
During my SEJ eSummit presentation, I introduced the idea of generating quality content at scale by answering questions automatically.
I introduced a process where we researched questions using popular tools.
But, what if we don’t even need to research the questions?
In this column, we are taking that process a significant step further.
We are going to learn how to generate high-quality question/answer pairs (and their corresponding schema) automatically.
Here is the technical plan:
- We will fetch content from an example URL.
- We will feed that content into a T5-based question/answer generator.
- We will generate a FAQPage schema object with the questions and answers.
- We will validate the generated schema and produce a preview to confirm it works as expected.
- We will go over the concepts that make this possible.
Generating FAQs from Existing Text
Let’s start with an example.
Make a copy of this Colab notebook I created to show this technique.
- Change the runtime to GPU and click connect.
- Feel free to change the URL in the form. For illustration purposes, I’m going to focus on this recent article about Google Ads hiding keyword data.
- The second input in the form is a CSS selector we are using to aggregate text paragraphs. You might need to change it depending on the page you use to test.
- After you hit Runtime > Run all, you should get a block of HTML that you can copy and paste into the Rich Results Test tool.
Here is what the rich results preview looks for that example page:
Completely automated.
How cool is that, right?
Now, let’s step through the Python code to understand how the magic is happening.
Fetching Article Content
We can use the reliable Requests-HTML library to pull content from any page, even if the content is rendered using JavaScript.
We just need a URL and a CSS selector to extract only the content that we need.
We need to install the library with:
!pip install requests-html
Now, we can proceed to use it as follows.
from requests_html import HTMLSession
session = HTMLSession()
with session.get(url) as r:
paragraph = r.html.find(selector, first=False)
text = " ".join([ p.text for p in paragraph])
I made some minor changes from what I’ve used in the past.
I request a list of DOM nodes when I specify first=False, and then I join the list by combining each paragraph by spaces.
I’m using a simple selector, p, which will return all paragraphs with text.
This works well for Search Engine Journal, but you might need to use a different selector and text extraction strategy for other sites.
After I print the extracted text, I get what I expected.

The text is clean of HTML tags and scripts.
Now, let’s get to the most exciting part.
We are going to build a deep learning model that can take this text and turn it into FAQs! 🤓
Google T5 for Question & Answer Generation
I introduced Google’s T5 (Text-to-Text Transfer Transformer) in my article about quality title and meta description generation.
T5 is a natural language processing model that can perform any type of task, as long as it takes input as text and output as text, provided you have the right dataset.
I also covered it during my SEJ eSummit talk, when I mentioned that the designers of the algorithm actually lost on a trivia contest!

Now, we are going to leverage the amazing work of researcher Suraj Patil.
He put together a high-quality GitHub repository with T5 fine-tuned for question generation using the SQuAD dataset.
The repo includes instructions on how to train the model, but as he already did that, we will leverage his pre-trained models.
This will saves us significant time and expense.
Let’s review the code and steps to set up the FAQ generation model.
First, we need to download the T5 weights.
!python -m nltk.downloader punkt
This will cause the python library nltk to download some files.
[nltk_data] Downloading package punkt to /root/nltk_data... [nltk_data] Unzipping tokenizers/punkt.zip.
Clone the repository.
!git clone https://github.com/patil-suraj/question_generation.git
%cd question_generation
At the time of writing this, I faced a bug and in the notebook I applied a temporary patch. See if the issue has been closed and you can skip it.
Next, let’s install the transformers library.
!pip install transformers
We are going to import a module that mimics the transformers pipelines to keep things super simple.
from pipelines import pipeline
Now we get to the exciting part that takes just two lines of code!
nlp = pipeline("multitask-qa-qg")
faqs = nlp(text)
Here are the generated questions and answers for the article we scraped.

Look at the incredible quality of the questions and the answers.
They are diverse and comprehensive.
And we didn’t even have to read the article to do this!
I was able to do this quickly by leveraging open source code that is freely available.
As impressive as these models are, I strongly recommend that you review and edit the content generated for quality and accuracy.
You might need to remove question/answer pairs or make corrections to keep them factual.
Let’s generate a FAQPage JSON-LD schema using these generated questions.
Generating FAQPage Schema
In order to generate the JSON-LD schema easily, we are going to borrow an idea from one of my early articles.
We used a Jinja2 template to generate XML sitemaps and we can use the same trick to generate JSON-LD and HTML.
We first need to install jinja2.
!pip install jinja2
This is the jinja2 template that we will use to do the generation.
faqpage_template="""<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{% for faq in faqs %}
{
"@type": "Question",
"name": {{faq.question|tojson}},
"acceptedAnswer": {
"@type": "Answer",
"text": {{faq.answer|tojson}}
}
}{{ "," if not loop.last }}
{% endfor %}
]
}
</script>"""
I want to highlight a couple of tricks I needed to use to make it work.
The first challenge with our questions is that they include quotes (“), for example:
Who announced that search queries without a "significant" amount of data will no longer show in query reports?
This is a problem because the quote is a separator in JSON.
Instead of quoting the values manually, I used a jinja2 filter, tojson to do the quoting for me and also escape any quotes.
It converts the example above to:
"Who announced that search queries without a \"significant\" amount of data will no longer show in query reports?"
The other challenge was that adding the comma after each question/answer pair works well for all but the last one, where we are left with a dangling comma.
I found another StackOverflow thread with an elegant solution for this.
{{ "," if not loop.last }}
It only adds the comma if it is not the last loop iteration.
Once you have the template and the list of unique FAQs, the rest is straightforward.
from jinja2 import Template
template=Template(faqpage_template) faqpage_output=template.render(faqs=new_faqs)
That is all we need to generate our JSON-LD output.
You can find it here.
Finally, we can copy and paste it into the Rich Results Test tool, validate that it works and preview how it would look in the SERPs.
Awesome.
Deploying the Changes to Cloudflare with RankSense
Finally, if your site uses the Cloudflare CDN, you could use the RankSense app content rules to add the FAQs to the site without involving developers. (Disclosure: I am the CEO and founder of RankSense.)
Before we can add FAQPage schema to the pages, we need to create the corresponding FAQs to avoid any penalties.
According to Google’s general structured data guidelines:
“Don’t mark up content that is not visible to readers of the page. For example, if the JSON-LD markup describes a performer, the HTML body should describe that same performer.”
We can simply adapt our jinja2 template so it outputs HTML.
faqpage_template=""" <div id="FAQTab">
{% for faq in faqs %}
<div id="Question"> {{faq.question}} </div>
<div id="Answer"> <strong>{{faq.answer}} </strong></div>
{% endfor %}
</div> """
Here is what the HTML output looks like.

Now, that we can generate FAQs and FAQPage schemas for any URLs, we can simply populate a Google Sheet with the changes.
My team shared a tutorial with code you can use to automatically populate sheets here.
Your homework is to adapt it to populate the FAQs HTML and JSON-LD we generated.
In order to update the pages, we need to provide Cloudflare-supported CSS selectors to specify where in the DOM we want to make the insertions.
We can insert the JSON-LD in the HTML head, and the FAQ content at the bottom of the Search Engine Journal article.
As you are making HTML changes and can potentially break the page content, it would be a good idea to preview the changes using the RankSense Chrome extension.
In case you are wondering, RankSense makes these changes directly in the HTML without using client-side JavaScript.
They happen in the Cloudflare CDN and are visible to both users and search engines.
Now, let’s go over the concepts that make this work so well.
How Does This T5-Based Model Generate These Quality FAQs?
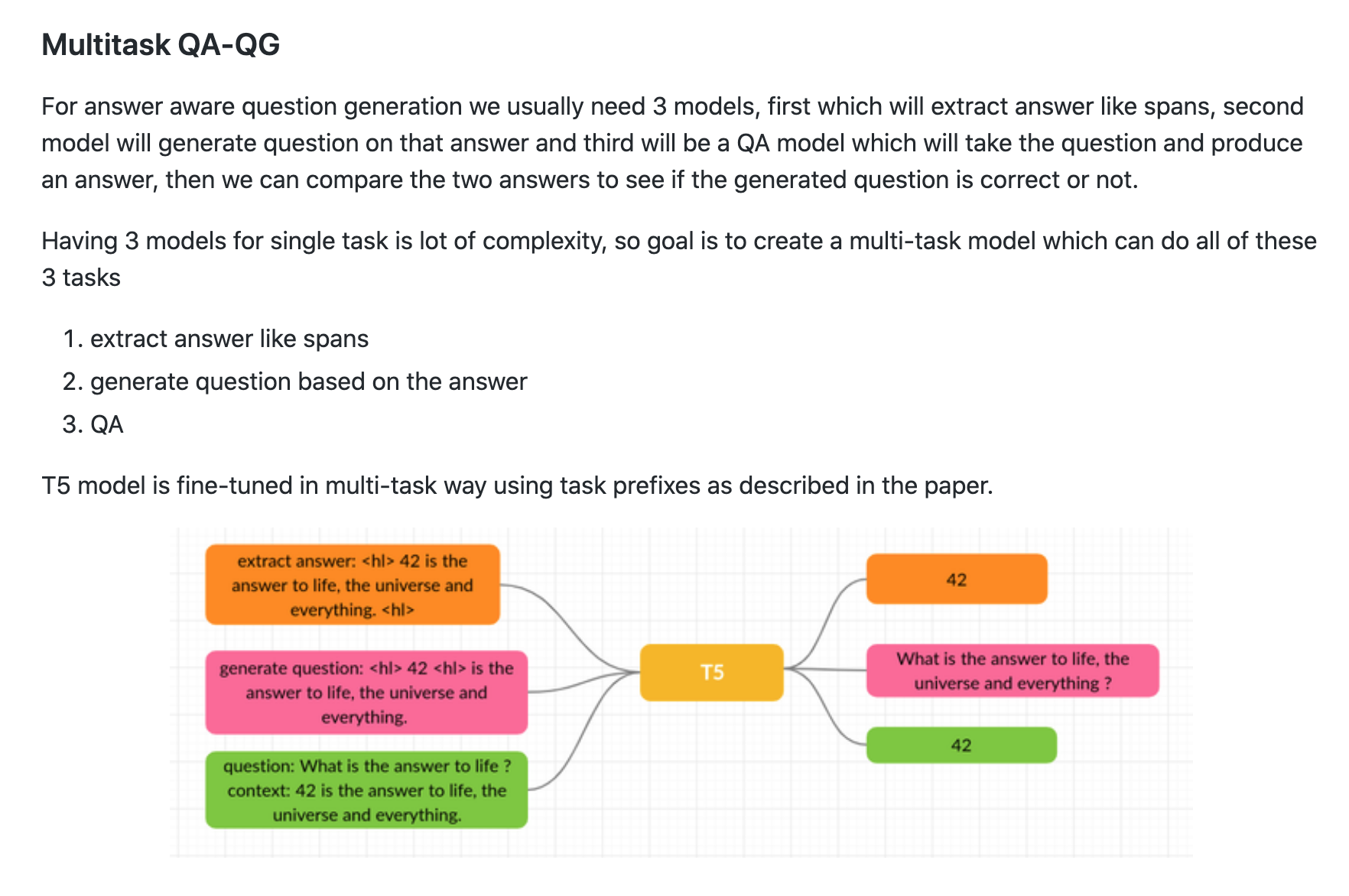
The researcher is using an answer-aware, neural question generation approach.
This approach generally requires three models:
- One to extract potential answers from the text.
- Another to generate questions given answers and the text.
- Finally, a model to take the questions and the context and produce the answers.
Here’s a useful explanation from Suraj Patil.
One simple approach to extract answers from text is to use Name Entity Recognition (NER) or facts from a custom knowledge graph like we built in my last column.
A question generation model is basically a question-answering model but with the input and target reversed.
A question-answering model takes questions+context and outputs answers, while a question-generation model takes answers+context and outputs questions.
Both types of models can be trained using the same dataset – in our case, the readily available SQuAD dataset.
Make sure to read my post for the Bing Webmaster Tools Blog.
I provided a fairly in-depth explanation of how transformer-based, question-answering models work.
It includes simple analogies and some minimal Python code.
One of the core strengths of the T5 model is that it can perform multiple tasks, as long as they take text and output text.
This enabled the researcher to train just one model to perform all tasks instead of three models.
Resources & Community Projects
The Python SEO community keeps growing with more rising stars appearing every month. 🐍🔥
Here are some exciting projects and new faces I learned about on Twitter.
Oh yea, this will be done by then!https://t.co/c1mSilB1Eh
— Dan Leibson (@DanLeibson) September 9, 2020
Discovered two great authors last week.
Greg Bernhardt produced a fantastic piece on my blog. He uses the Google Knowledge base api to check entities associated to his own site.https://t.co/YD8pAexVg8Also Daniel Heredia Meijiashttps://t.co/WsuaPJmxUn
— JC Chouinard (@ChouinardJC) September 9, 2020
Keyword Density and Entity Calculator (Python + Knowledge Base API)
I build a python script that merges all of the screaming frog reports and then highlights all the errors in the top line tab
— M.Marrero (@steaprok) September 9, 2020
I'm working on a @GoogleTrends Visualiser via PyTrends + (you guessed it!) @streamlit! 😉
— Charly Wargnier (@DataChaz) September 9, 2020
More Resources:
- How to Generate Structured Data Automatically Using Computer Vision
- How to Use Python to Monitor & Measure Website Performance
- Advanced Technical SEO: A Complete Guide
Image Credits
All screenshots taken by author, September 2020
