

Here is a common and interesting duplicate content problem.
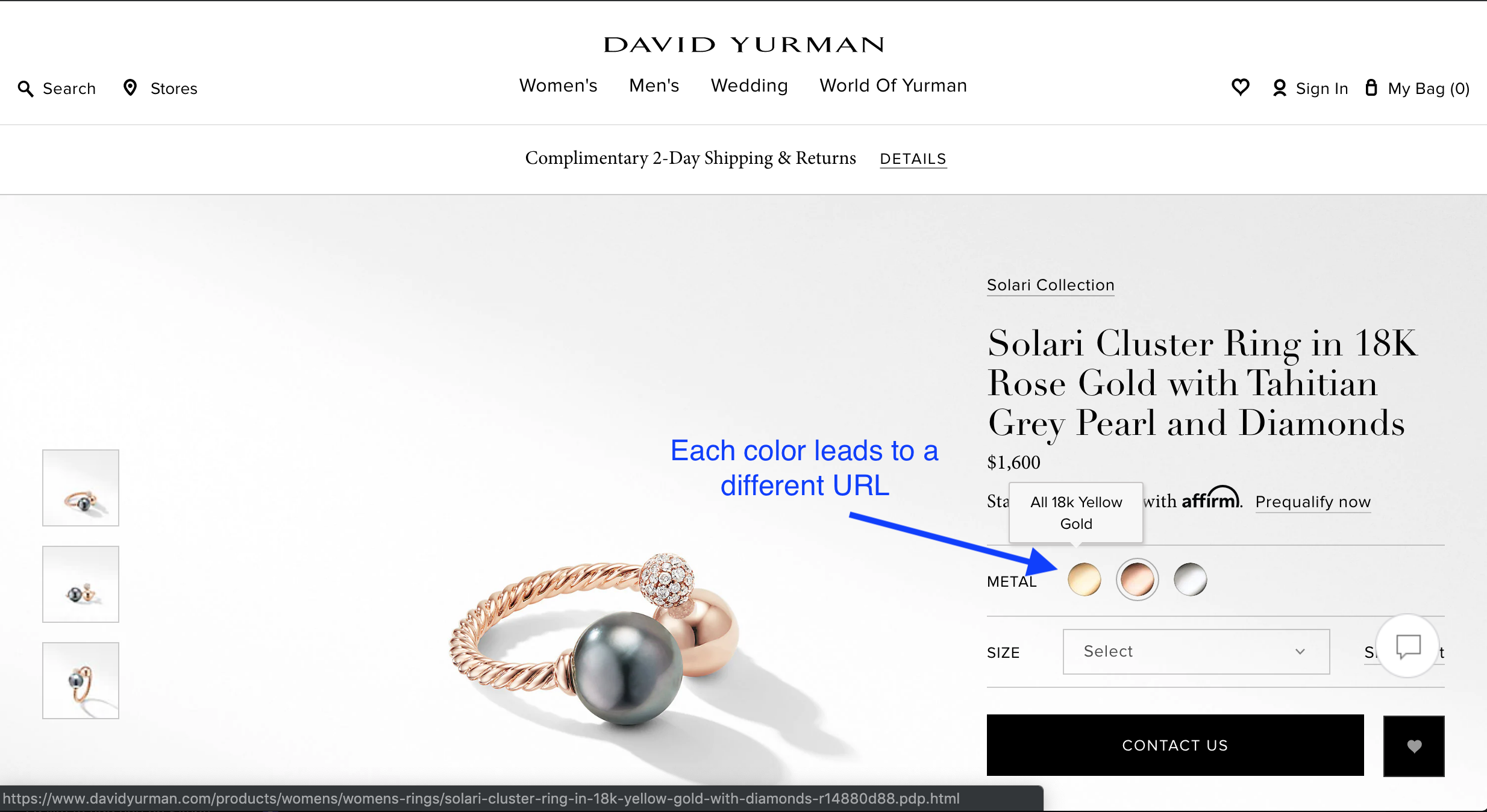
You have a retailer like David Yurman with products available in different color variations and chooses to display each product color on its own URL.
Each product/color URL would typically have the same content but change the main product image, which is not enough of a difference to set them apart.
Should you canonicalize all product variants to one and consolidate duplicate content?
Or should you rewrite the product name, description, etc. to keep each version separate and unique?
When you consolidate pages with mostly the same content, you generally end up with higher performance. This illustration from Google shows why.
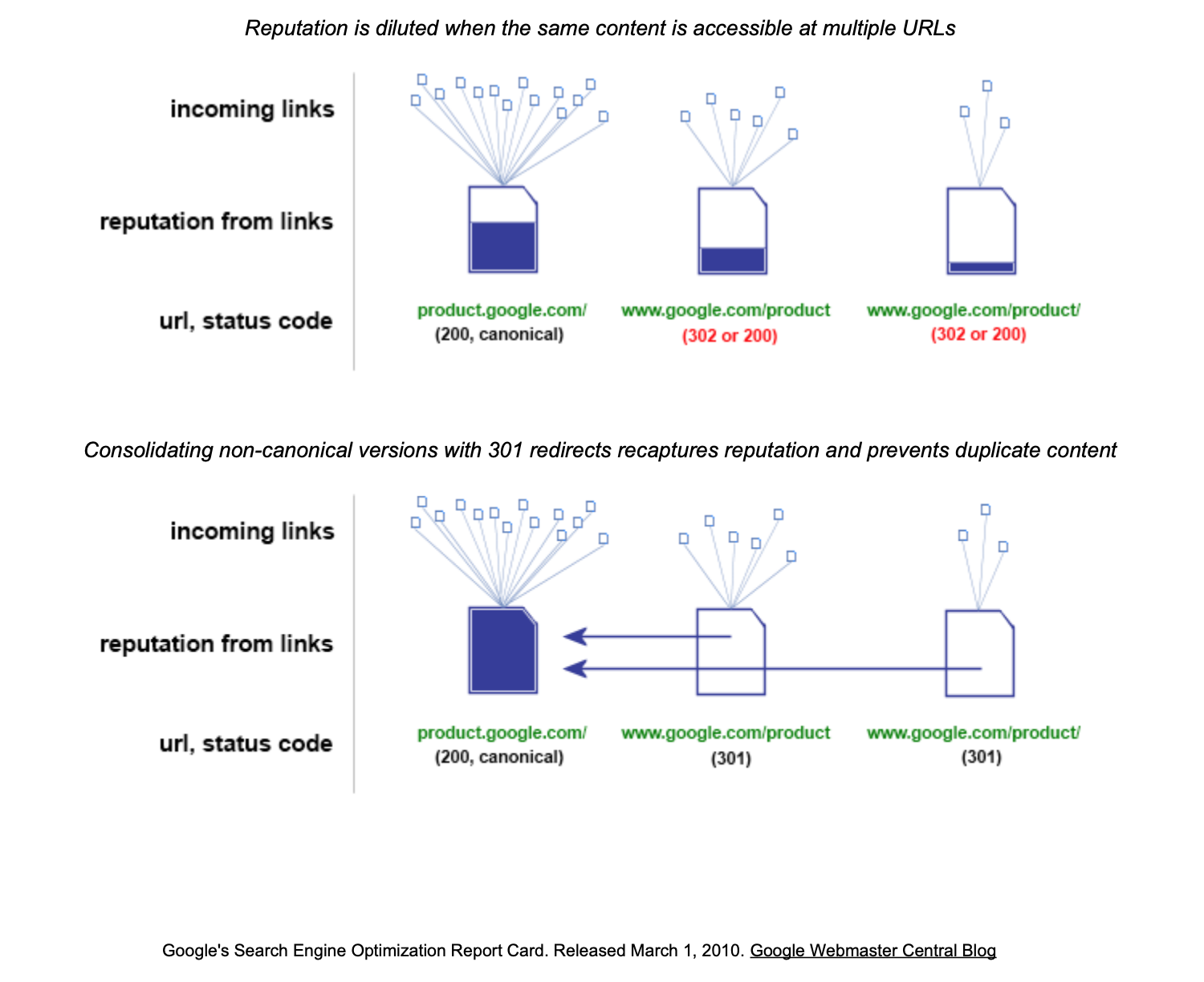
You are indirectly building links to the canonical pages.
When you have pages with mostly the same content, they compete in the SERPs for the same terms and most of them would get filtered at query time. Each one of the pages filtered accumulates links that go to waste.
However, here is an interesting case. What if people specifically search for content only available in some of the pages?
In this case, it would not be wise to consolidate those because we would lose the relevant rankings.
Let’s bring this home with a concrete example using SEMrush.
David Yurman has products in at least six main colors: sterling silver, black titanium, rose gold, yellow gold, white gold, and green emerald.
It is possible that there are color specific searches in Google that lead to product pages. If that is the case, we don’t want to consolidate those pages so they can capture the relevant color specific search traffic.
Here is an example SEMrush search that can help us check if that is the case.
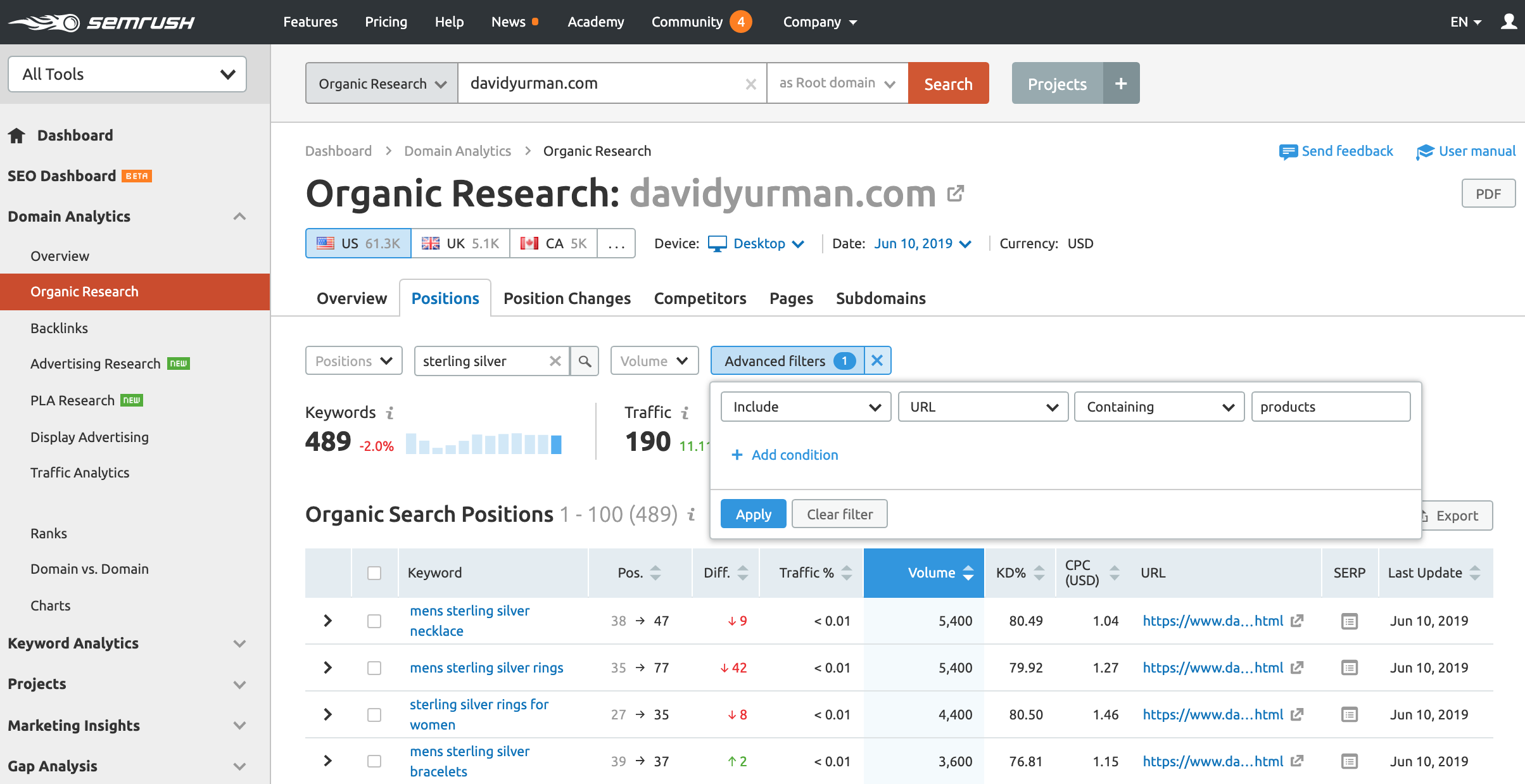
For example, we have 489 organic keyword rankings for sterling silver, 863 for rose gold, and just 51 for black titanium.
I also checked using mobile as a device and got 30 for sterling silver, 77 for rose gold, and only 11 for black titanium.
Most sites would either keep color URLs separate like David Yurman or consolidate colors into one page at the URL level or using canonicals.
At least, from an SEO performance perspective, it doesn’t seem like keeping black titanium as separate URLs is a particularly good choice given the low number of searches.
But, what if we could find an ideal middle ground?
What if we could consolidate some product URLs and not others?
What if we could perform these decisions based on performance data?
That is what we are going to learn how to do in this article!
Here is our plan of action:
- We will use OnCrawl’s crawler to collect all the product pages and their SEO meta data (including canonicals).
- We will use SEMrush to gather color specific search terms and corresponding product pages.
- We will define a simple clustering algorithm to group (or not group) products depending on whether they have color searches.
- We will use Tableau to visualize the clustering changes and understand the changes better.
- We will upload our experimental changes to the Cloudflare CDN using the RankSense app.
1. Getting Product Page Groups Using OnCrawl
I started a website crawl using the main site URL: https://www.davidyurman.com.
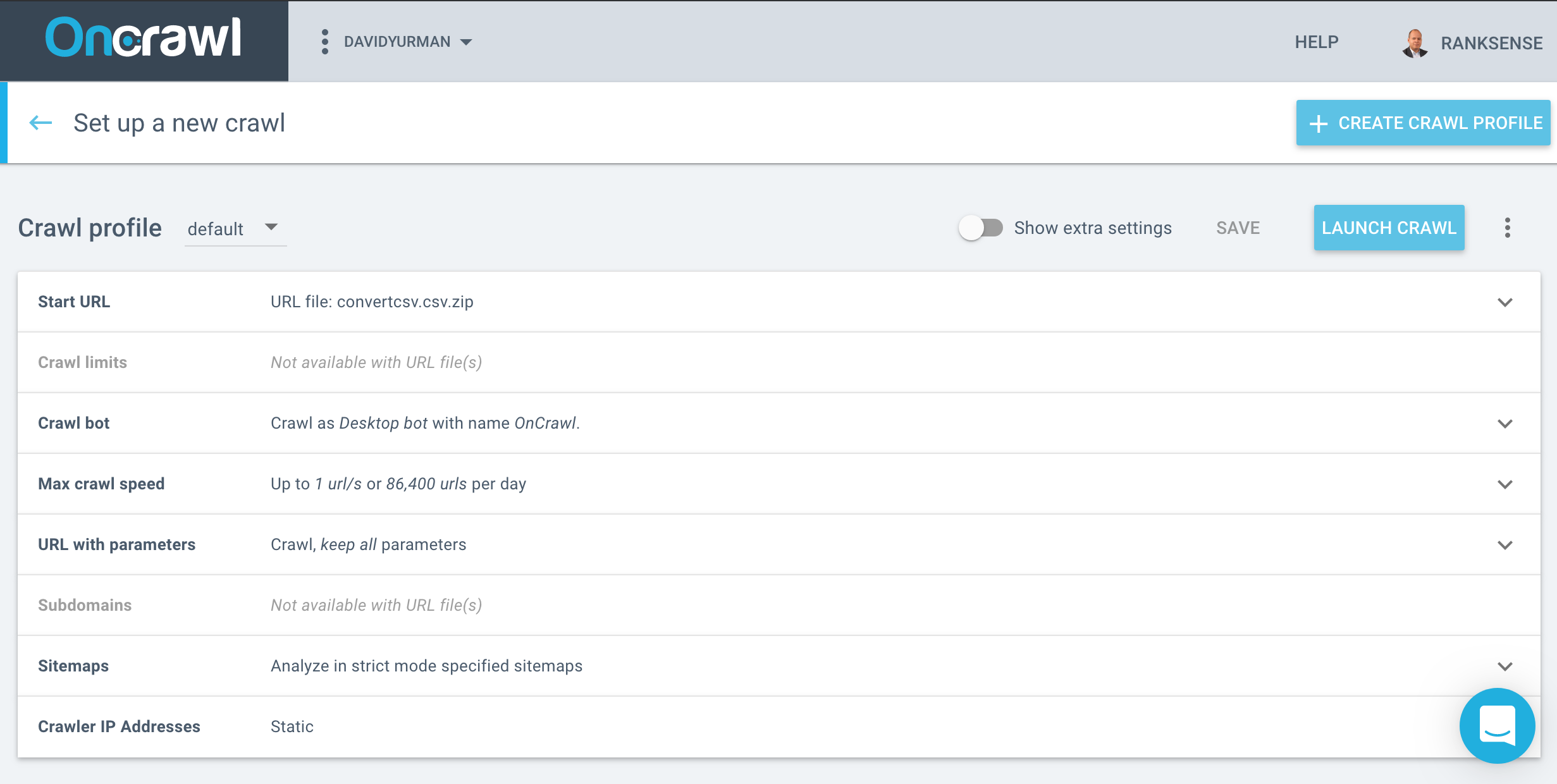
As I am only interested in reviewing U.S. products, I downloaded the US products XML sitemap, converted it to a CSV file, and uploaded it as a zip file.
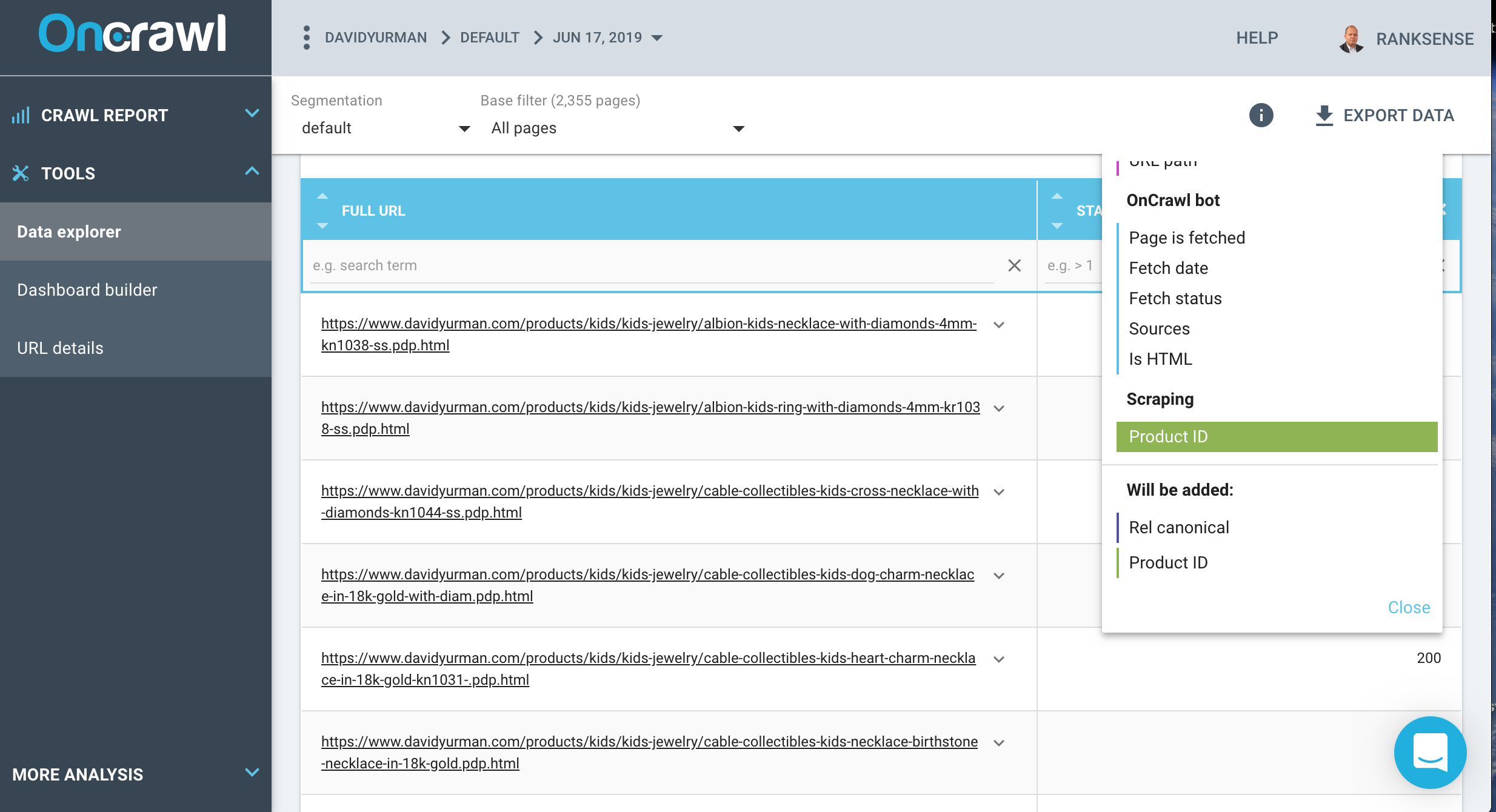
I added the existing rel=canonical as a column and exported the list of 2,465 URLs.
2. Getting Color Search Queries to Product Pages Using SEMrush
I put together an initial list of colors: sterling silver, black titanium, rose gold, yellow gold, white gold, green emerald. Then exported six product lists from SEMrush.
3. Clustering Product URLs by Product Identifier
We are going to use Google Colab and some Python scripting to do our clustering.
First, let’s import the OnCrawl export file.
Then, we can also import the SEMrush files with the color searches.
I tried a couple of ideas to extract the product ID from the URLs, including using OnCrawl’s content extraction feature, but settled on this one that extracts it from the URL.
Next, this is how we can add the product ID column to our Dataframe and group the URLs to perform the clustering.
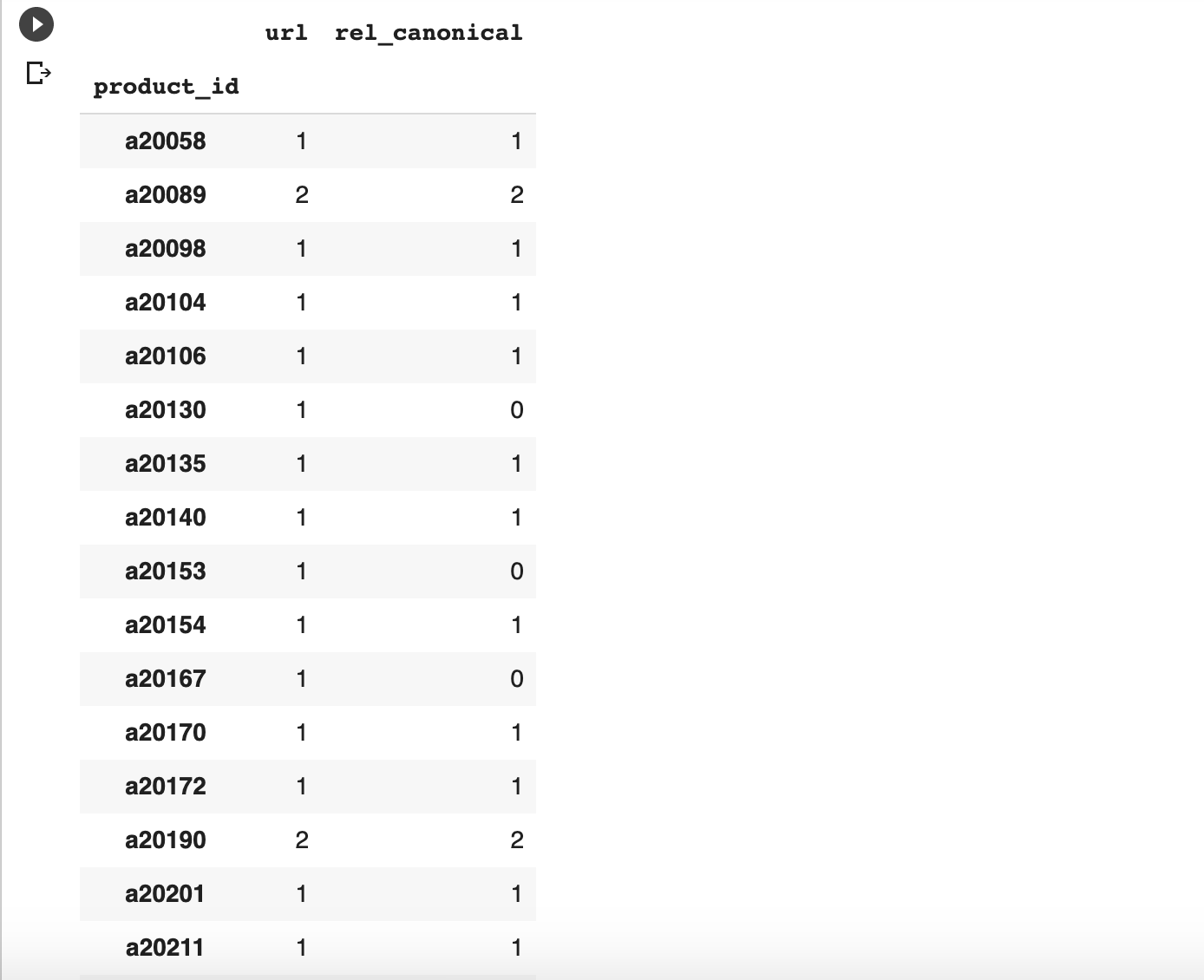
In this clustering exercise, you can see some product IDs with no canonicals. We are going to fix that by adding self-referential canonicals to those URLs.
Let’s export the data frame to a CSV file and import into Tableau for further analysis. In Tableau, we can visualize the current canonical clusters better.
In Tableau, complete these steps:
- Connect to the CSV file using the Text file data source.
- Convert URLs and Canonicals to Measures by dragging them to that section.
- Drag the Product ID to the Rows.
- Drag the Canonicals and URL counts to the columns.
- Right click on the null URLs row, and select the option to exclude it.
- Change the chart type to Treemap.
- Add a calculated field named “Canonicalized” and paste this formula.
IF COUNTD([URL]) - COUNTD([Rel Canonical]) == 0 Then "Self Referential" ELSE "Canonicalized" END
- Drag the calculated field to the Color mark.
- Drag the URL count to the filters and specify a minimum of two URLs.
- Drag the count URLs and count canonicals to details mark.
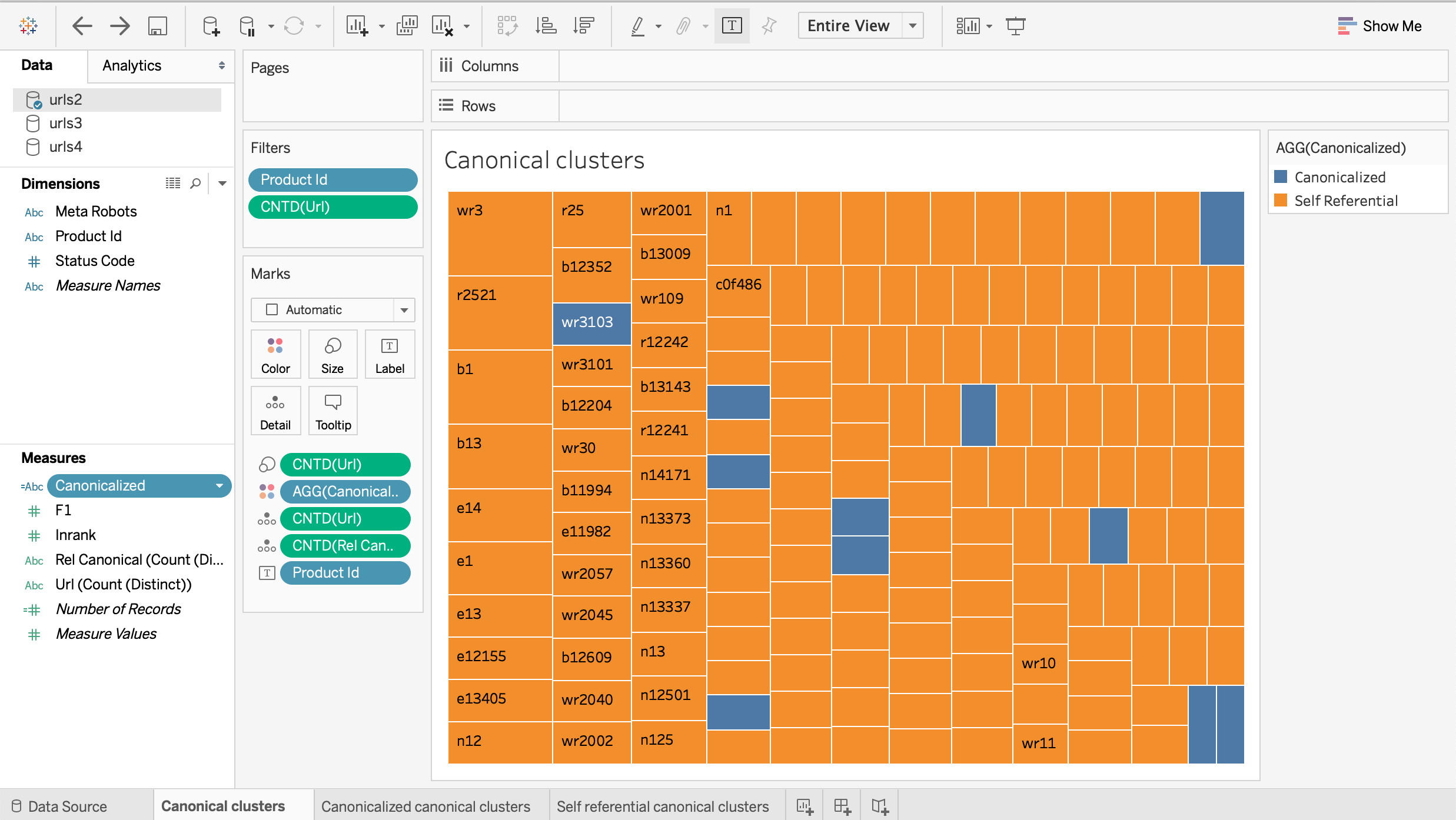
This is what the setup looks like.
Each square represents a product ID cluster. The bigger ones have more URLs. The calculated field “canonicalized” uses colors to tell if a cluster is canonicalized or self-referential.
We can see that in its current setup, the David Yurman products are mostly self-referential with very few clusters canonicalized (blue squares).
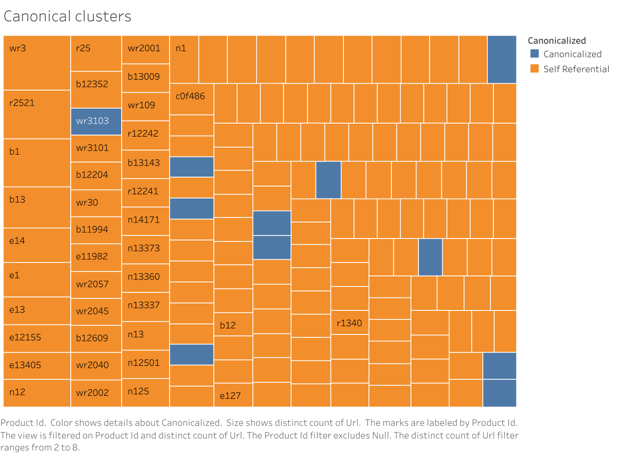
Here is a closer look.
This would be a good setup if most products received search traffic from color specific product searches. Let’s see if that is the case next.
4. Turning Canonical Clusters to Canonicalized
We are going to perform an intermediate step and force all product groups to canonicalize to the first URL in the group.
This is good enough to illustrate the concept, but for production use, we would want to canonicalize to the most popular URL in the group. It could be the most linked page or the one with the most search clicks or impressions.
After we update our clusters, we can go back to Tableau, repeat the same steps as before and review the updated visualization.

You can see that none of the clusters are self-referential now as should be the case because we force them not to be so. All of them canonicalize to only one URL.
5. Turning Some Canonical Clusters to Self-Referential
Now, in this final step, we will learn how many clusters should be self-referential.
As all groups canonicalize to one URL now, we only need to break those cluster where URLs have search traffic for color terms. We will change the canonicals to be self-referential.
First, let’s import all the SEMrush files we exported into a dataframe, and convert the URLs into a set for easy checking.
The next step is to update the canonicals only for the groups that match.
After this process, we can go back to Tableau and review our final clusters.
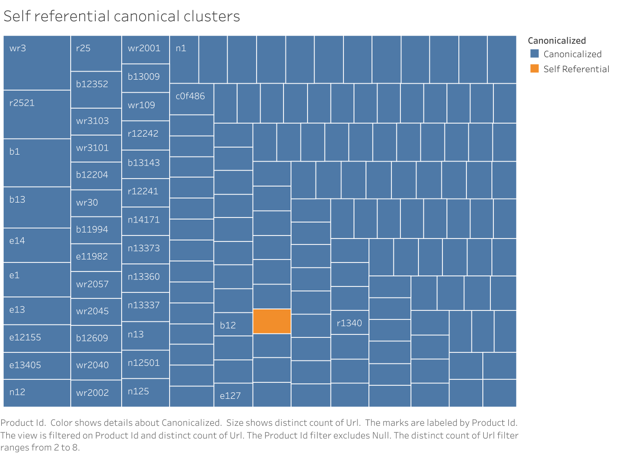
Surprisingly, we only have one cluster that we need to update, which means that David Yurman is leaving a lot of money on the table with their current setup that relies on self-referential canonicals.
6. Implementing Experimental Changes in Cloudflare with RankSense
Performing selective and experimental changes like this one on a traditional CMS might not be practical, require serious dev work or would be a hard sell without evidence this would work.
Fortunately, these are the types of changes that are easy to deploy in Cloudflare using our app and without writing backend code. (Disclosure: I work for RankSense.)
We will copy our proposed canonical clusters to a Google Sheet. Here is an example:
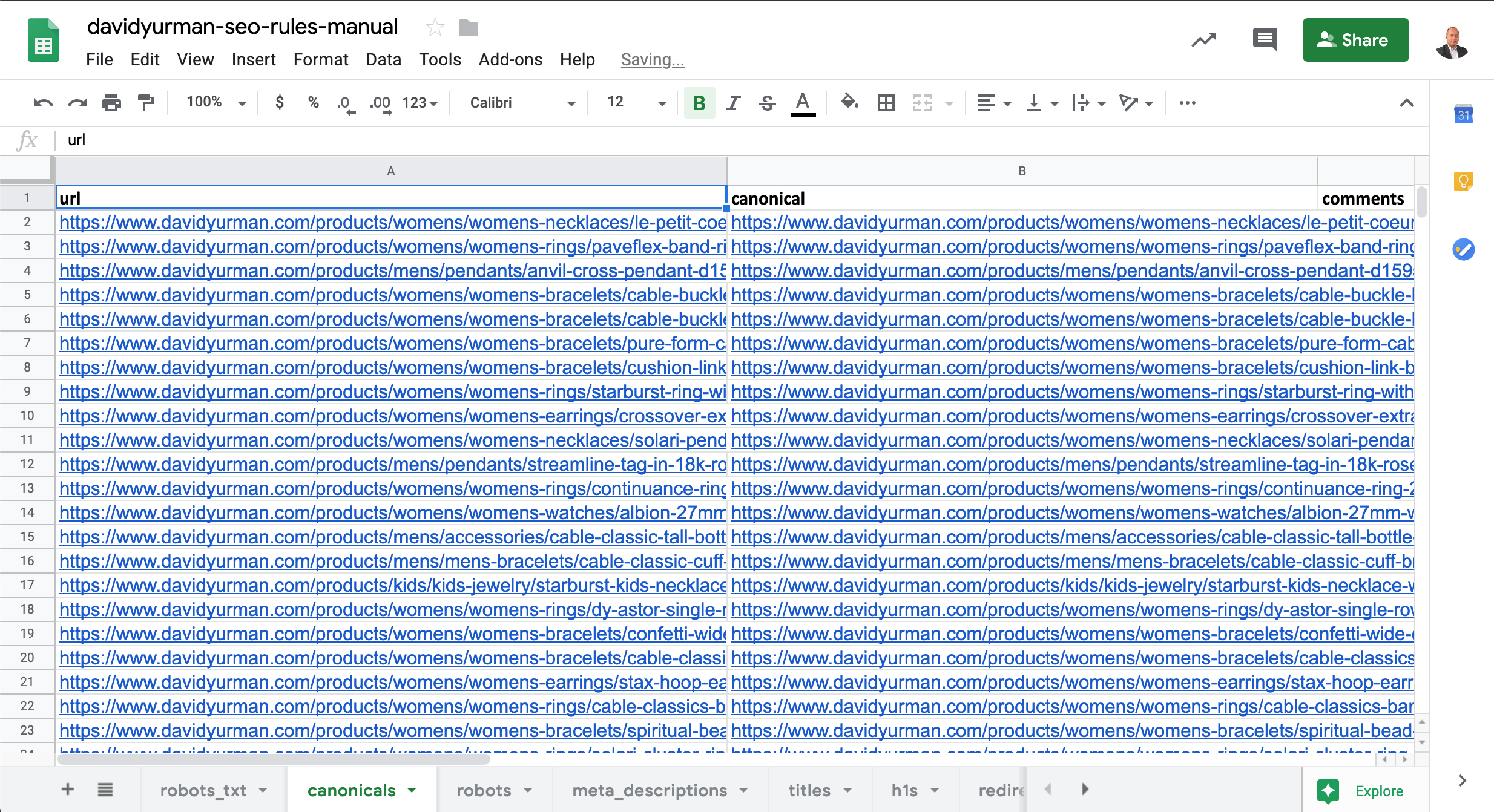
Assuming David Yurman used Cloudflare and had our implementation app installed, we could simply upload the sheet, add some tags to track performance and submit it to get the changes to staging preview or production.
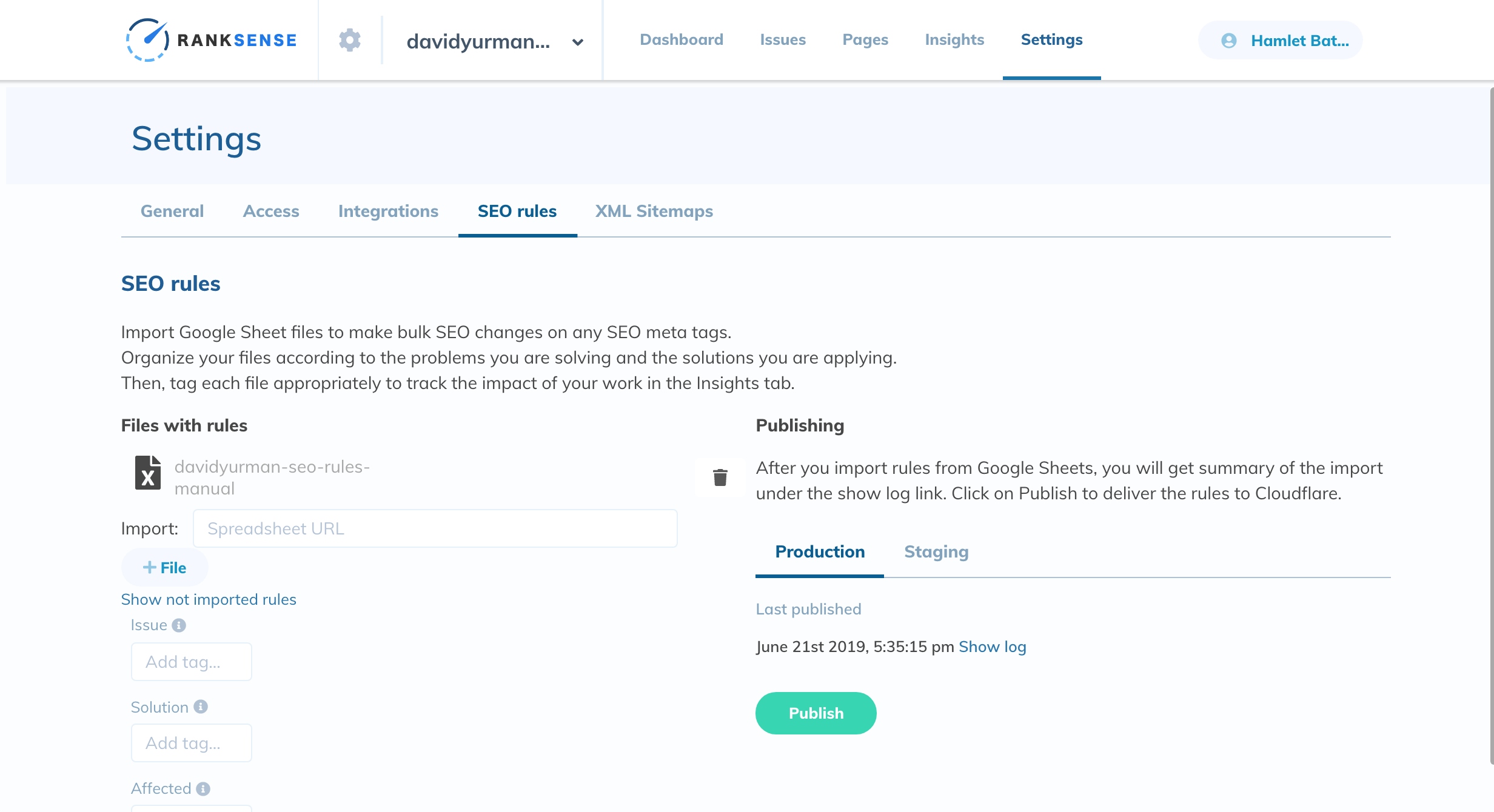
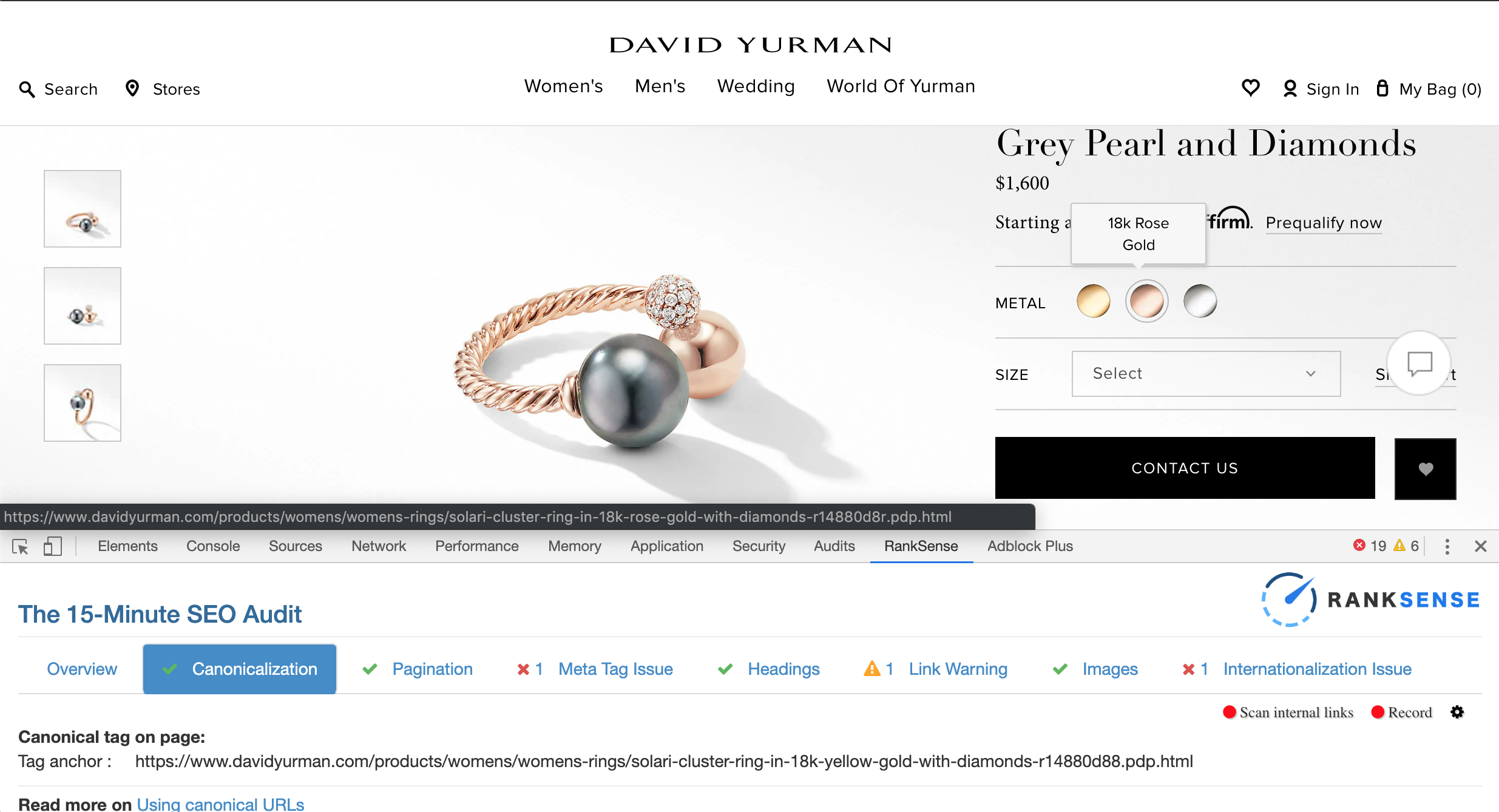
Finally, we could manually review the canonicals are working as expected using our 15 Minute Audit Chrome extension, but to be sure, we should run another OnCrawl crawl to make sure all changes are in place.
I spotted duplicate meta descriptions and I’m sure they have more SEO problems to address.
If this idea proves to work well for them, they can confidently proceed to commission the dev work to get this implemented on their site.
Resources to Learn More
It is really exciting to see the Python SEO community growing so quickly in the last few months. Even Google’s John Mueller is starting to notice.
Future: John is seeing more smart SEOs out there.
– SEO & coding together again
– Fewer magic spells, more knowledge
– Listen & learn from peers, then try it out
– Some of the best are speaking here at MN Search Summit— Mark Traphagen (@marktraphagen) June 21, 2019
Some people in the community have been doing some incredible work.
For example, JR Oakes shared the results of a content generation project he has been working on for two years!
Some results I just shared with @hamletbatista after training a LM model on Google results for “Technical SEO”. He has been the one #SEO to really push me to go harder and I really value his friendship. #VeryHappy pic.twitter.com/4Jv4IswirM
— JR%20Oakes 🍺 (@jroakes) June 21, 2019
Alessio built a cool script that generates an interactive visualization of “people also asked” questions.
Overall, while it is nice to receive praise for my work like the ones below, I get far more excited about the growing body of work the whole community is building.
We are growing stronger and more credible each day!
Love, love, love the #ML content @hamletbatista keeps sharing with the #seo community through @sejournal 🙌 Another great primer 👉 Automated Intent Classification Using Deep Learning https://t.co/w0c2i8UVM9
— MichelleRobbins (@MichelleRobbins) June 20, 2019
Potentially the smartest SEO post of 2019 so far -> Automated Intent Classification Using Deep Learning https://t.co/bRgMqekdZX via @hamletbatista, @sejournal
— chriscountey (@chriscountey) June 21, 2019
More Resources:
- Google Advice: Duplicate Content on Product & Category Pages
- What Are SEO Best Practices for Color Variations?
- Advanced Technical SEO: A Complete Guide
Image Credits
All screenshots taken by author, July 2019
