the Use of a Personalized Entity Repository
The post I linked to about a User-Specific Knowledge Graph provides some examples of what might be seen in a personalized knowledge repository.
This patent provides a couple of examples, but not in much detail.
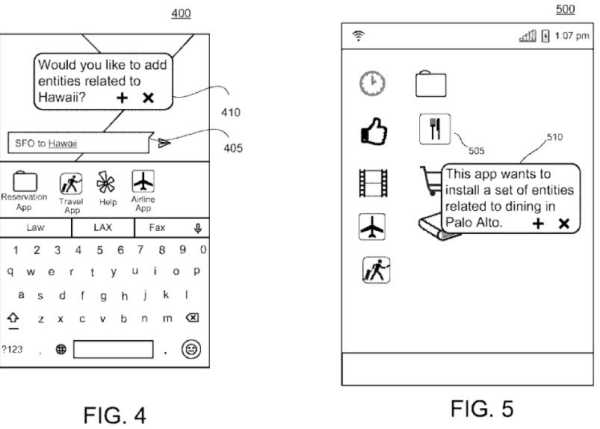
A Trip to Hawaii
If someone is researching a trip to Hawaii, the system may determine that a set with entities related to Hawaii is particularly relevant to the user.
This Drawing from the patent shows information about entities from Hawaii being shown to a searcher:
A Flight from NYC to LA
If a user flies from New York to Los Angeles, the system may determine location sets for Los Angeles are relevant.
Providing Information About a Movie
The drawings from the patent provide this example of when an entity might be identified from a personalized entity repository:

The client device may use the rankings to determine which sets to retrieve and which to delete from memory.
If a set previously downloaded is no longer relevant, the system may remove that set to make room for another set.
The system may employ set usage parameters to determine which sets to include in the personalized entity repository at any time.
The user may establish and control the set usage parameters.
Updating a set can include determining a delta for the set to reduce the data transferred to the client device.
In some implementations, the sets may be versioned (e.g., so that a schema change does not break the applications using the model.)
Using a Personalized Entity Repository can include:
- Identifying fixed sets of the entity repository relevant to a mobile device user based on context associated with the mobile device.
- Ranking those fixed sets by relevancy.
- Determining selected sets from the identified fixed sets using the rank and set usage parameters applicable to the user.
- Updating the personalized entity repository using the selected sets.
The Personalized Entity Repository patent can be found at:
Personalized Entity Repository
Inventors Matthew Sharifi, Jorge Pereira, Dominik Roblek, 0Julian Odell, Cong Li, David Petrou
Applicants Google LLC
Patent application number: 20200226187
Published Date July 16, 2020
Filed Date: July 1, 2019
Abstract
Systems and methods are provided for a personalized entity repository. For example, a computing device comprises a personalized entity repository having fixed sets of entities from an entity repository stored at a server, a processor, and memory storing instructions that cause the computing device to identify fixed sets of entities that are relevant to a user based on context associated with the computing device, rank the fixed sets by relevancy, and update the personalized entity repository using selected sets determined based on the rank and on set usage parameters applicable to the user. In another example, a method includes generating fixed sets of entities from an entity repository, including location-based sets and topic-based sets, and providing a subset of the fixed sets to a client, the client requesting the subset based on the client’s location and on items identified in content generated for display on the client.
What Is A Personal Entity Repository System?
A Personalized Entity Repository System is built from selections of pre-computed or fixed sets of entities.
The repository gets built up over time as a person uses a mobile device.
If someone searchers for information on a trip to Hawaii, the repository may fill up with information about entities from Hawaii.
This information can come from things such as:
- The user’s location.
- A user’s search history.
- Content the user has been viewing on the device.
- Time of day.
- Signals from other devices.
- Etc.
Information from the personalized entity repository may be updated over time:
- Determining which sets are most useful, and updating the repository to ensure entities are relevant to the user.
- Deleting sets less relevant to the user and adding new sets that have become relevant.
- Determining entities in content generated for display on a computing device to personalize a user experience on the computing device.
This system can personalize the user experience by predicting actions, topics, words, or phrases, etc.
This entity repository is a knowledge base that stores information about entities in the form of relationships between entities (those relationships are the “knowledge” in this knowledge base.)
In addition to storing relationship information, the knowledge base also stores attributes about the entities it contains.
This was an interesting statement from the patent:
The entity repository may also include image recognition entities that can be used to identify an entity in an image.
The entity repository may represent:
- A single knowledge base.
- A combination of distinct knowledge bases.
- Image recognition entities.
- And/or a combination of a knowledge base and image information.
We are told that the entities and relationships in this entity repository may be searchable, e.g., via an index.
The index may include text by which an entity has been referred to, so a reference to the knowledge base includes an index allowing an entity to be found using a text equivalent.
The personalized entity repository may be broken into sets or slices.
I mentioned above that these sets may be organized this way:
- Location-based
- Topic-based
- Action-based
- Functional
Information about these entities may be collected in clusters related to what type of set they may be.
Entities can be clustered by topics if they are topic-based clusters, or by location, if they are location-based clusters.
Location-based clusters are geo-based like you might see in Google Maps.
Functional Entity Sets may include entities that are deemed most popular (e.g., entities that are most frequently searched for or accessed, for example, based on appearance in search queries.)
A functional set may also be based on something like the capability to translate from one language to another, or entities that are likely to be encountered when using or requested by a particular application.
Personalized Entity Repository Takeaways
I have provided an extended summary of this patent.
There are parts of it I did not cover, which include things like how machine learning might be used with this system, and a lot about the different types of sets of entities the might be included in the repository or how those might be clustered together.
That is interesting content, but I covered the User Specific Knowledge Base patent in a fair amount of detail which is linked to above, and that may be worth spending more time on than this information about how entities might be organized in a knowledge base.
I do think it is helpful to know that Google may make the knowledge graph you see one that is more personalized and one that can work quickly when using smaller mobile devices.
This means that you can carry around a device that contains parts of a knowledge graph on your device that might best fit your search history or things that you may have read recently, or is related to places where you have been recently.
This fits the kind of thing that you may benefit from if you own an android device, and Google is using federated machine learning on your device.
Under that approach, information is uploaded to the cloud at the end of a day and downloaded to a device at the start of the next day. This could be one way that personalized entity repositories get updated.
I wrote a post about a related patent that extracts entities from a set of search results, builds a knowledge graph from those SERPs, and created a set of ranked entities from that knowledge graph in the post: Ranked Entities in Search Results at Google.
More Resources:
- How to Get Your Brand in Google’s Knowledge Graph Without a Wikipedia Page
- Google Search 101: How the Knowledge Graph Works
- How to Maximize Your Reach Using Google’s Knowledge Graph
Image Credits
All screenshots taken by author, August 2020
