



Crawl budget is a vital SEO concept for large websites with millions of pages or medium-sized websites with a few thousand pages that change daily.
An example of a website with millions of pages would be eBay.com, and websites with tens of thousands of pages that update frequently would be user reviews and rating websites similar to Gamespot.com.
There are so many tasks and issues an SEO expert has to consider that crawling is often put on the back burner.
But crawl budget can and should be optimized.
In this article, you will learn:
- How to improve your crawl budget along the way.
- Go over the changes to crawl budget as a concept in the last couple of years.
(Note: If you have a website with just a few hundred pages, and pages are not indexed, we recommend reading our article on common issues causing indexing problems, as it is certainly not because of crawl budget.)
What Is Crawl Budget?
Crawl budget refers to the number of pages that search engine crawlers (i.e., spiders and bots) visit within a certain timeframe.
There are certain considerations that go into crawl budget, such as a tentative balance between Googlebot’s attempts to not overload your server and Google’s overall desire to crawl your domain.
Crawl budget optimization is a series of steps you can take to increase efficiency and the rate at which search engines’ bots visit your pages.
Why Is Crawl Budget Optimization Important?
Crawling is the first step to appearing in search. Without being crawled, new pages and page updates won’t be added to search engine indexes.
The more often that crawlers visit your pages, the quicker updates and new pages appear in the index. Consequently, your optimization efforts will take less time to take hold and start affecting your rankings.
Google’s index contains hundreds of billions of pages and is growing each day. It costs search engines to crawl each URL, and with the growing number of websites, they want to reduce computational and storage costs by reducing the crawl rate and indexation of URLs.
There is also a growing urgency to reduce carbon emissions for climate change, and Google has a long-term strategy to improve sustainability and reduce carbon emissions.
These priorities could make it difficult for websites to be crawled effectively in the future. While crawl budget isn’t something you need to worry about with small websites with a few hundred pages, resource management becomes an important issue for massive websites. Optimizing crawl budget means having Google crawl your website by spending as few resources as possible.
So, let’s discuss how you can optimize your crawl budget in today’s world.
1. Disallow Crawling Of Action URLs In Robots.Txt
You may be surprised, but Google has confirmed that disallowing URLs will not affect your crawl budget. This means Google will still crawl your website at the same rate. So why do we discuss it here?
Well, if you disallow URLs that are not important, you basically tell Google to crawl useful parts of your website at a higher rate.
For example, if your website has an internal search feature with query parameters like /?q=google, Google will crawl these URLs if they are linked from somewhere.
Similarly, in an e-commerce site, you might have facet filters generating URLs like /?color=red&size=s.
These query string parameters can create an infinite number of unique URL combinations that Google may try to crawl.
Those URLs basically don’t have unique content and just filter the data you have, which is great for user experience but not for Googlebot.
Allowing Google to crawl these URLs wastes crawl budget and affects your website’s overall crawlability. By blocking them via robots.txt rules, Google will focus its crawl efforts on more useful pages on your site.
Here is how to block internal search, facets, or any URLs containing query strings via robots.txt:
Disallow: *?*s=*
Disallow: *?*color=*
Disallow: *?*size=*
Each rule disallows any URL containing the respective query parameter, regardless of other parameters that may be present.
- * (asterisk) matches any sequence of characters (including none).
- ? (Question Mark): Indicates the beginning of a query string.
- =*: Matches the = sign and any subsequent characters.
This approach helps avoid redundancy and ensures that URLs with these specific query parameters are blocked from being crawled by search engines.
Note, however, that this method ensures any URLs containing the indicated characters will be disallowed no matter where the characters appear. This can lead to unintended disallows. For example, query parameters containing a single character will disallow any URLs containing that character regardless of where it appears. If you disallow ‘s’, URLs containing ‘/?pages=2’ will be blocked because *?*s= matches also ‘?pages=’. If you want to disallow URLs with a specific single character, you can use a combination of rules:
Disallow: *?s=*
Disallow: *&s=*The critical change is that there is no asterisk ‘*’ between the ‘?’ and ‘s’ characters. This method allows you to disallow specific exact ‘s’ parameters in URLs, but you’ll need to add each variation individually.
Apply these rules to your specific use cases for any URLs that don’t provide unique content. For example, in case you have wishlist buttons with “?add_to_wishlist=1” URLs, you need to disallow them by the rule:
Disallow: /*?*add_to_wishlist=*This is a no-brainer and a natural first and most important step recommended by Google.
An example below shows how blocking those parameters helped to reduce the crawling of pages with query strings. Google was trying to crawl tens of thousands of URLs with different parameter values that didn’t make sense, leading to non-existent pages.
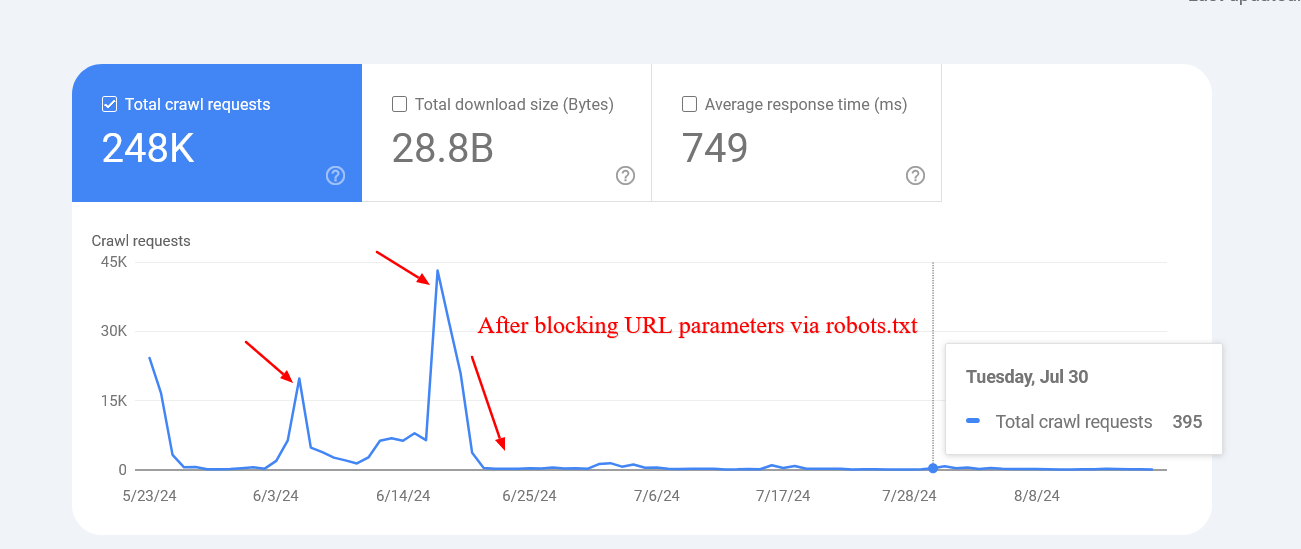 Reduced crawl rate of URLs with parameters after blocking via robots.txt.
Reduced crawl rate of URLs with parameters after blocking via robots.txt.However, sometimes disallowed URLs might still be crawled and indexed by search engines. This may seem strange, but it isn’t generally cause for alarm. It usually means that other websites link to those URLs.
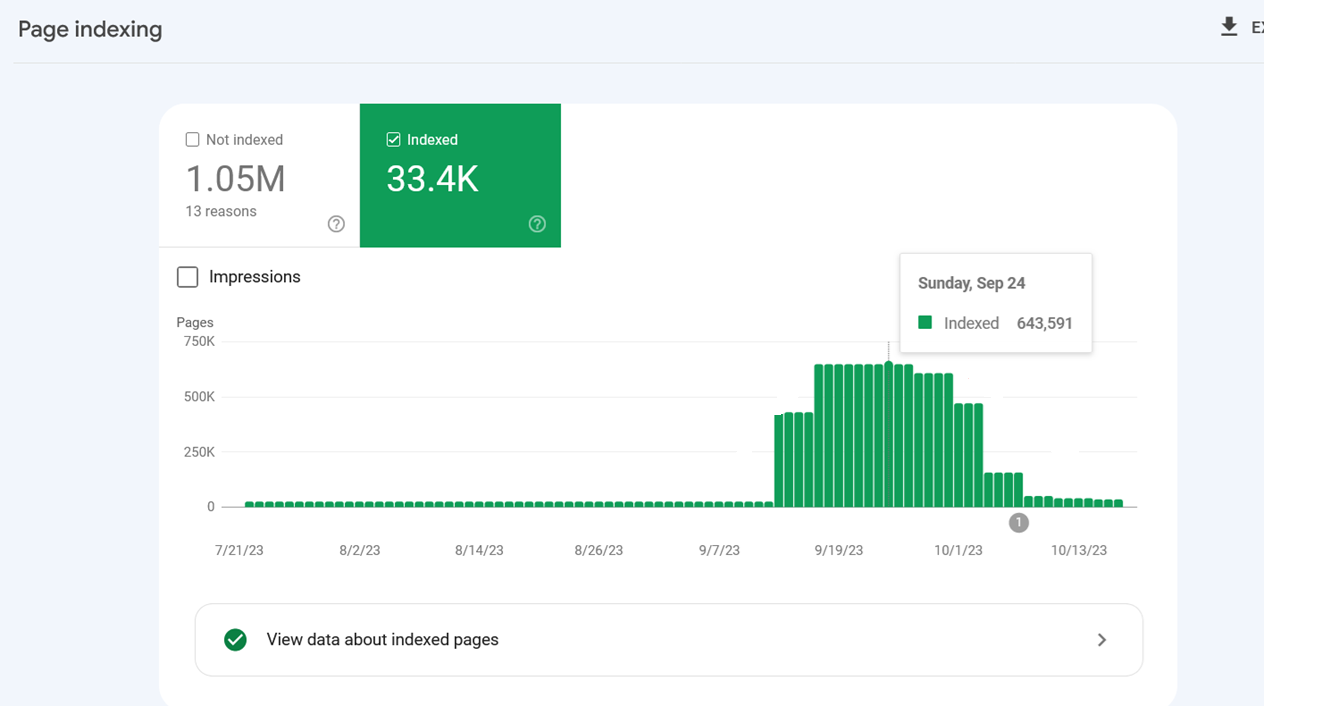 Indexing spiked because Google indexed internal search URLs after they were blocked via robots.txt.
Indexing spiked because Google indexed internal search URLs after they were blocked via robots.txt.Google confirmed that the crawling activity will drop over time in these cases.
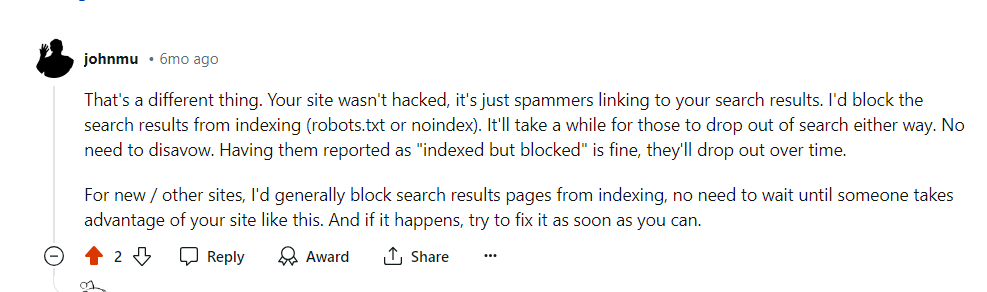 Google’s comment on Reddit, July 2024
Google’s comment on Reddit, July 2024Another important benefit of blocking these URLs via robots.txt is saving your server resources. When a URL contains parameters that indicate the presence of dynamic content, requests will go to the server instead of the cache. This increases the load on your server with every page crawled.
Please remember not to use “noindex meta tag” for blocking since Googlebot has to perform a request to see the meta tag or HTTP response code, wasting crawl budget.
1.2. Disallow Unimportant Resource URLs In Robots.txt
Besides disallowing action URLs, you may want to disallow JavaScript files that are not part of the website layout or rendering.
For example, if you have JavaScript files responsible for opening images in a popup when users click, you can disallow them in robots.txt so Google doesn’t waste budget crawling them.
Here is an example of the disallow rule of JavaScript file:
Disallow: /assets/js/popup.js
However, you should never disallow resources that are part of rendering. For example, if your content is dynamically loaded via JavaScript, Google needs to crawl the JS files to index the content they load.
Another example is REST API endpoints for form submissions. Say you have a form with action URL “/rest-api/form-submissions/”.
Potentially, Google may crawl them. Those URLs are in no way related to rendering, and it would be good practice to block them.
Disallow: /rest-api/form-submissions/
However, headless CMSs often use REST APIs to load content dynamically, so make sure you don’t block those endpoints.
In a nutshell, look at whatever isn’t related to rendering and block them.
2. Watch Out For Redirect Chains
Redirect chains occur when multiple URLs redirect to other URLs that also redirect. If this goes on for too long, crawlers may abandon the chain before reaching the final destination.
URL 1 redirects to URL 2, which directs to URL 3, and so on. Chains can also take the form of infinite loops when URLs redirect to one another.
Avoiding these is a common-sense approach to website health.
Ideally, you would be able to avoid having even a single redirect chain on your entire domain.
But it may be an impossible task for a large website – 301 and 302 redirects are bound to appear, and you can’t fix redirects from inbound backlinks simply because you don’t have control over external websites.
One or two redirects here and there might not hurt much, but long chains and loops can become problematic.
In order to troubleshoot redirect chains you can use one of the SEO tools like Screaming Frog, Lumar, or Oncrawl to find chains.
When you discover a chain, the best way to fix it is to remove all the URLs between the first page and the final page. If you have a chain that passes through seven pages, then redirect the first URL directly to the seventh.
Another great way to reduce redirect chains is to replace internal URLs that redirect with final destinations in your CMS.
Depending on your CMS, there may be different solutions in place; for example, you can use this plugin for WordPress. If you have a different CMS, you may need to use a custom solution or ask your dev team to do it.
3. Use Server Side Rendering (HTML) Whenever Possible
Now, if we’re talking about Google, its crawler uses the latest version of Chrome and is able to see content loaded by JavaScript just fine.
But let’s think critically. What does that mean? Googlebot crawls a page and resources such as JavaScript then spends more computational resources to render them.
Remember, computational costs are important for Google, and it wants to reduce them as much as possible.
So why render content via JavaScript (client side) and add extra computational cost for Google to crawl your pages?
Because of that, whenever possible, you should stick to HTML.
That way, you’re not hurting your chances with any crawler.
4. Improve Page Speed
As we discussed above, Googlebot crawls and renders pages with JavaScript, which means if it spends fewer resources to render webpages, the easier it will be for it to crawl, which depends on how well optimized your website speed is.
Google says:
Google’s crawling is limited by bandwidth, time, and availability of Googlebot instances. If your server responds to requests quicker, we might be able to crawl more pages on your site.
So using server-side rendering is already a great step towards improving page speed, but you need to make sure your Core Web Vital metrics are optimized, especially server response time.
5. Take Care of Your Internal Links
Google crawls URLs that are on the page, and always keep in mind that different URLs are counted by crawlers as separate pages.
If you have a website with the ‘www’ version, make sure your internal URLs, especially on navigation, point to the canonical version, i.e. with the ‘www’ version and vice versa.
Another common mistake is missing a trailing slash. If your URLs have a trailing slash at the end, make sure your internal URLs also have it.
Otherwise, unnecessary redirects, for example, “https://www.example.com/sample-page” to “https://www.example.com/sample-page/” will result in two crawls per URL.
Another important aspect is to avoid broken internal links pages, which can eat your crawl budget and soft 404 pages.
And if that wasn’t bad enough, they also hurt your user experience!
In this case, again, I’m in favor of using a tool for website audit.
WebSite Auditor, Screaming Frog, Lumar or Oncrawl, and SE Ranking are examples of great tools for a website audit.
6. Update Your Sitemap
Once again, it’s a real win-win to take care of your XML sitemap.
The bots will have a much better and easier time understanding where the internal links lead.
Use only the URLs that are canonical for your sitemap.
Also, make sure that it corresponds to the newest uploaded version of robots.txt and loads fast.
7. Implement 304 Status Code
When crawling a URL, Googlebot sends a date via the “If-Modified-Since” header, which is additional information about the last time it crawled the given URL.
If your webpage hasn’t changed since then (specified in “If-Modified-Since“), you may return the “304 Not Modified” status code with no response body. This tells search engines that webpage content didn’t change, and Googlebot can use the version from the last visit it has on the file.
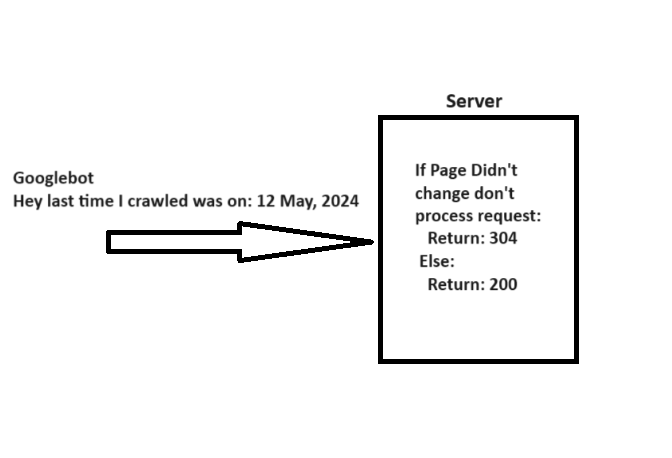 A simple explanation of how 304 not modified http status code works.
A simple explanation of how 304 not modified http status code works.Imagine how many server resources you can save while helping Googlebot save resources when you have millions of webpages. Quite big, isn’t it?
However, there is a caveat when implementing 304 status code, pointed out by Gary Illyes.
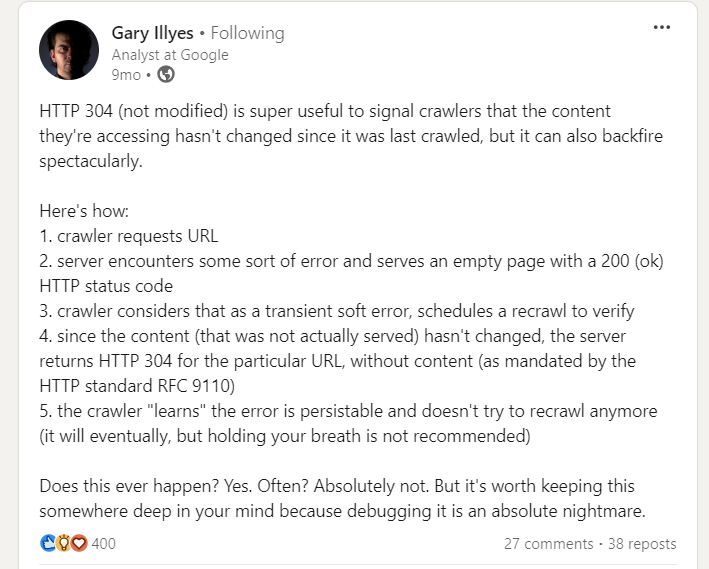 Gary Illes on LinkedIn
Gary Illes on LinkedInSo be cautious. Server errors serving empty pages with a 200 status can cause crawlers to stop recrawling, leading to long-lasting indexing issues.
8. Hreflang Tags Are Vital
In order to analyze your localized pages, crawlers employ hreflang tags. You should be telling Google about localized versions of your pages as clearly as possible.
First off, use the <link rel="alternate" hreflang="lang_code" href="url_of_page" /> in your page’s header. Where “lang_code” is a code for a supported language.
You should use the <loc> element for any given URL. That way, you can point to the localized versions of a page.
Read: 6 Common Hreflang Tag Mistakes Sabotaging Your International SEO
9. Monitoring and Maintenance
Check your server logs and Google Search Console’s Crawl Stats report to monitor crawl anomalies and identify potential problems.
If you notice periodic crawl spikes of 404 pages, in 99% of cases, it is caused by infinite crawl spaces, which we have discussed above, or indicates other problems your website may be experiencing.
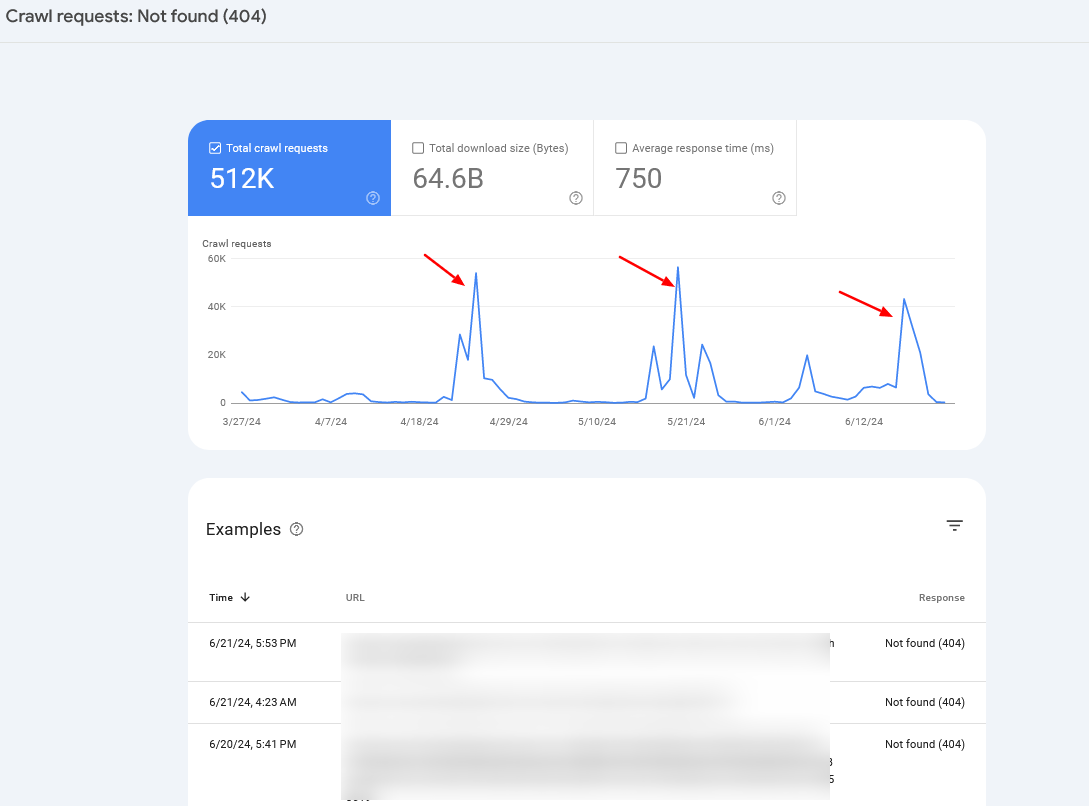 Crawl rate spikes
Crawl rate spikesOften, you may want to combine server log information with Search Console data to identify the root cause.
Summary
So, if you were wondering whether crawl budget optimization is still important for your website, the answer is clearly yes.
Crawl budget is, was, and probably will be an important thing to keep in mind for every SEO professional.
Hopefully, these tips will help you optimize your crawl budget and improve your SEO performance – but remember, getting your pages crawled doesn’t mean they will be indexed.
In case you face indexation issues, I suggest reading the following articles:
- The 5 Most Common Google Indexing Issues by Website Size
- 14 Top Reasons Why Google Isn’t Indexing Your Site
- Google On Fixing Discovered Currently Not Indexed
Featured Image: BestForBest/Shutterstock
All screenshots taken by author
