

There is one report in Google Search Console that’s both insanely useful and quite hard to find, especially if you’re just starting your SEO journey.
It’s one of the most powerful tools for every SEO professional, even though you can’t even access it from within Google Search Console’s main interface.
I’m talking about the Crawl stats report.
In this article, you’ll learn why this report is so important, how to access it, and how to use it for SEO advantage.
How Is Your Website Crawled?
Crawl budget (the number of pages Googlebot can and wants to crawl) is essential for SEO, especially for large websites.
If you have issues with your website’s crawl budget, Google may not index some of your valuable pages.
And as the saying goes, if Google didn’t index something, then it doesn’t exist.
Google Search Console can show you how many pages on your site are visited by Googlebot every day.
Armed with this knowledge, you can find anomalies that may be causing your SEO issues.
Diving Into Your Crawl Stats: 5 Key Insights
To access your Crawl stats report, log in to your Google Search Console account and navigate to Settings > Crawl stats.
Here are all of the data dimensions you can inspect inside the Crawl stats report:
1. Host
Imagine you have an ecommerce shop on shop.website.com and a blog on blog.website.com.
Using the Crawl stats report, you can easily see the crawl stats related to each subdomain of your website.
Unfortunately, this method doesn’t currently work with subfolders.
2. HTTP Status
One other use case for the Crawl stats report is looking at the status codes of crawled URLs.
That’s because you don’t want Googlebot to spend resources crawling pages that aren’t HTTP 200 OK. It’s a waste of your crawl budget.
To see the breakdown of the crawled URLs per status code, go to Settings > Crawl Stats > Crawl requests breakdown.
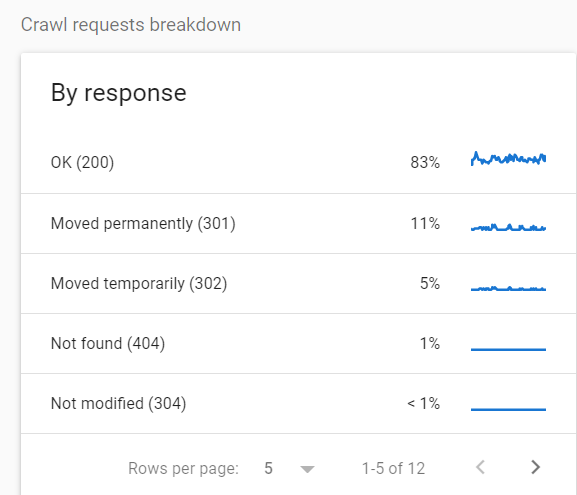
In this particular case, 16% of all requests were made for redirected pages.
If you see statistics like these, I recommend further investigating and looking for redirect hops and other potential issues.
In my opinion, one of the worst cases you can see here is a large amount of 5xx errors.
To quote Google’s documentation: “If the site slows down or responds with server errors, the limit goes down and Googlebot crawls less.”
If you’re interested in this topic, Roger Montti wrote a detailed article on 5xx errors in Google Search Console.
3. Purpose
The Crawl stats report breaks down the crawling purpose into two categories:
- URLs crawled for Refresh purposes (a recrawl of already known pages, e.g., Googlebot is visiting your homepage to discover new links and content).
- URLs crawled for Discovery purposes (URLs that were crawled for the first time).
This breakdown is insanely useful, and here’s an example:
I recently encountered a website with ~1 million pages classified as “Discovered – currently not indexed.”
This issue was reported for 90% of all the pages on that site.
(If you’re not familiar with it, “Discovered but not index” means that Google discovered a given page but didn’t visit it. If you discovered a new restaurant in your town but didn’t give it a try, for example.)
One of the options was to wait, hoping for Google to index these pages gradually.
Another option was to look at the data and diagnose the issue.
So I logged in to Google Search Console and navigated to Settings > Crawl Stats > Crawl Requests: HTML.
It turned out that, on average, Google was visiting only 7460 pages on that website per day.
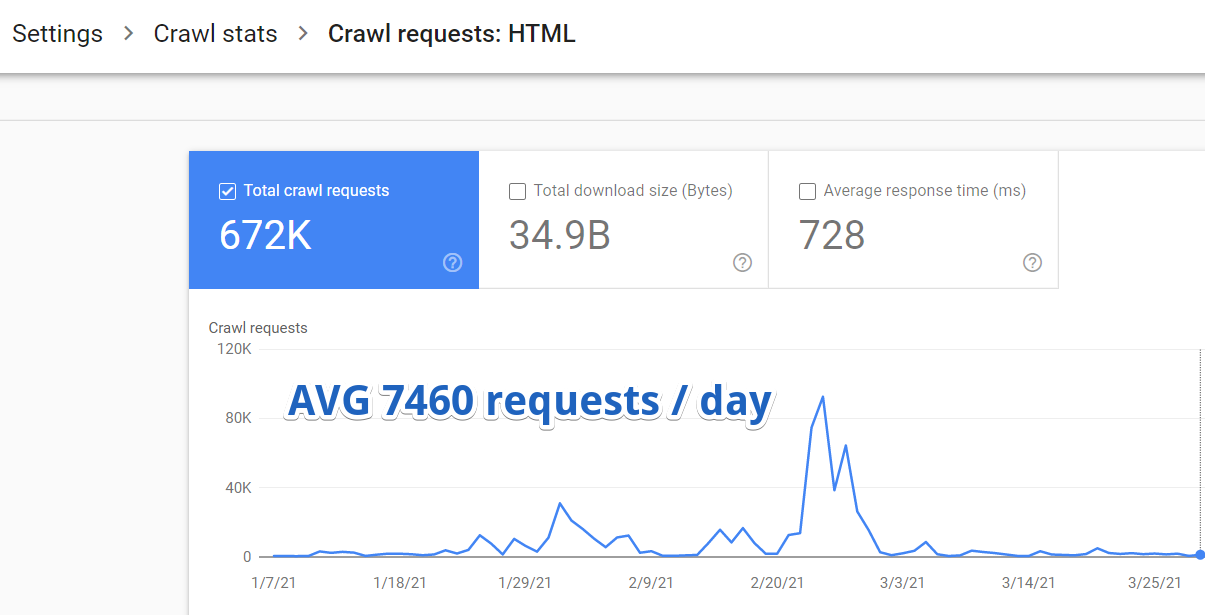
But here’s something even more important.
Thanks to the Crawl stats report, I found out that only 35% of these 7460 URLs were crawled for discovery reasons.
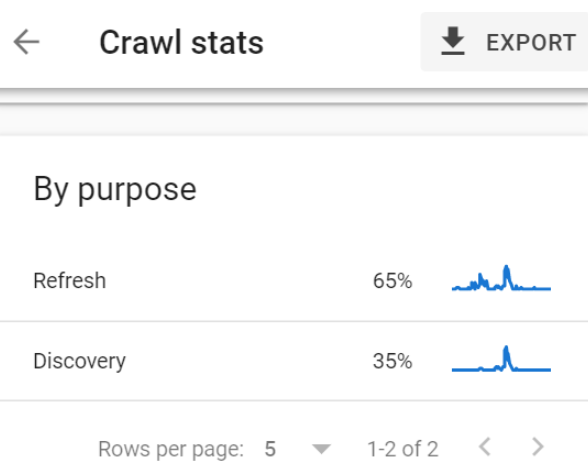
That’s just 2611 new pages discovered by Google per day.
2611 out of over a million.
It would take 382 days for Google to fully index the whole website at that pace.
Finding this out was a gamechanger. All other search optimizations were postponed as we fully focused on crawl budget optimization.
4. File Type
GSC Crawl stats can be helpful for JavaScript websites. You can easily check how frequently Googlebot crawls JS files that are required for proper rendering.
If your site is packed with images and image search is crucial for your SEO strategy, this report will help a lot as well – you can see how well Googlebot can crawl your images.
5. Googlebot Type
Finally, the Crawl stats report gives you a detailed breakdown of the Googlebot type used to crawl your site.
You can find out the percentage of requests made by either Mobile or Desktop Googlebot and Image, Video, and Ads bots.
Other Useful Information
It’s worth noting that the Crawl stats report has invaluable information that you won’t find in your server logs:
- DNS errors.
- Page timeouts.
- Host issues such as problems fetching the robots.txt file.
Using Crawl Stats in the URL Inspection Tool
You can also access some granular crawl data outside of the Crawl stats report, in the URL Inspection Tool.
I recently worked with a large ecommerce website and, after some initial analyses, noticed two pressing issues:
- Many product pages weren’t indexed in Google.
- There was no internal linking between products. The only way for Google to discover new content was through sitemaps and paginated category pages.
A natural next step was to access server logs and check if Google had crawled the paginated category pages.
But getting access to server logs is often really difficult, especially when you’re working with a large organization.
Google Search Console’s Crawl stats report came to the rescue.
Let me guide you through the process I used and that you can use if you’re struggling with a similar issue:
1. First, look up a URL in the URL Inspection Tool. I chose one of the paginated pages from one of the main categories of the site.
2. Then, navigate to the Coverage > Crawl report.
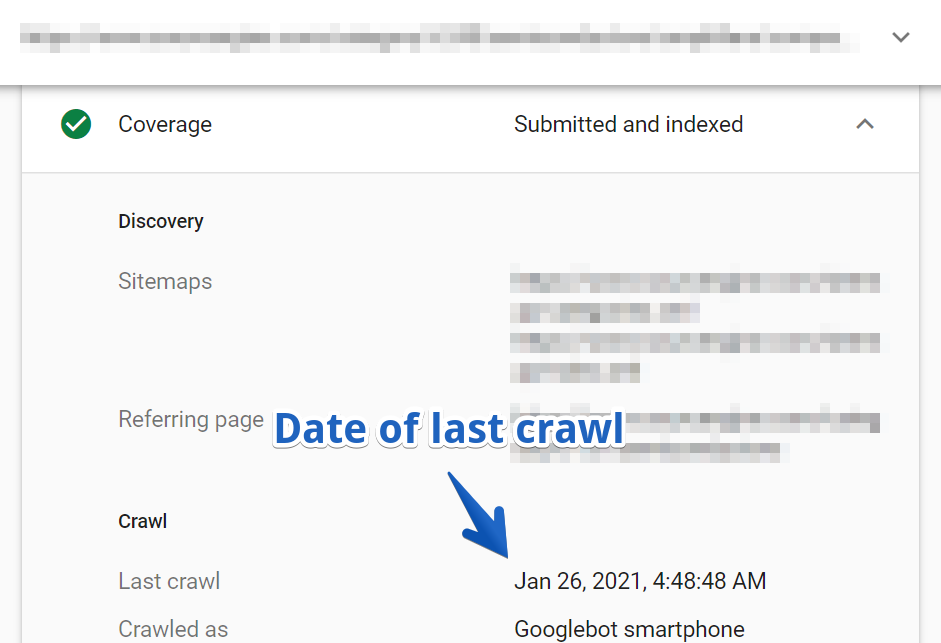
In this case, the URL was last crawled three months ago.
Keep in mind that this was one of the main category pages of the website that hadn’t been crawled for over three months!
I went deeper and checked a sample of other category pages.
It turned out that Googlebot never visited many main category pages. Many of them are still unknown to Google.
I don’t think I need to explain how crucial it is to have that information when you’re working on improving any website’s visibility.
The Crawl stats report allows you to look things like this up within minutes.
Wrapping Up
As you can see, the Crawl stats report is a powerful SEO tool even though you could use Google Search Console for years without ever finding it.
It will help you diagnose indexing issues and optimize your crawl budget so that Google can find and index your valuable content quickly, which is particularly important for large sites.
I gave you a couple of use cases to think of, but now the ball is in your court.
How will you use this data to improve your site’s visibility?
More Resources:
- Crawl-First SEO: A 12-Step Guide to Follow Before Crawling
- 7 Tips to Optimize Crawl Budget for SEO
- How Search Engines Work
Image Credits
All screenshots taken by author, April 2021
