

Google Search Console lets you look at your website through Google’s eyes.
You get information about the performance of your website and details about page experience, security issues, crawling, or indexation.
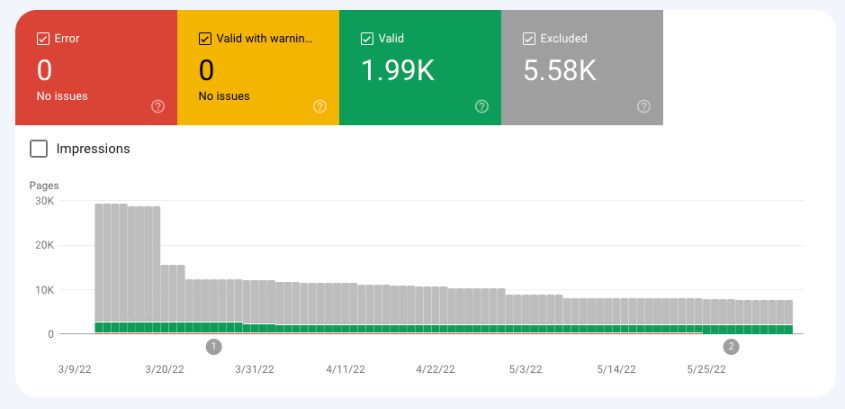
The Excluded part of the Google Search Console Index Coverage report provides information about the indexing status of your website’s pages.
Learn why some of the pages of your website land in the Excluded report in Google Search Console – and how to fix it.
What Is The Index Coverage Report?
The Google Search Console Coverage report shows detailed information about the index status of the web pages of your website.
Your web pages can go into one of the following four buckets:
- Error: The pages that Google cannot index. You should review this report because Google thinks you may want these pages indexed.
- Valid with warnings: The pages that Google indexes, but there are some issues you should resolve.
- Valid: The pages that Google indexes.
- Excluded: The pages that are excluded from the index.
What Are Excluded Pages?
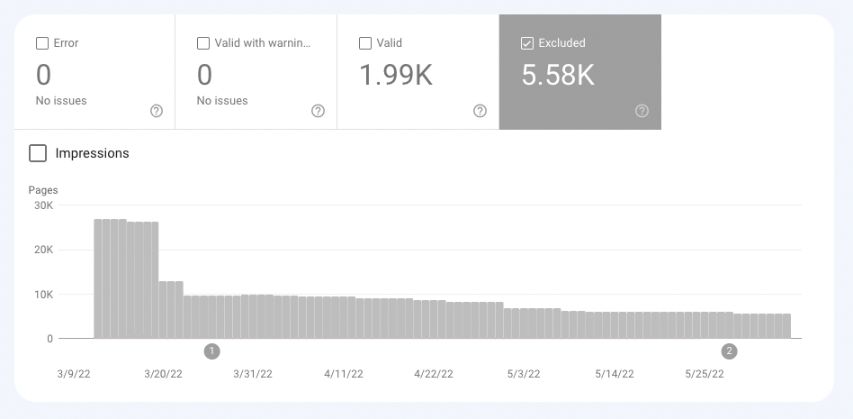
Google does not index pages in the Error and Excluded buckets.
The main difference between the two is:
- Google thinks pages in Error should be indexed but cannot because of an error you should review. For example, non-indexable pages submitted through an XML sitemap fall under Error.
- Google thinks pages in the Excluded bucket should indeed be excluded, and this is your intention. For example, non-indexable pages not submitted to Google will appear in the Excluded report.
 Screenshot from Google Search Console, May 2022
Screenshot from Google Search Console, May 2022
However, Google doesn’t always get it right and pages that should be indexed sometimes go to Excluded.
Fortunately, Google Search Console provides the reason for placing pages in a specific bucket.
This is why it’s a good practice to carefully review the pages in all four buckets.
Let’s now dive into the Excluded bucket.
Possible Reasons For Excluded Pages
There are 15 possible reasons your web pages are in the Excluded group. Let’s take a closer look at each one.
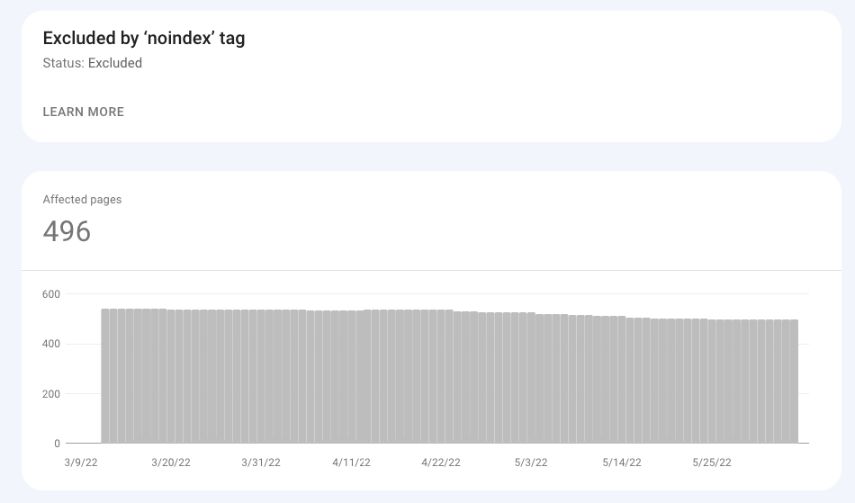
Excluded by “noindex” tag
These are the URLs that have a “noindex” tag.
Google thinks you actually want to exclude these pages from indexation because you don’t list them in the XML sitemap.
These may be, for example, login pages, user pages, or search result pages.
Suggested actions:
- Review these URLs to be sure you want to exclude them from Google’s index.
- Check if a “noindex” tag is still/actually present on those URLs.
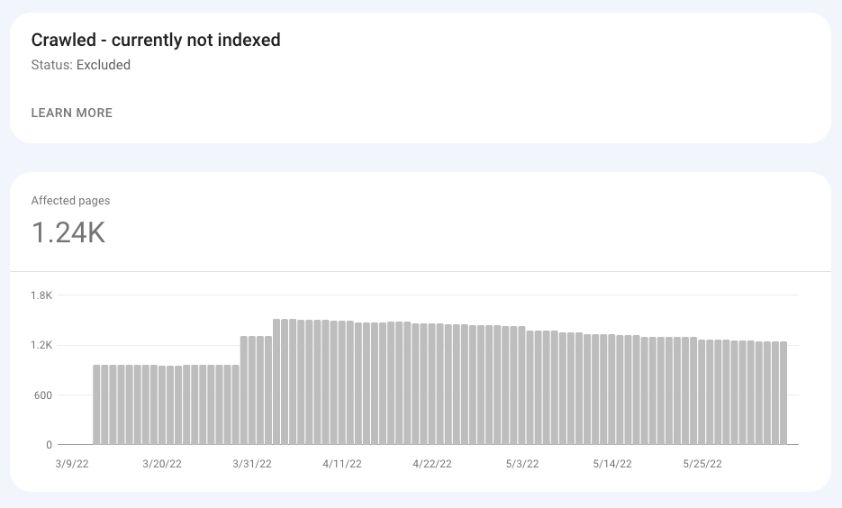
Crawled – Currently Not Indexed
Google has crawled these pages and still has not indexed them.
As Google says in its documentation, the URL in this bucket “may or may not be indexed in the future; no need to resubmit this URL for crawling.”
Many SEO pros noticed that a site might have some serious quality issues if many normal and indexable pages go under Crawled – currently not indexed.
This could mean Google has crawled these pages and does not think they provide enough value to index.
 Screenshot from Google Search Console, May 2022
Screenshot from Google Search Console, May 2022Suggested actions:
- Review your website in terms of quality and E-A-T.
Discovered – Currently Not Indexed
As Google documentation says, the page under Discovered – currently not indexed “was found by Google, but not crawled yet.”
Google did not crawl the page not to overload the server. A huge number of pages under this bucket may mean your site has crawl budget issues.
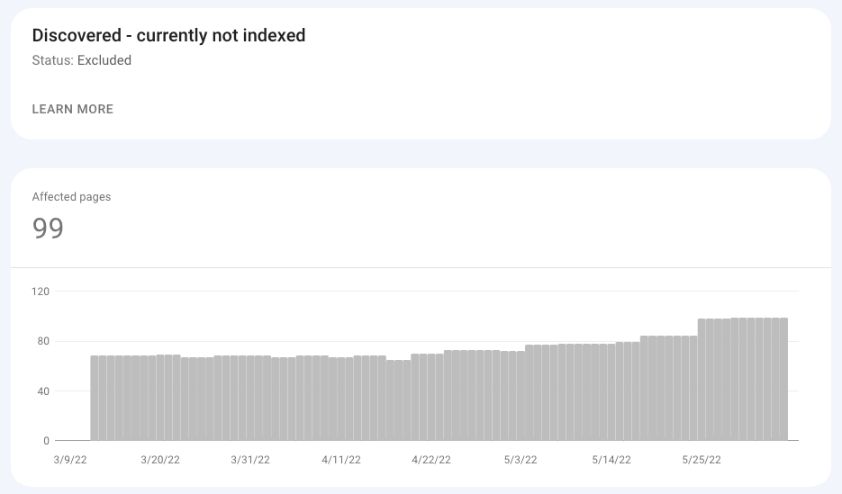 Screenshot from Google Search Console, May 2022
Screenshot from Google Search Console, May 2022Suggested actions:
- Check the health of your server.
Not Found (404)
These are the pages that returned status code 404 (Not Found) when requested by Google.
These are not URLs submitted to Google (i.e., in an XML sitemap), but instead, Google discovered these pages (i.e., through another website that linked to an old page deleted a long time ago.
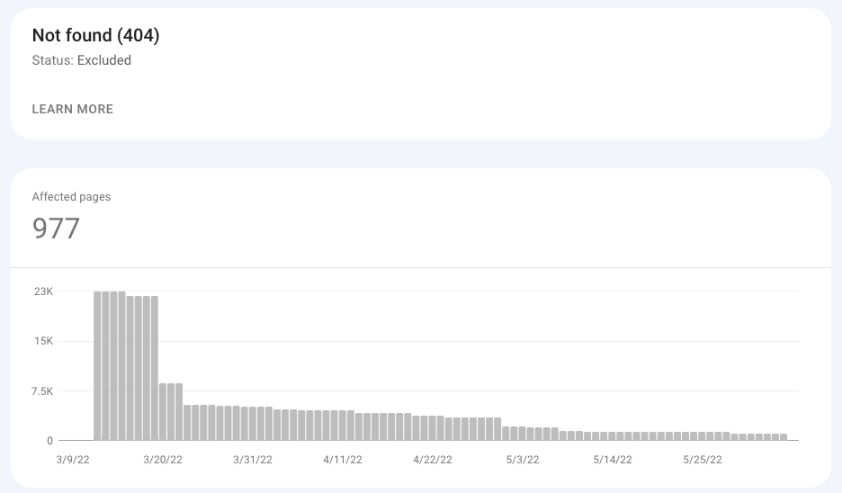 Screenshot from Google Search Console, May 2022
Screenshot from Google Search Console, May 2022Suggested actions:
- Review these pages and decide whether to implement a 301 redirect to a working page.
Soft 404
Soft 404, in most cases, is an error page that returns status code OK (200).
Alternatively, it can also be a thin page that contains little to no content and uses words like “sorry,” “error,” “not found,” etc.
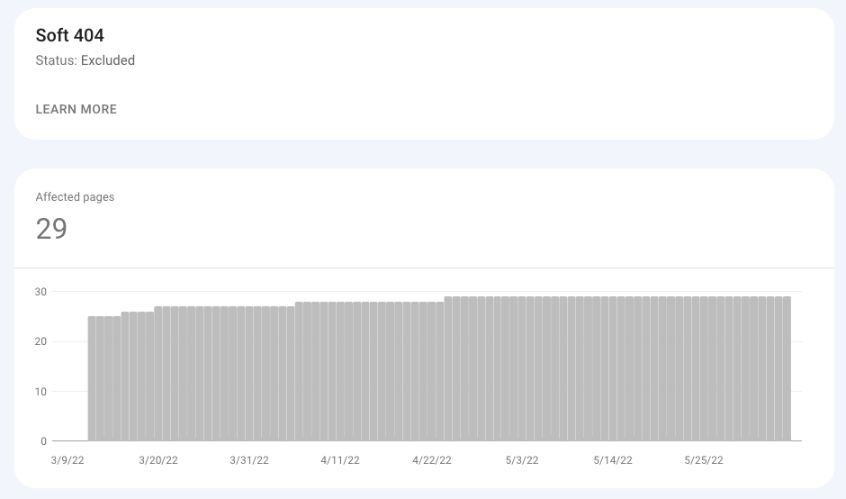 Screenshot from Google Search Console, May 2022
Screenshot from Google Search Console, May 2022Suggested actions:
- In the case of an error page, make sure to return status code 404.
- For thin content pages, add unique content to help Google recognize this URL as a standalone page.
Page With Redirect
All redirected pages on your website will go to the Excluded bucket, where you can see all redirected pages that Google detected on your website.
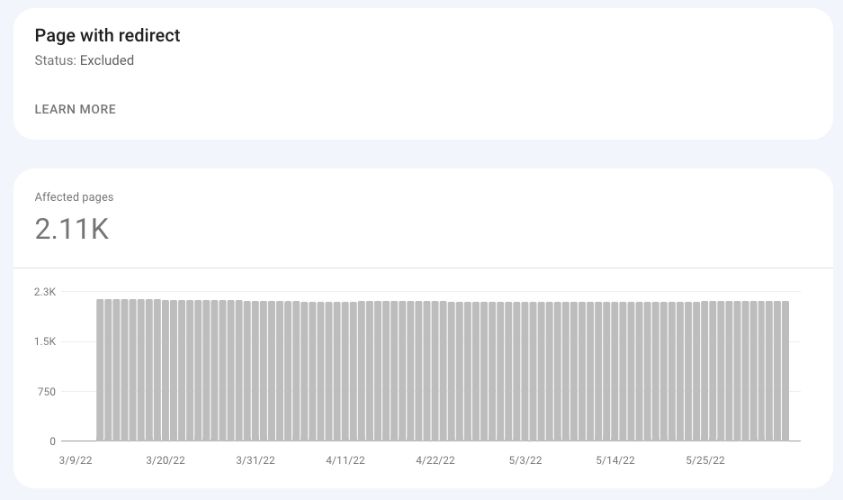 Screenshot from Google Search Console, May 2022
Screenshot from Google Search Console, May 2022Suggested actions:
- Review the redirected pages to make sure the redirects were implemented intentionally.
- Some WordPress plugins automatically create redirects when you change the URL, so you may want to review these occasionally.
Duplicate Without User-Selected Canonical
Google thinks these URLs are duplicates of other URLs on your website and, therefore, should not be indexed.
You did not set a canonical tag for these URLs, and Google selected the canonical based on other signals.
Suggested actions:
- Inspect these URLs to check what canonical URLs Google has selected for these pages.
Duplicate, Google Chose Different Canonical Than User
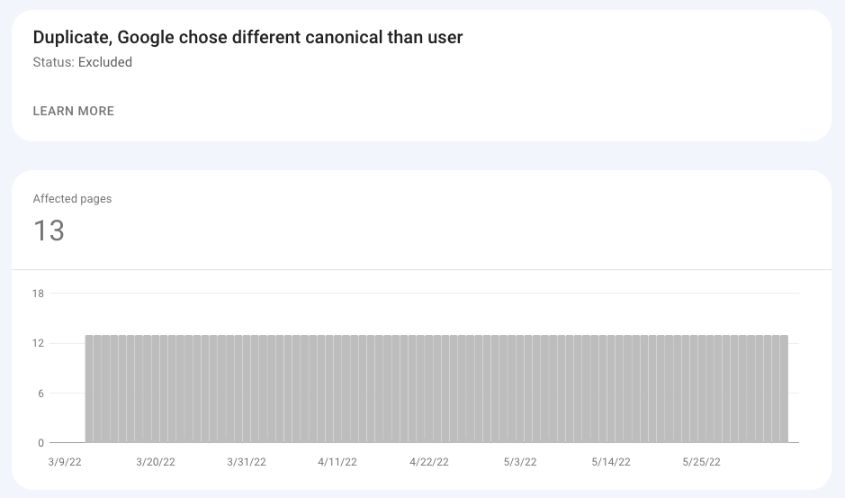 Screenshot from Google Search Console, May 2022
Screenshot from Google Search Console, May 2022In this case, you declared a canonical URL for the page, but even so, Google selected a different URL as the canonical. As a result, the Google-selected canonical is indexed, and the user-selected one is not.
Possible actions:
- Inspect the URL to check what canonical Google selected.
- Analyze possible signals that made Google choose a different canonical (i.e., external links).
Duplicate, Submitted URL Not Selected As Canonical
The difference between the above status and this status is that in the case of the latter, you submitted a URL to Google for indexation without declaring its canonical address, and Google thinks a different URL would make a better canonical.
As a result, the Google-selected canonical is indexed rather than the submitted URL.
Suggested actions:
- Inspect the URL to check what canonical Google has selected.
Alternate Page With Proper Canonical Tag
These are simply the duplicates of the pages that Google recognizes as canonical URLs.
These pages have the canonical addresses that point to the correct canonical URL.
Suggested actions:
- In most cases, no action is required.
Blocked By Robots.txt
These are the pages that robots.txt have blocked.
When analyzing this bucket, keep in mind that Google can still index these pages (and display them in an “impaired” way) if Google finds a reference to them on, for example, other websites.
Suggested actions:
- Verify if these pages are blocked using the robots.txt tester.
- Add a “noindex” tag and remove the pages from robots.txt if you want to remove them from the index.
Blocked By Page Removal Tool
This report lists the pages whose removal has been requested by the Removals tool.
Keep in mind that this tool removes the pages from search results only temporarily (90 days) and does not remove them from the index.
Suggested actions:
- Verify if the pages submitted via the Removals tool should be temporarily removed or have a ‘noindex’ tag.
Blocked Due To Unauthorized Request (401)
In the case of these URLs, Googlebot was not able to access the pages because of an authorization request (401 status code).
Unless these pages should be available without authorization, you don’t need to do anything.
Google is simply informing you about what it encountered.
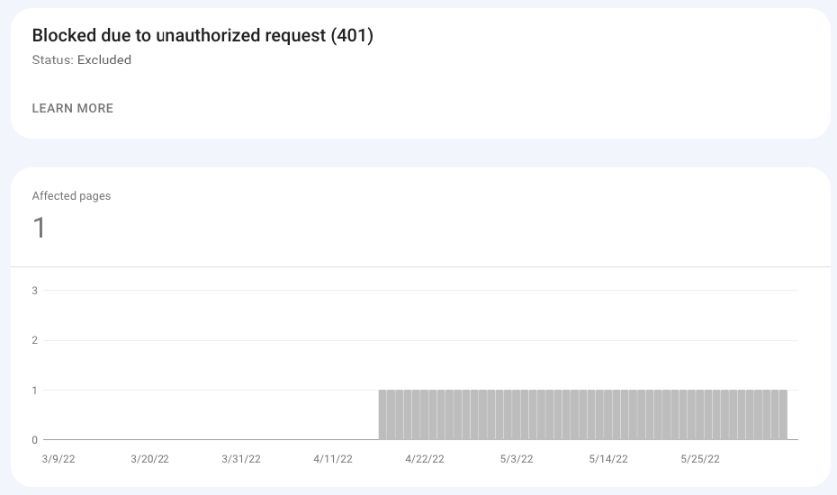 Screenshot from Google Search Console, May 2022
Screenshot from Google Search Console, May 2022Suggested actions:
- Verify if these pages should actually require authorization.
Blocked Due To Access Forbidden (403)
This status code is usually the result of some server error.
403 is returned when credentials provided are not correct, and access to the page could not be granted.
As Google documentation states:
“Googlebot never provides credentials, so your server is returning this error incorrectly. This error should either be fixed, or the page should be blocked by robots.txt or noindex.”
What Can You Learn From Excluded pages?
Sudden and huge spikes in a specific bucket of Excluded pages may indicate serious site issues.
Here are three examples of spikes that may indicate severe problems with your website:
- A huge spike in Not Found (404) pages may indicate unsuccessful migration where URLs have been changed, but redirects to new addresses have not been implemented. This may also happen after, for example, an inexperienced person changed the slug of blog posts and as a result, changed the URLs of all blogs.
- A huge spike in the Discovered – currently not indexed or Crawled – currently not indexed may indicate that your site has been hacked. Make sure to review the example pages to check if these are actually your pages or were created as a result of a hack (i.e., pages with Chinese characters).
- A huge spike in Excluded by ‘noindex’ tag may also indicate unsuccessful launch and migration. This often happens when a new site goes to production together with “noindex” tags from the staging site.
The Recap
You can learn a lot about your website and how Googlebot interacts with it, thanks to the Excluded section of the GSC Coverage report.
Whether you are a new SEO or already have a few years of experience, make it your daily habit to check Google Search Console.
This can help you detect various technical SEO issues before they turn into real disasters.
More resources:
- New Google Blog Series About Search Console & Data Studio
- Google I/O Search Console Update: New Report For Indexed Videos
- Advanced Technical SEO: A Complete Guide
Featured Image: Milan1983/Shutterstock
