

Google’s John Mueller was asked in an SEO Office Hours podcast if blocking the crawl of a webpage will have the effect of cancelling the “linking power” of either internal or external links. His answer suggested an unexpected way of looking at the problem and offers an insight into how Google Search internally approaches this and other situations.
About The Power Of Links
There’s many ways to think of links but in terms of internal links, the one that Google consistently talks about is the use of internal links to tell Google which pages are the most important.
Google hasn’t come out with any patents or research papers lately about how they use external links for ranking web pages so pretty much everything SEOs know about external links is based on old information that may be out of date by now.
What John Mueller said doesn’t add anything to our understanding of how Google uses inbound links or internal links but it does offer a different way to think about them that in my opinion is more useful than it appears to be at first glance.
Impact On Links From Blocking Indexing
The person asking the question wanted to know if blocking Google from crawling a web page affected how internal and inbound links are used by Google.
This is the question:
“Does blocking crawl or indexing on a URL cancel the linking power from external and internal links?”
Mueller suggests finding an answer to the question by thinking about how a user would react to it, which is a curious answer but also contains an interesting insight.
He answered:
“I’d look at it like a user would. If a page is not available to them, then they wouldn’t be able to do anything with it, and so any links on that page would be somewhat irrelevant.”
The above aligns with what we know about the relationship between crawling, indexing and links. If Google can’t crawl a link then Google won’t see the link and therefore the link will have no effect.
Keyword Versus User-Based Perspective On Links
Mueller’s suggestion to look at it how a user would look at it is interesting because it’s not how most people would consider a link related question. But it makes sense because if you block a person from seeing a web page then they wouldn’t be able to see the links, right?
What about for external links? A long, long time ago I saw a paid link for a printer ink website that was on a marine biology web page about octopus ink. Link builders at the time thought that if a web page had words in it that matched the target page (octopus “ink” to printer “ink”) then Google would use that link to rank the page because the link was on a “relevant” web page.
As dumb as that sounds today, a lot of people believed in that “keyword based” approach to understanding links as opposed to a user-based approach that John Mueller is suggesting. Looked at from a user-based perspective, understanding links becomes a lot easier and most likely aligns better with how Google ranks links than the old fashioned keyword-based approach.
Optimize Links By Making Them Crawlable
Mueller continued his answer by emphasizing the importance of making pages discoverable with links.
He explained:
“If you want a page to be easily discovered, make sure it’s linked to from pages that are indexable and relevant within your website. It’s also fine to block indexing of pages that you don’t want discovered, that’s ultimately your decision, but if there’s an important part of your website only linked from the blocked page, then it will make search much harder.”
About Crawl Blocking
A final word about blocking search engines from crawling web pages. A surprisingly common mistake that I see some site owners do is that they use the robots meta directive to tell Google to not index a web page but to crawl the links on the web page.
The (erroneous) directive looks like this:
<meta name=”robots” content=”noindex” <meta name=”robots” content=”noindex” “follow”>
There is a lot of misinformation online that recommends the above meta description, which is even reflected in Google’s AI Overviews:
Screenshot Of AI Overviews
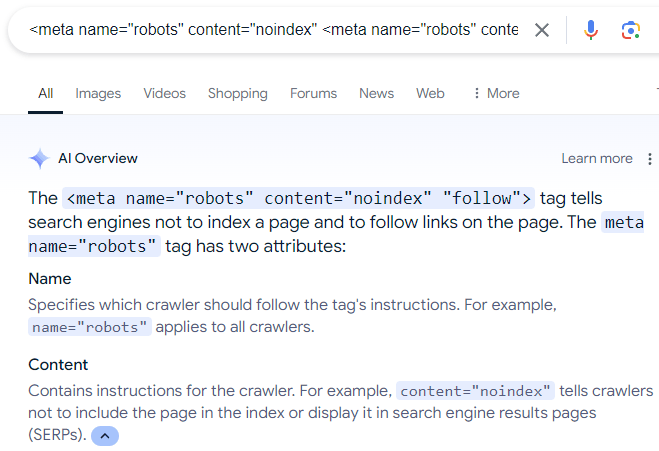
Of course, the above robots directive does not work because, as Mueller explains, if a person (or search engine) can’t see a web page then the person (or search engine) can’t follow the links that are on the web page.
Also, while there is a “nofollow” directive rule that can be used to make a search engine crawler ignore links on a web page, there is no “follow” directive that forces a search engine crawler to crawl all the links on a web page. Following links is a default that a search engine can decide for themselves.
Read more about robots meta tags.
Listen to John Mueller answer the question from the 14:45 minute mark of the podcast:
Featured Image by Shutterstock/ShotPrime Studio
