

Google is good at its job. Sometimes, a little too good – indexing pages it was never meant to find.
- Undesirable URLs that are not contained in your sitemap.
- Orphaned URLs not linked on your website.
- Bizarre URLs you may not even know exist.
Most SEO professionals worry about getting pages into the Google index. But you also need to be concerned with getting low-value pages out of the index.
Let’s deep dive into why having fewer indexed pages can actually lead to a higher number organic sessions. And how different deindexing methods impact SEO.
What Is Index Bloat?
Index bloat is when a site has an excessive number of low-value pages indexed by search engines. These pages are often auto-generated with little or no unique content.
The existence of these URLs has a cascading impact on the entire technical SEO process.
Common URL types that cause index bloat include:
- Filter combinations from faceted navigation.
- Disorderly archive pages.
- Unrestrained tag pages.
- Pagination pages.
- Unruly parameter pages.
- Expired content pages.
- Non-optimized on-site search result pages.
- Auto-generated user profiles with little content.
- Tracking URLs.
- Mishandled http to https.
- Inconsistent www vs. non-www.
- Subdirectories that shouldn’t be indexed.
Index bloat reduces crawl efficiency as Googlebot slums through the low-value paths. This slows down indexing speed for new content and re-crawling of updated content that does have SEO value.
Often, index bloat contains duplicate content or causes keyword cannibalization. With multiple pages from one site competing for the same search intent, it becomes confusing to search engines which page is most relevant as ranking signals are split across many URLs. This hurts the site’s ability to rank in top positions.
And if low-quality pages do manage to rank, searchers will likely be disappointed with the landing page and pogostick. Sending poor user experience signals to Google and hurting your brand.
All of this combined decreases the quality evaluation of the domain in the eyes of search engines.
This is a problem because URLs are not ranked solely on their own merits, but also based on the site they belong to.
Every page indexed affects how Google’s quality algorithms evaluate a site’s reputation.
Google Webmaster Central states that:
“Low-quality content on some parts of a website can impact the whole site’s rankings, and thus removing low quality pages…could eventually help the rankings of your higher-quality content.”
John Mueller elaborated on this in 2015.
“Our quality algorithms do look at the website overall, so they do look at everything that’s indexed. And if we see that the bulk of the indexed content is actually lower quality content then we might say ‘well, maybe this site overall is kind of lower quality. And if you can tell us that this lower quality content shouldn’t be indexed and shouldn’t be taken into account, then we can really focus on the high quality stuff that you are letting us index.”
And again in March 2017. And again in August 2017. And again in October 2017.
This is why the goal of SEO is not to get as many pages into the index as possible. But rather to make a valuable match between the searcher and the landing page.
To achieve this goal, you should only allow indexing of pages you want searchers to land on and deindex all pages that offer no unique value to search engines or users.
How to Diagnose Index Bloat
The Google Search Console (GSC) Coverage Report is one of the fastest and most reliable ways to identify page types causing index bloat.
Presuming your XML sitemap is in line with SEO best practices, so contains only SEO relevant URLs, simply look at the example URLs that are indexed but not submitted in the sitemap.
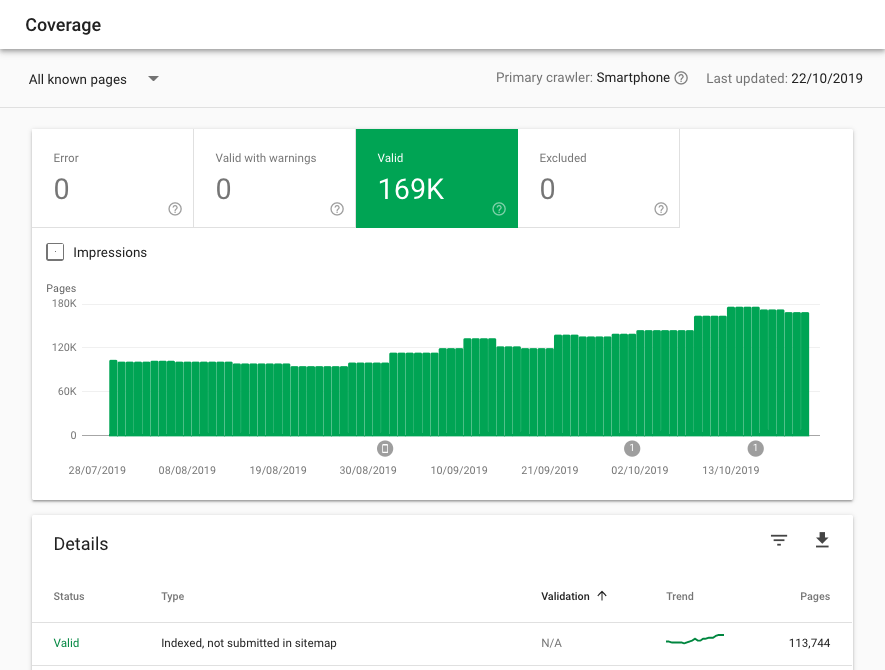
If your XML sitemaps are not optimized, run a limitless crawling tool and compare the number of indexable URLs picked up by the crawler vs the number of valid pages.
If you have significantly more valid pages than crawled URLs there is likely an index bloat issue.
Don’t use a site: search advanced operator to count the number of indexed pages, it is highly unreliable.
Once you have identified low-value pages to be deindexed, it’s worthwhile to cross-reference the URLs against Google Analytics data to gauge the likely effect on organic sessions.
Usually, due to their nature, there will be no negative impact, but it’s best to be sure before you do any large scale deindexing.
How to Deindex Pages from Google
There are many mechanisms by which you can eject unwanted pages out of the search engine index. Each with its own pros and cons.
But most deindexing methodologies fix index bloat based on rules for page types.
This makes it easier to implement than other content improvement strategies that rely on a page-by-page approach, such as content republishing.
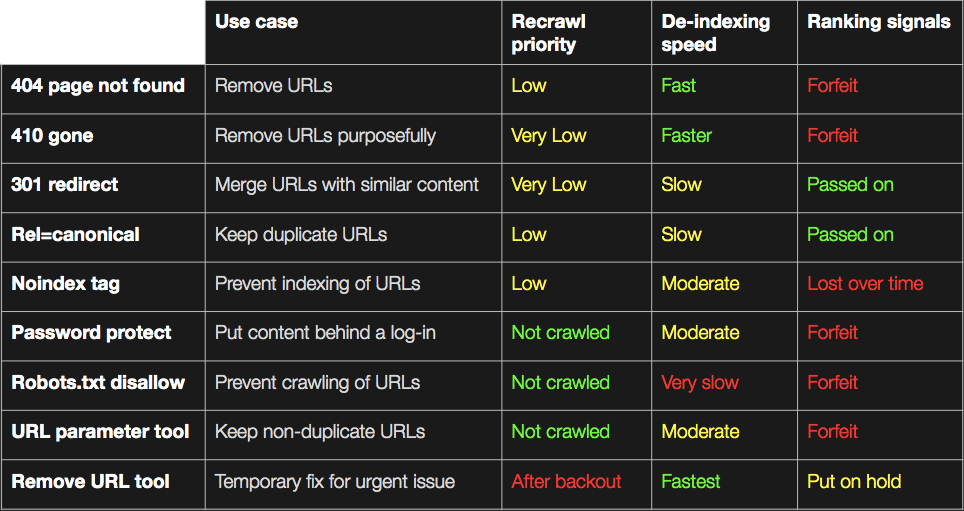
1. 410 Gone or 2. 404 Page Not Found
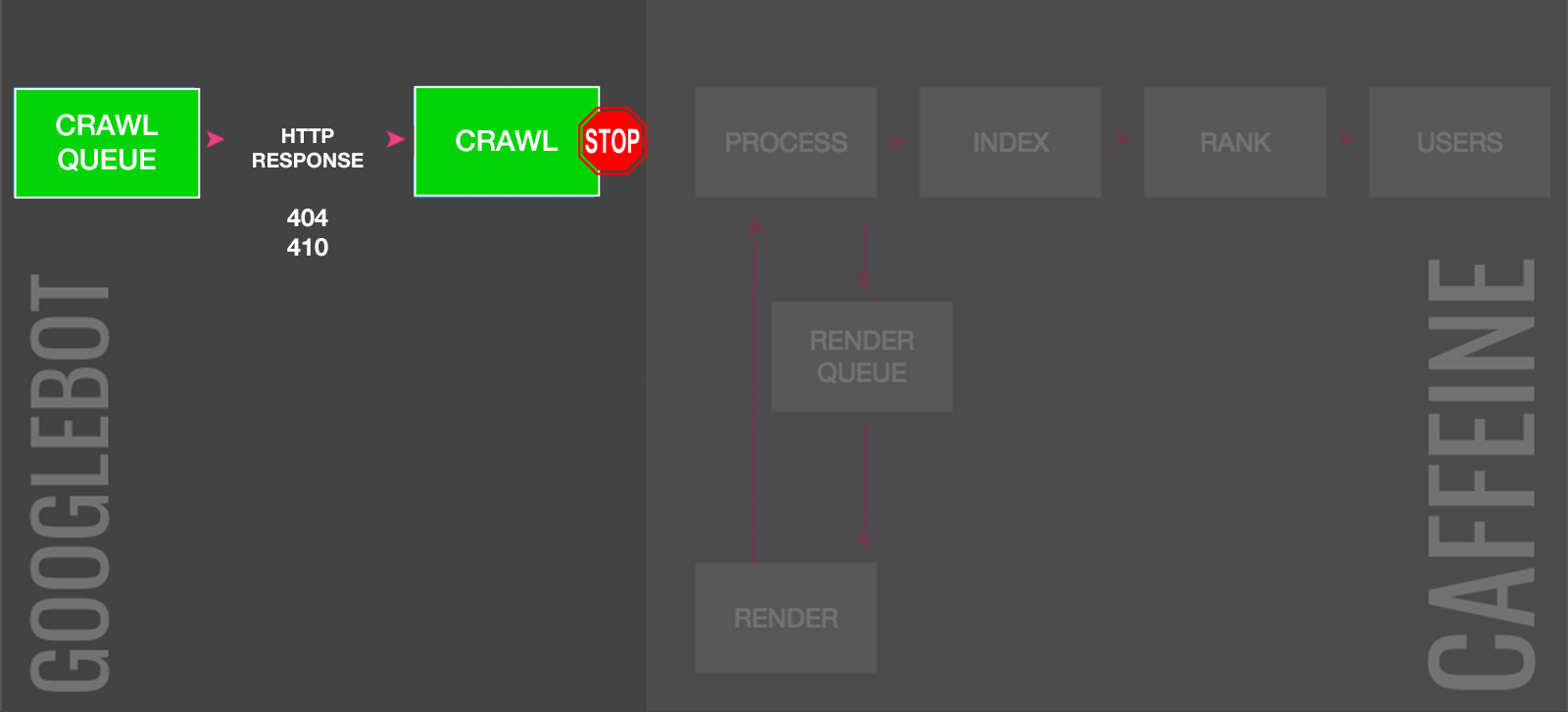
A speedy way to deindex a page is by the server returning a 410 HTTP status code (a.k.a., “Gone”).
This signals to Google the page was intentionally removed, making it clearer than a 404 code (a.k.a., “Page not found”), which would result in marginally slower deindexing.
For anyone concerned about amassing 4xx “errors”, let me put your mind at ease. There is no Google penalty for 4xx codes. But if the URL had any ranking signals, these are lost.
Index bloat prevention score: 1/5
Index bloat damage control score: 4/5
3. 301 Redirect
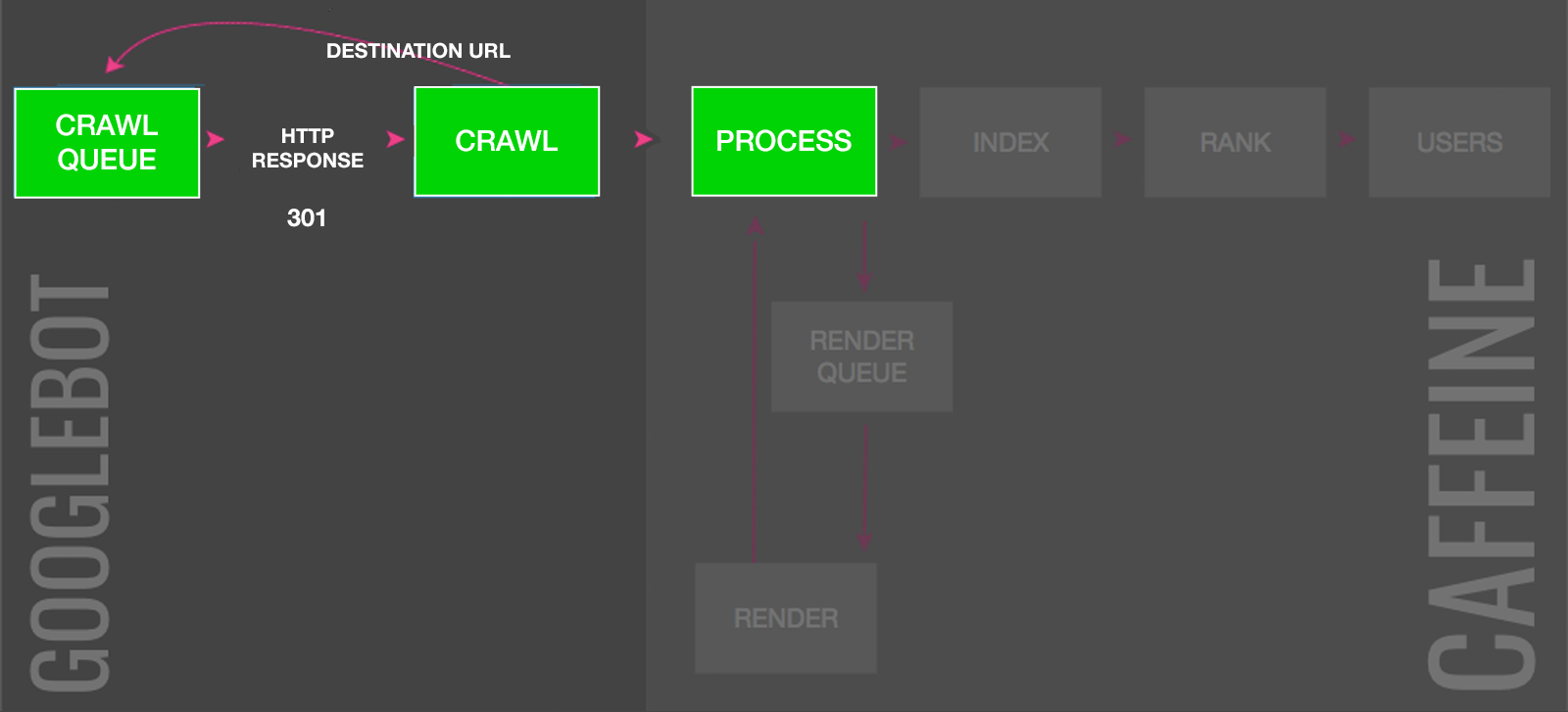
If index bloat is caused by many pages targeting the same topic, you can merge them into a single page with 301 redirects and consolidate their ranking signals.
For Google to deindex the redirected pages it must crawl the original URL, see the 301 status code, add the destination URL to the crawl queue and then process the content to confirm it’s equivalent in nature. If so, the ranking signals, with no dilution, will be passed on.
This can be a slow process if the destination URL is low priority in the crawl queue. And an extremely slow process if you have redirect chains.
Moreover, if you redirect to an irrelevant page, such as the homepage, Google will treat this as a soft 404 and won’t pass on the ranking signals. In which case, a 410 gone would have achieved the same result but with faster deindexing.
Index bloat prevention score: 1/5
Index bloat damage control score: 3/5
4. Rel=Canonical Link
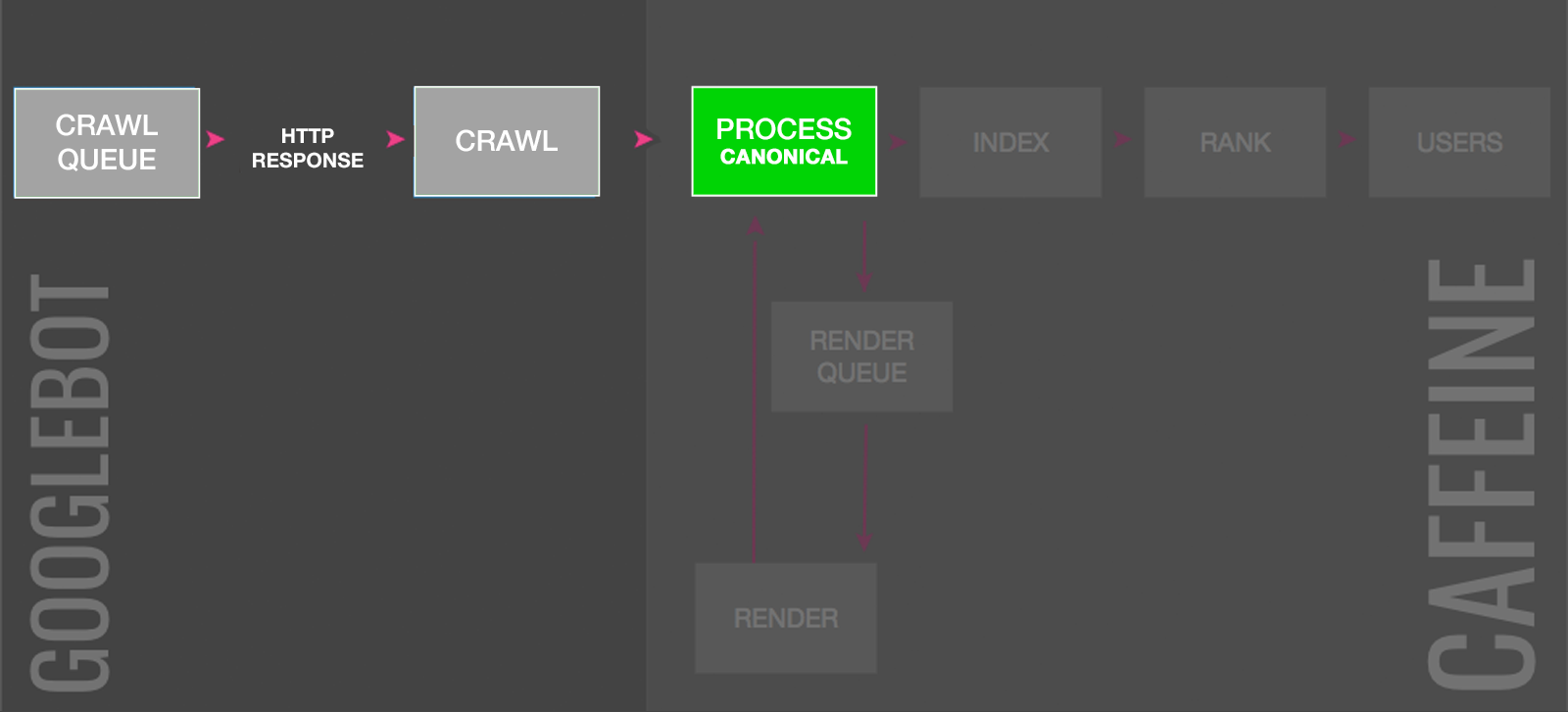
For duplicate content URLs, a rel=canonical link suggests to Google which of the duplicate URLs to index.
If the tag is accepted, the alternate pages (the lower value duplicates) will be crawled but much less frequently and will be excluded from the index, passing their ranking signals on to the canonical (the preferred page to be indexed).
But to be accepted, the content must highly similar and both URLs need to be crawled and processed by Google, which can be somewhat slow.
Index bloat prevention score: 4/5
Index bloat damage control score: 2/5
5. URL Parameter Tool
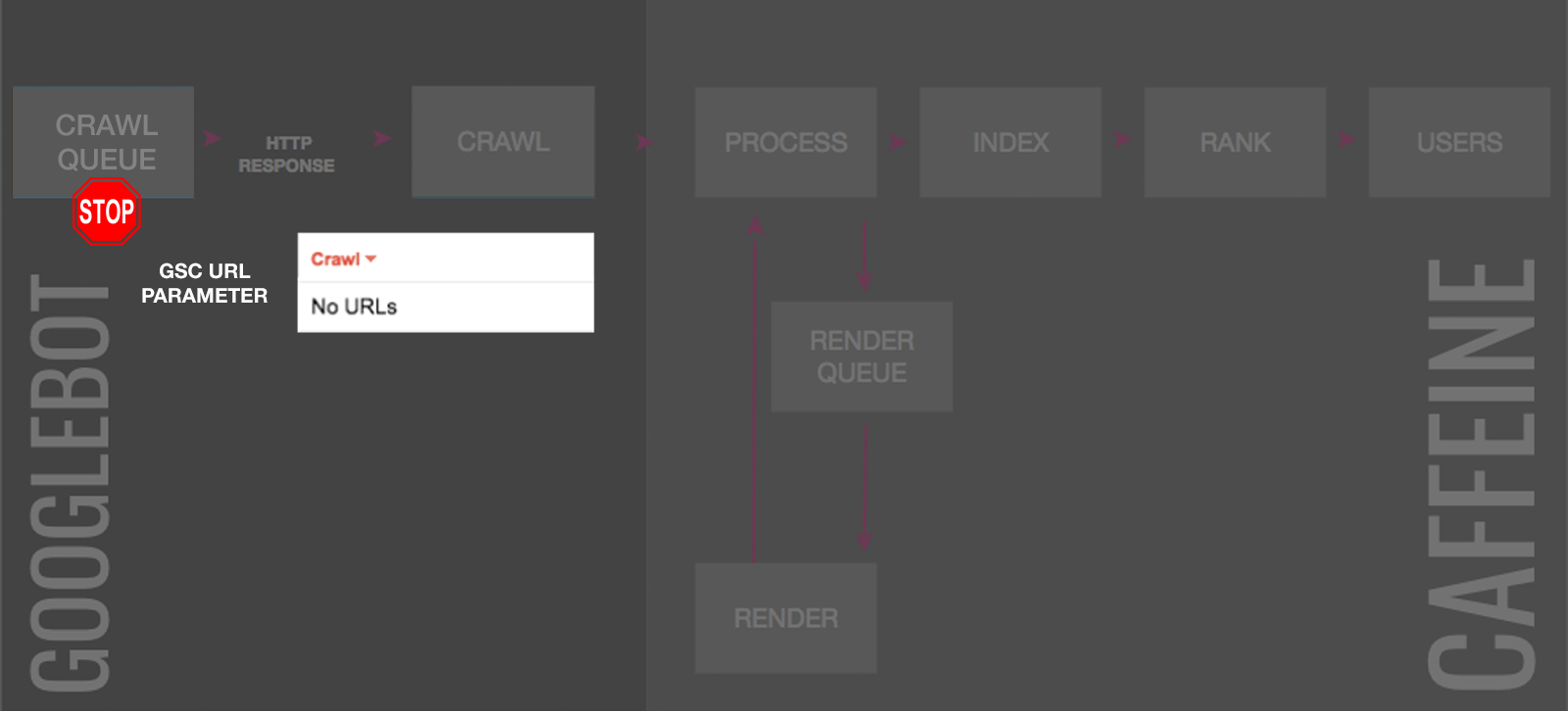
Within Google Search Console you can specify how Googlebot should handle parameters.
The three obvious drawbacks of the URL parameter tool are:
- It only works if the URL is parameter based.
- It doesn’t address any search engine apart from Google.
- It is designed only to control crawling.
Even though it doesn’t control indexing directly, if you specify “No Crawl” on a parameter, John Mueller has commented that those URLs would eventually be dropped from the index.
But this comes at a price, if Googlebot can’t crawl, the signals can’t be processed, which can impact ranking, or extract internal links to add to the crawl queue, which may slow down site indexing.
Index bloat prevention score: 3/5
Index bloat damage control score: 1/5
6. Robots.txt
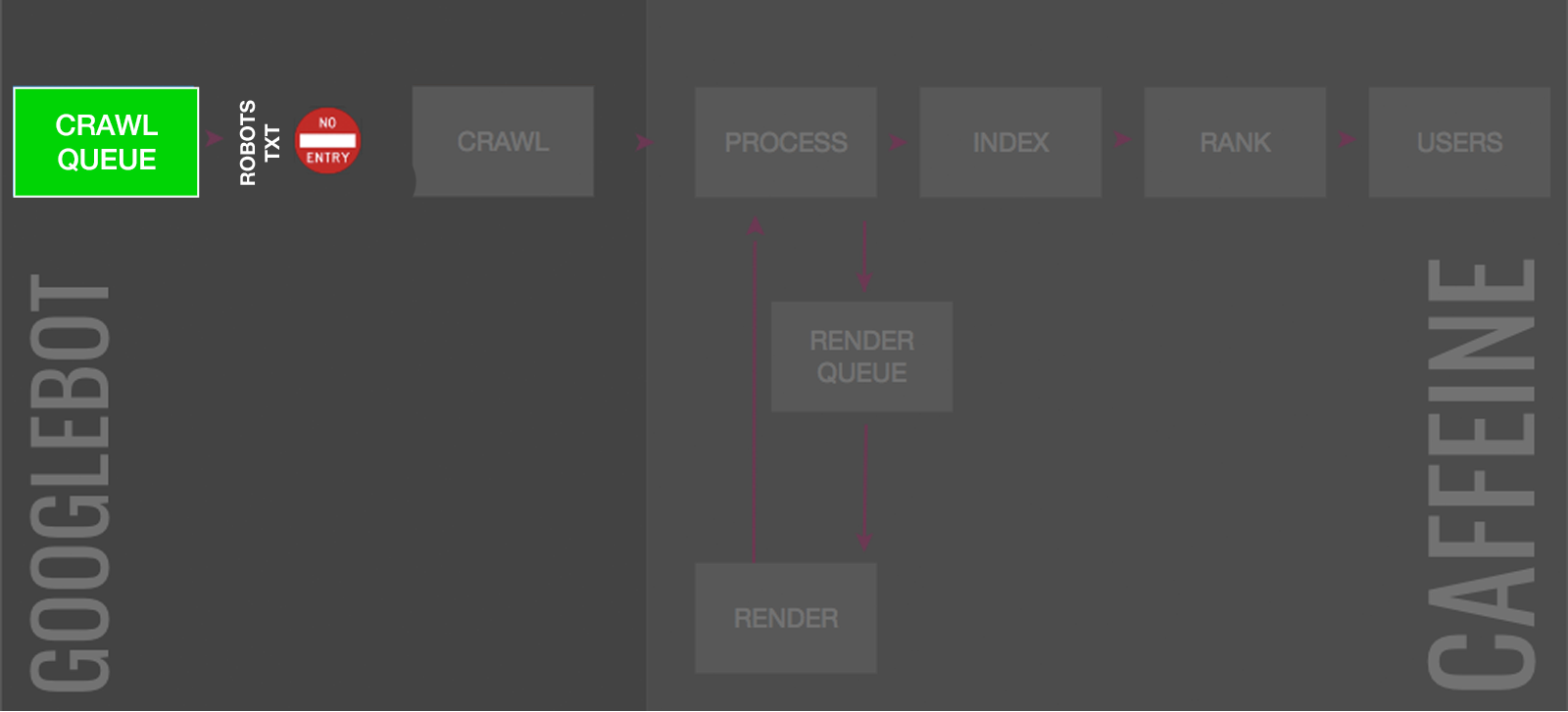
Disallow directives within the robots.txt file tells search engines which pages they are not allowed to crawl.
Similar to the URL parameter tool, this doesn’t control indexing directly. If the page is linked from other places on the web, Google may deem it relevant to include in the index.
Moreover, blocking within robots.txt is not a clear signal for how search engines should treat currently indexed URLs.
So while over time, it’s likely the pages will be dropped from the index as Google tends not to include pages it can’t crawl, it will be a slow process.
Index bloat prevention score: 2/5
Index bloat damage control score: 1/5
7. Noindex Tags
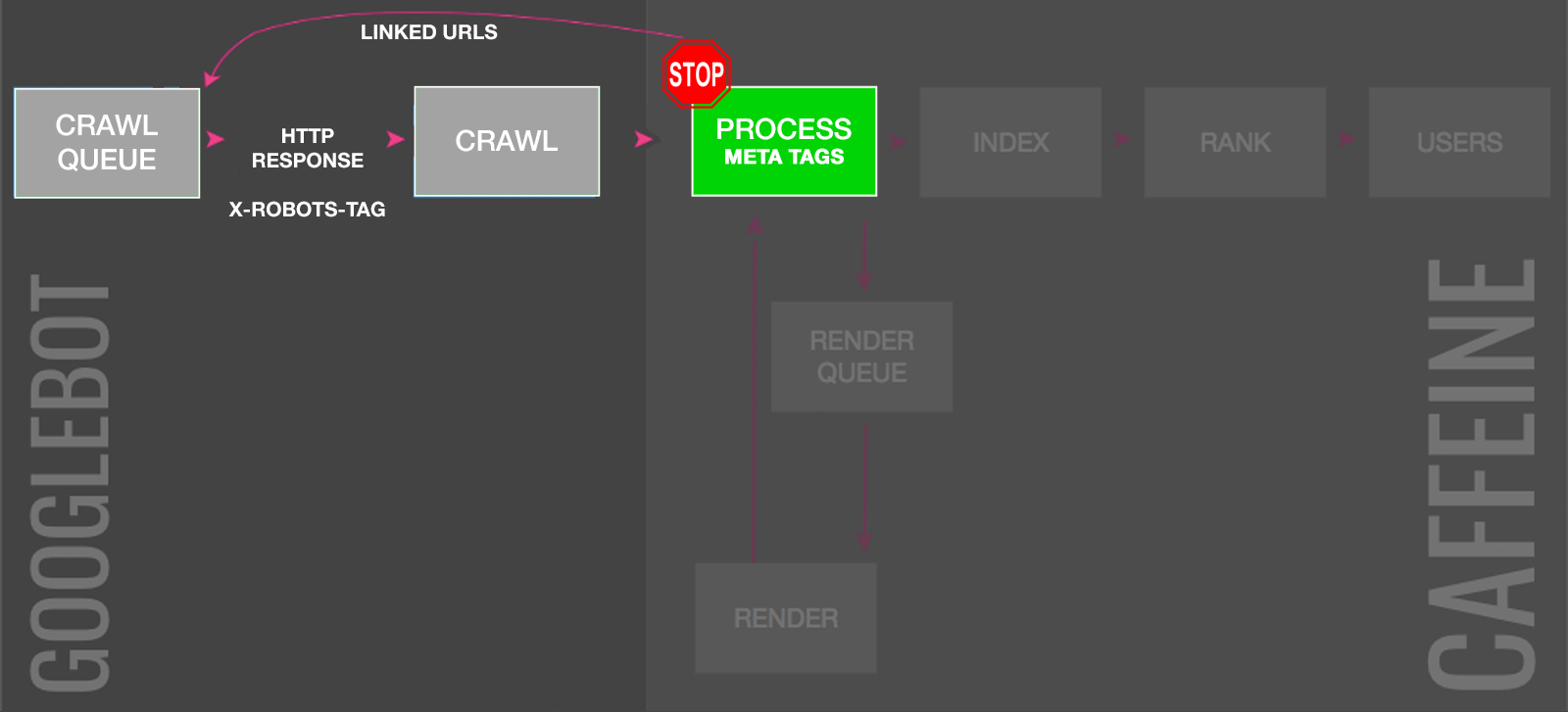
To definitively block a page from being indexed, you need to use a “noindex” robots meta tag or X-Robots-Tag. Don’t use a noindex directive in the robots.txt as this is not honored by search engines.
Know that a noindex directive has a cascading impact:
- Prevents addition or, once processed, ensuring deindexing from search engines.
- Causes noindexed URLs to be crawled less frequently.
- Stops any ranking signals to the URL from being attributed.
- If present for a long time, leads to a “nofollow” of the page’s links as well, which means Google won’t add those links to the crawl queue and ranking signals won’t be passed to linked pages.
Index bloat prevention score: 4/5
Index bloat damage control score: 4/5
8. Password Protection
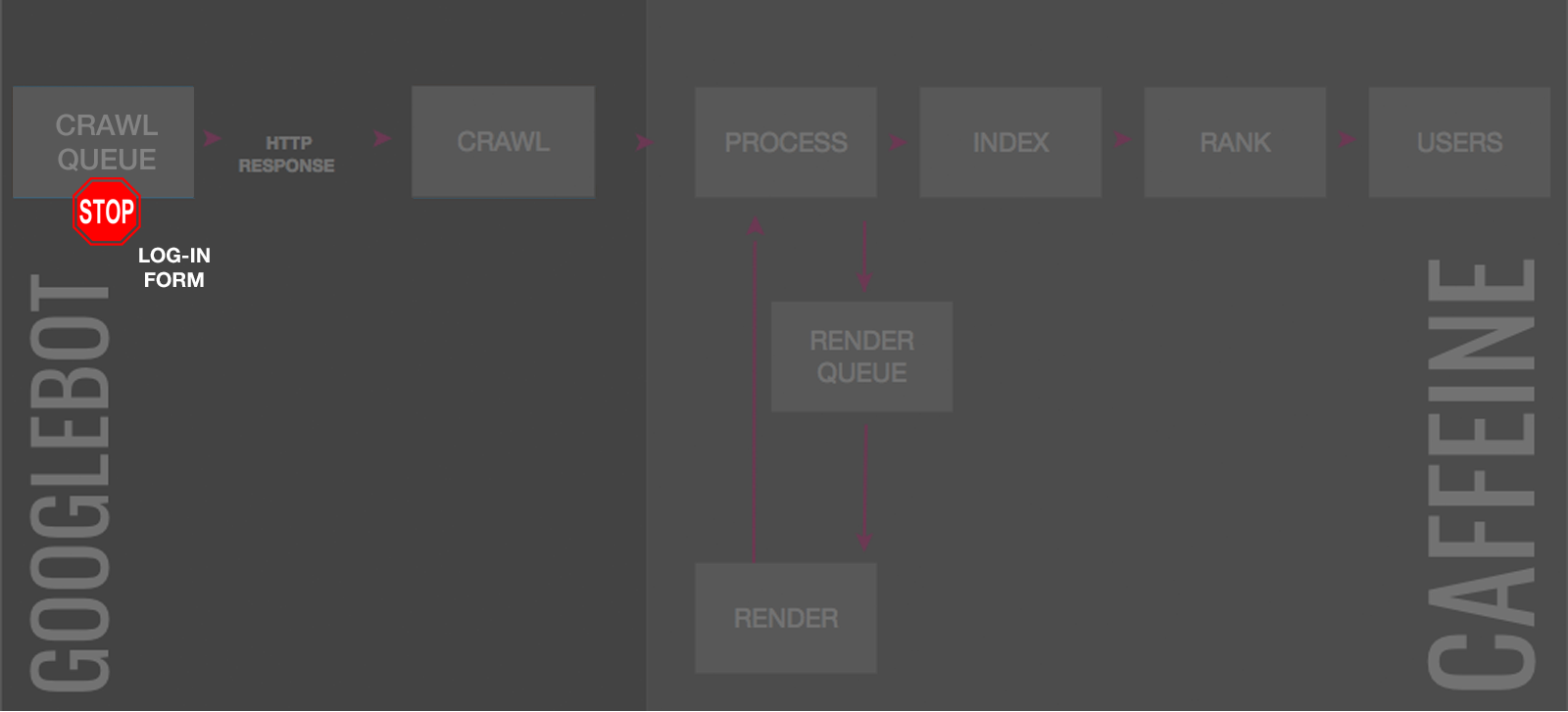
Password protecting the files on your server stops search engines in their tracks. The URLs can not be crawled, indexed or pass on any ranking signals.
But obviously this also blocks users, so it is limited to deindexing content you choose to move behind a log-in.
Any deindexing requires search engines to try and crawl the URL path, see it is no longer welcome and subsequently remove the content.
This can take quite some time as the more URLs in that section it crawls, the more it will understand there is no value returned on the crawl budget and the lower in the crawl queue it will prioritize similar URLs.
Index bloat prevention score: 2/5
Index bloat damage control score: 1/5
9. Remove URLs Tool
If you have an urgent need to deindex a page from Google, the Remove URLs tool is a fast option. Requests are typically processed the day they are submitted.
The limitation here is that this is a temporary block. Successful removal requests will last around 90 days before the content can reappear in the SERPs.
As such, the only valuable use case here is when you urgently need to block a page but can’t get resources. Other measures would need to be taken before the blackout period ends if you want to keep the page out of the index.
Index bloat prevention score: 1/5
Index bloat damage control score: 3/5
TL;DR
Overall, prevention is better than cure.
A strategically designed website architecture and a user-focused content strategy are necessary for long-term success in SEO.
This should be supported by sensible use of canonical links and judicious use of meta robots noindex tag to prevent index bloat.
Google has an exceptionally long memory. Once pages are crawled, Google can be stubborn when it comes to forgetting them. This can make deindexing a sluggish and tedious process.
Once you have an appropriate deindexing strategy in place, have patience. The results may be slow to become noticeable, but they will be worthwhile.
Grammatical Note for SEO Nerds
It’s search engine indexing or deindexing, not indexation or deindexation. Unless you’re French.
I really wish the SEO industry would stop using the term 'indexation' when they actually mean 'indexing'.
— Barry Adams 📰 (@badams) April 24, 2017
DYK that if you tweet 'indexation' 3 times, @badams appears? 😉 pic.twitter.com/ORjt6jEgUr
— Jamie Indigo 👾 @jammer_volts@mastodon.social (@Jammer_Volts) September 11, 2018
More Resources:
- 16 Ways to Get Deindexed by Google
- The Essential Guide to Managing Expired Content
- Advanced Technical SEO: A Complete Guide
Image Credits
Featured & In-Post Images: Created by author, October 2019
All screenshots taken by author, October 2019
