
It hadn’t occurred to me in quite these terms before, but Google has an algorithm for its Knowledge Graph.
I have been tracking the Knowledge Graph API for five years. The resultScores have always been rising slightly in a pretty stable manner.
But Google updated the algorithm in the summer of 2019. Big time.
REALLY, REALLY big time.
How this major update affects the search ecosystem is yet to be determined.
But this may prove to be a turning point both for Google and for us as digital marketers.
In this article, I will explain what I am tracking, how I am tracking it, make some observations about the data above, and throw a few theories out.
Please remember that this is new and that I am simply commenting on my observations. My aim here is to start a conversation. 🙂
Pinging the Knowledge Graph API
I have been collecting the information the Knowledge Graph API returns for five years now.
Since early 2019, I have collected all the information Google’s Knowledge Graph API returns for 7,504 brands and 4,069 more-or-less famous people.
Nothing more complex than collecting exactly what the API returns. All figures below include all brands and people I track.
The API returns a list of entities that it associates with the string I ping it with. In this case, the brand names.
Often it returns nothing. Sometimes just one entity. Sometimes a dozen or more entities.
When it returns multiple entities, they are ordered by a score – resultScore – that I refer to as “salience”.
The first result in the list of entities it returns is what Google considers to be the most relevant.
In what sense the most relevant?
My reading is that the resultScore / salience score measures two things:
- How confident Google is that this is the entity we are referring to with the query (i.e., has it matched the string of characters to the entity).
- In the case of ambiguity, which entity is the most probable candidate according to Google’s perception of intent.
- In the case that it is not the entity that corresponds directly to the query, how close the relationship is between the entities.
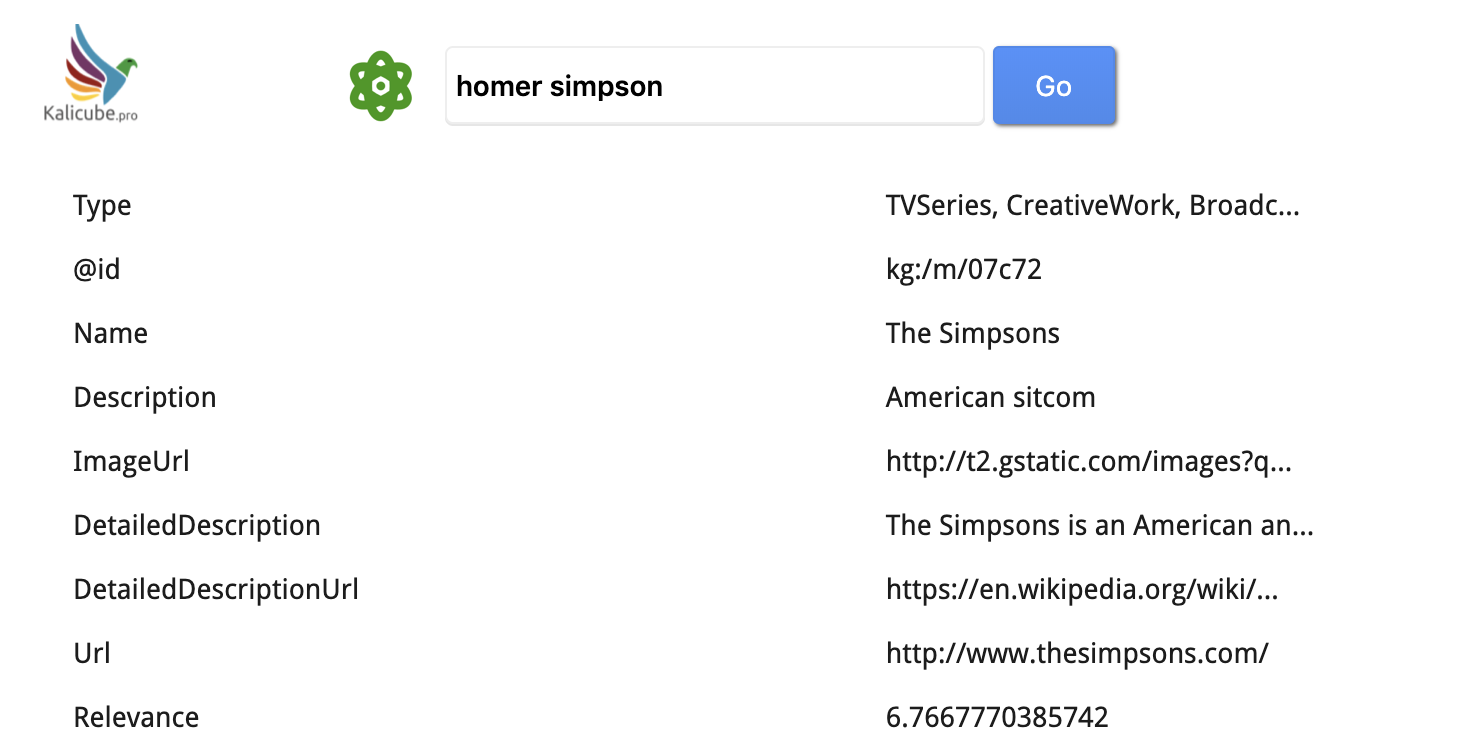
Here Is the Result for Homer Simpson
Primary Entity (Most Probable)
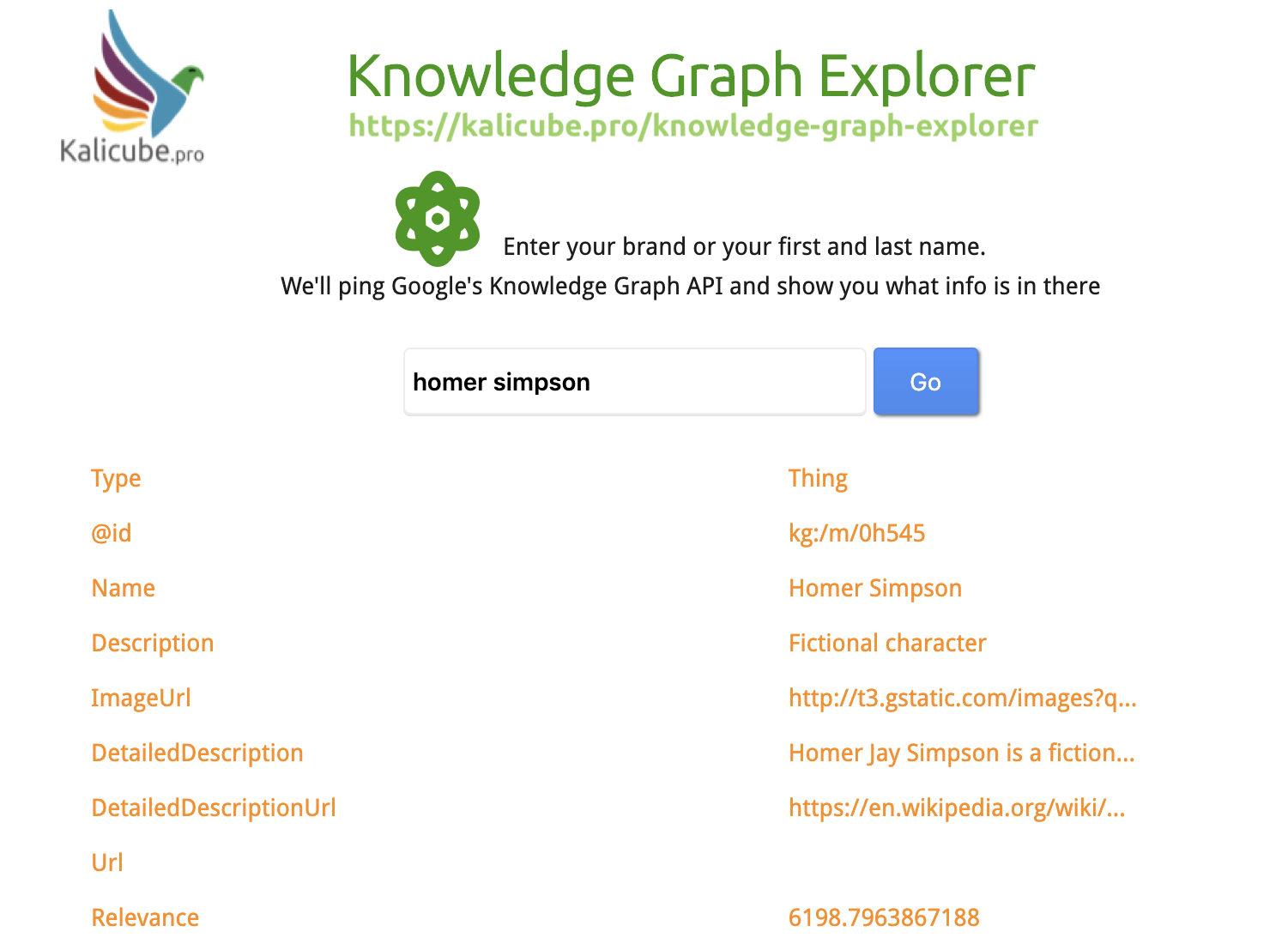
Secondary (Less Probable) Entity
And here is a sub-result / alternative entity for the exact same query – the salience score is much lower.
Google has seen that the string of characters does refer to this entity, but that the probability we mean this entity is significantly lower than the fictional character.
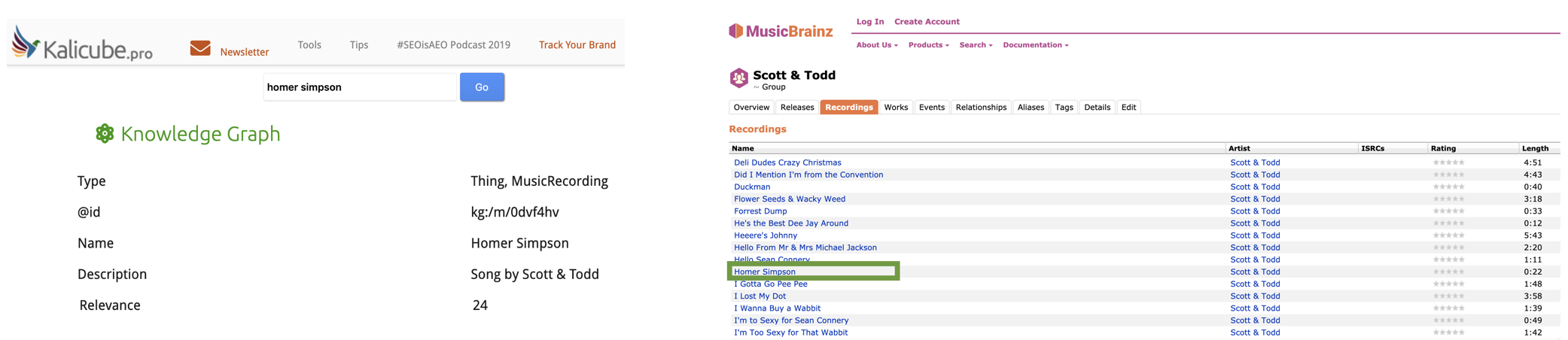
There are actually five songs called Homer Simpson in the Knowledge Graph – for fun informational purposes (and to push home(r) the incredible problems Google faces with ambiguity), here are the artists:
- DJ Bomberjack
- Scott & Todd
- BeebleBrox
- The Death Killers
- Feva Da General
Related Entity
Homer Simpson is related to The Sitcom “The Simpsons”.
Obviously this is the information for the TV series, but the salience score is for “The Simpsons” within the context of the query “Homer Simpson” (for the query “The Simpsons”, the salience score is 16,200).
Play with the Knowledge Graph API here.
For an example of a Knowledge Graph entry that has many related entities that are well defined and clear, have a look at Wordlift (a tool that explicitly sets out to “educate” the Knowledge Graph, and does it very well, it seems).
What Do These resultScores / Salience Scores ‘Mean’?
Salience scores could be considered to be confidence scores. Confidence that the string indeed refers to the named entity.
It is important to note that these salience scores are not representative of how Google search uses this data to build the SERPs.
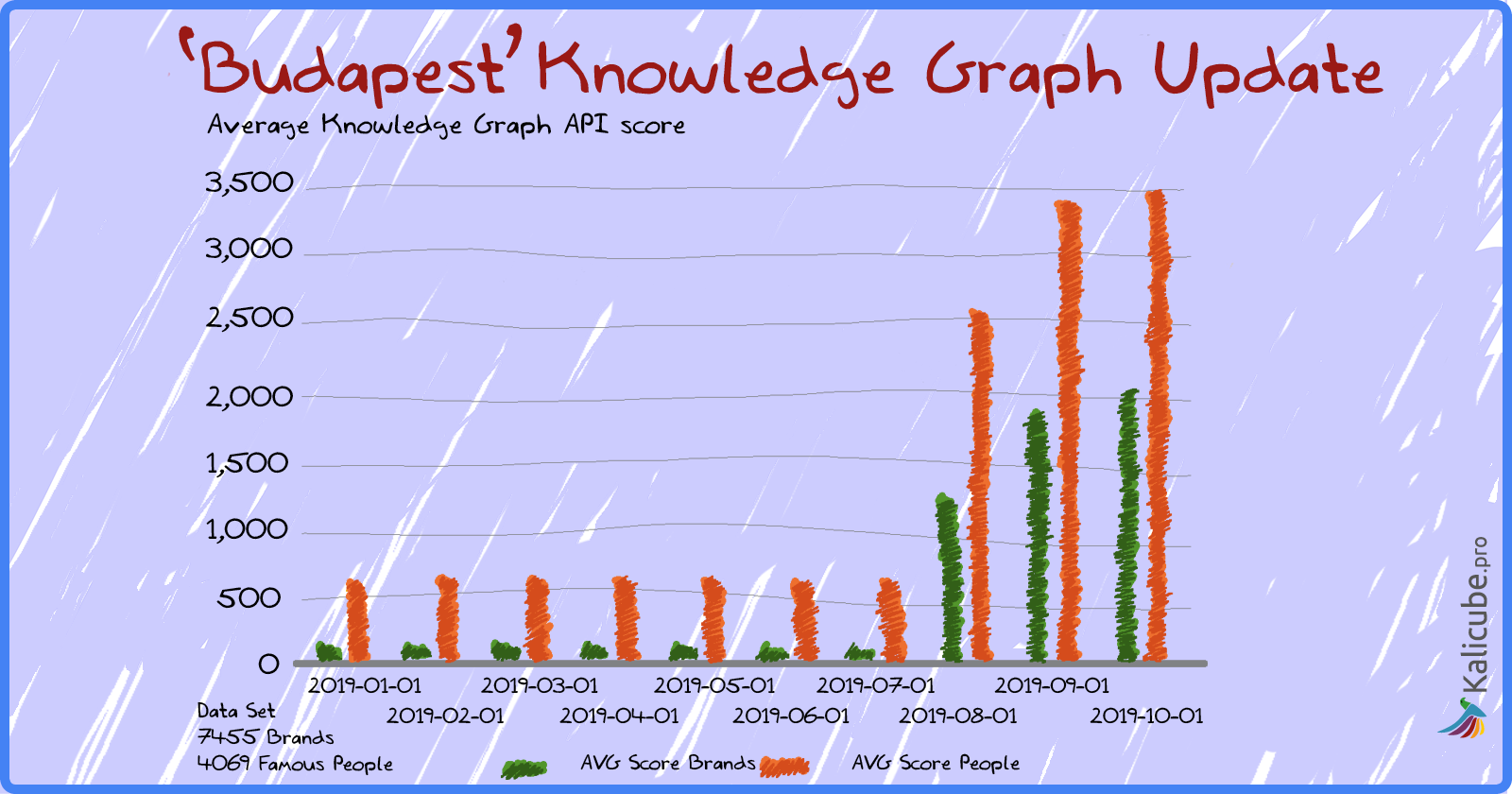
Salience Scores Have ‘Traditionally’ Been Fairly Stable
Typical Salience Scores up to Summer 2019
Typical scores for brand names were in the 10s for smaller brands, and 1,000 to 3,000 for more recognized brands.
For people, those scores tended to be more in the hundreds.
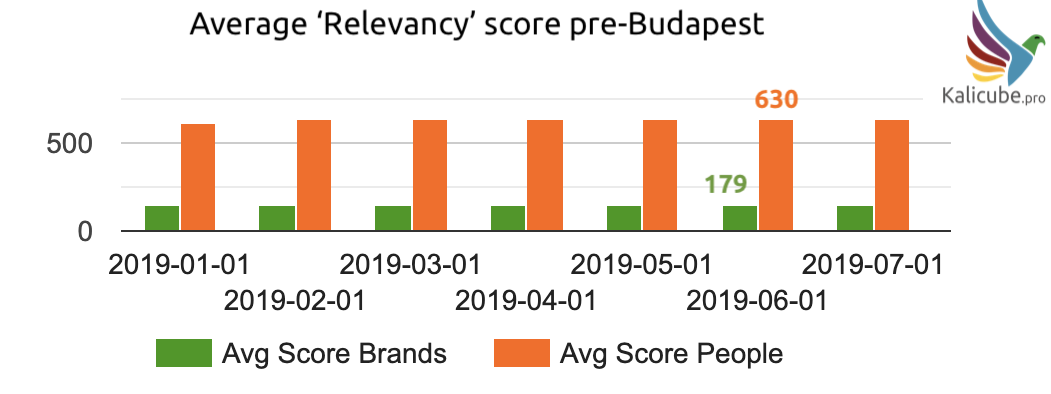
Before July 2019, the average salience scores were changing very little.
Rising by such a small amount that it is hard to see in the graph below – in the 1% to 5% range.
Here are the averages before summer 2019.
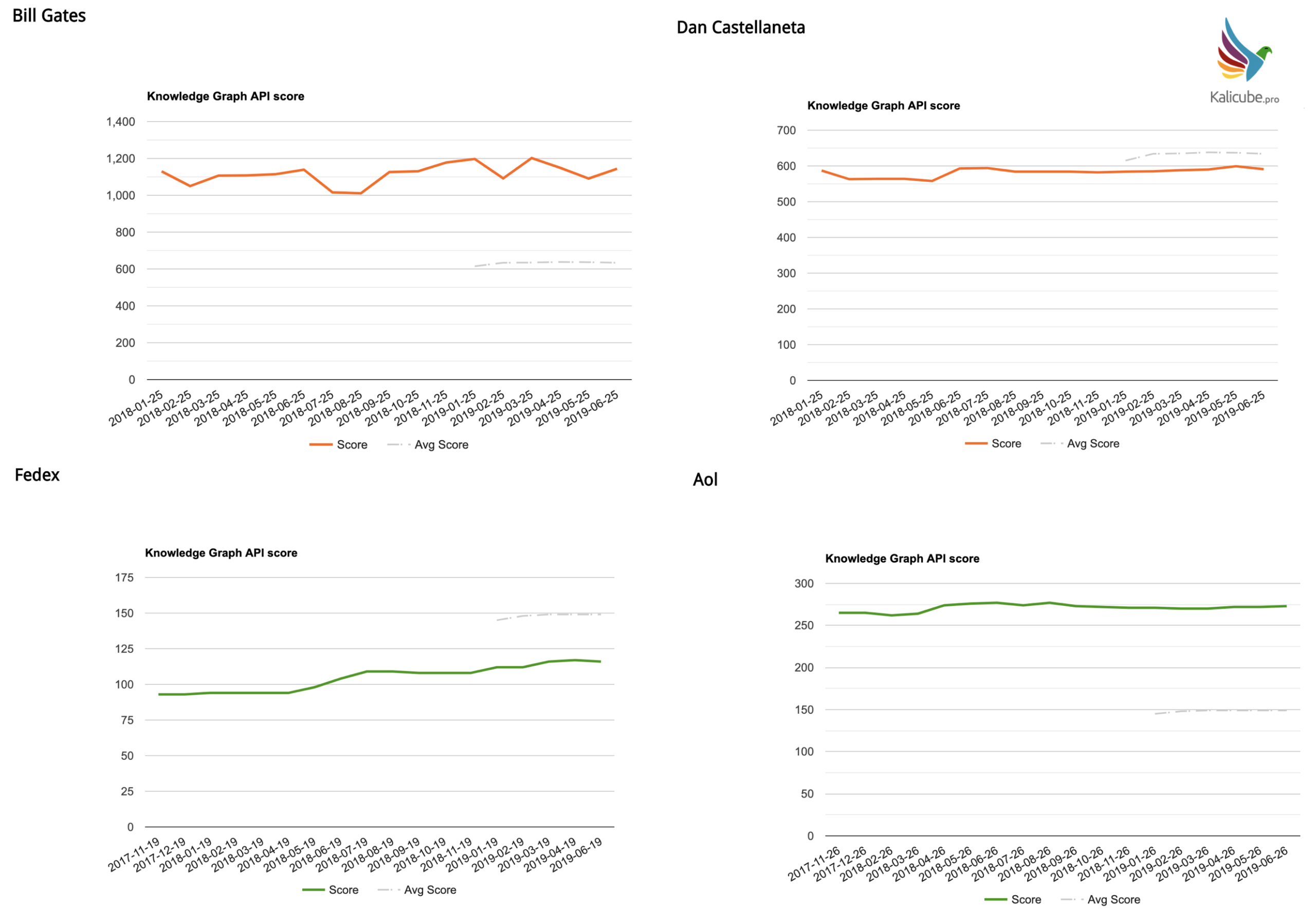
Below are a few examples for individual brands and people.
Month on month we are looking at changes of 1%, 5 %, maybe 10% absolute tops.
Improving Salience Scores Is Possible
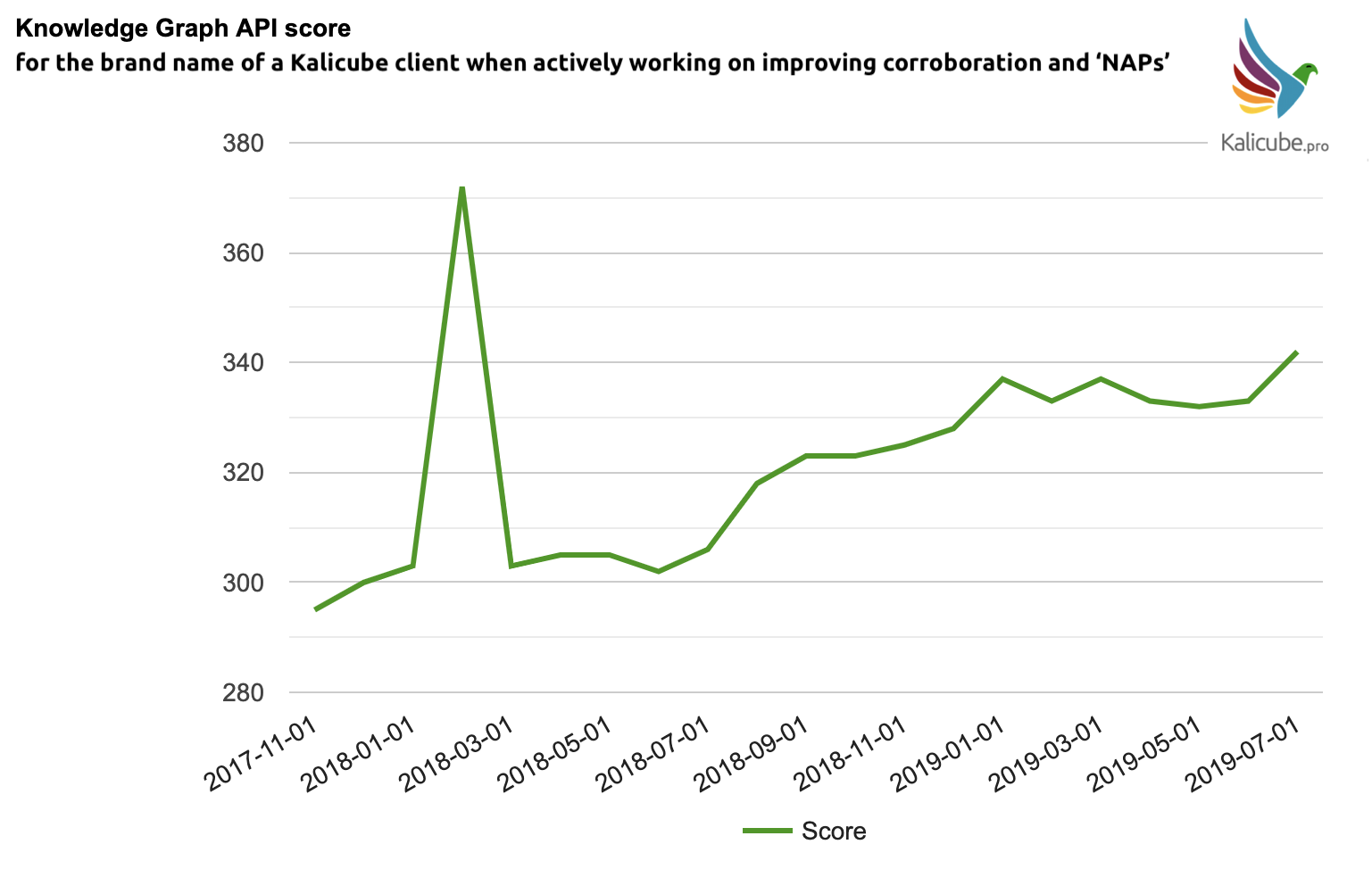
Actively working to improve the salience scores appears to work.
On the brands I have actively worked on, the score has tended to increase as we added more corroboration.
With an average score in the tens or hundreds, the increases I have managed to achieve have been a percentage point or two. Never anything drastic.
My clients have asked to remain anonymous. So here is one with the name redacted.
I have a good idea about the volume, placement, and timing of the corroboration.
The steady increase over two years corresponds to active work aimed at increasing corroboration on third sites such as Crunchbase, Wikidata, industry sites, and associating the brand with events, C-level employees, products, partners that are in the Knowledge Graph (including improving their salience scores).
A Score Can Drop
Why might a score drop?
In the case of a non-ambiguous name, my guess is that to maintain salience in the Knowledge Graph there is a concept of fresh corroboration.
If that is the case, unless your brand generates fresh third-party corroboration naturally, the salience score will tend to drop.
Here is a client who lost faith in the process of actively aiming to accumulate third-party corroboration.
This is obviously anecdotic but definitely worth thinking about.
We could equate this with link building (i.e., obtain third party corroboration to strengthen one’s position in the Knowledge Graph much like how links build PageRank… but with an additional “freshness” aspect to consider).
Ambiguity & Salience Scores
With ambiguous names such as mine or another entity with the same name (in this case Jason Barnard, the footballer, the podcaster, the dentist, the ice hockey player, the gravity juggler, the baseball coach, the disk golfer… ), gaining or losing in salience / importance / notoriety / mentions would affect the salience scores for all name-doppelgangers.
So be careful when a name / string of characters is ambiguous – those rises and falls are affected by the other entities with the same name as well as any corroboration you might be obtaining.
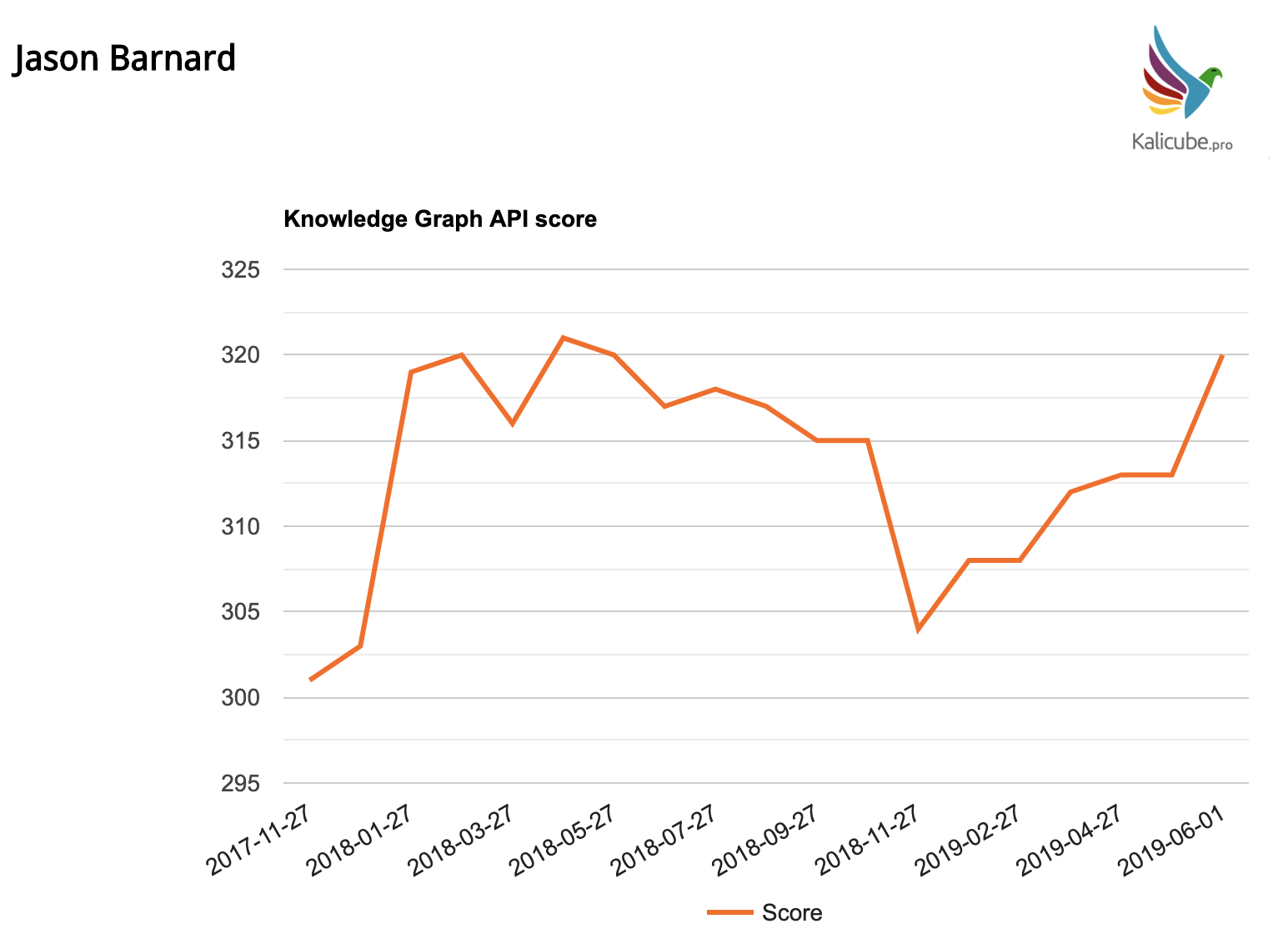
Further, unambiguous names will tend to have higher salience score than ambiguous ones (name your brand wisely). 🙂
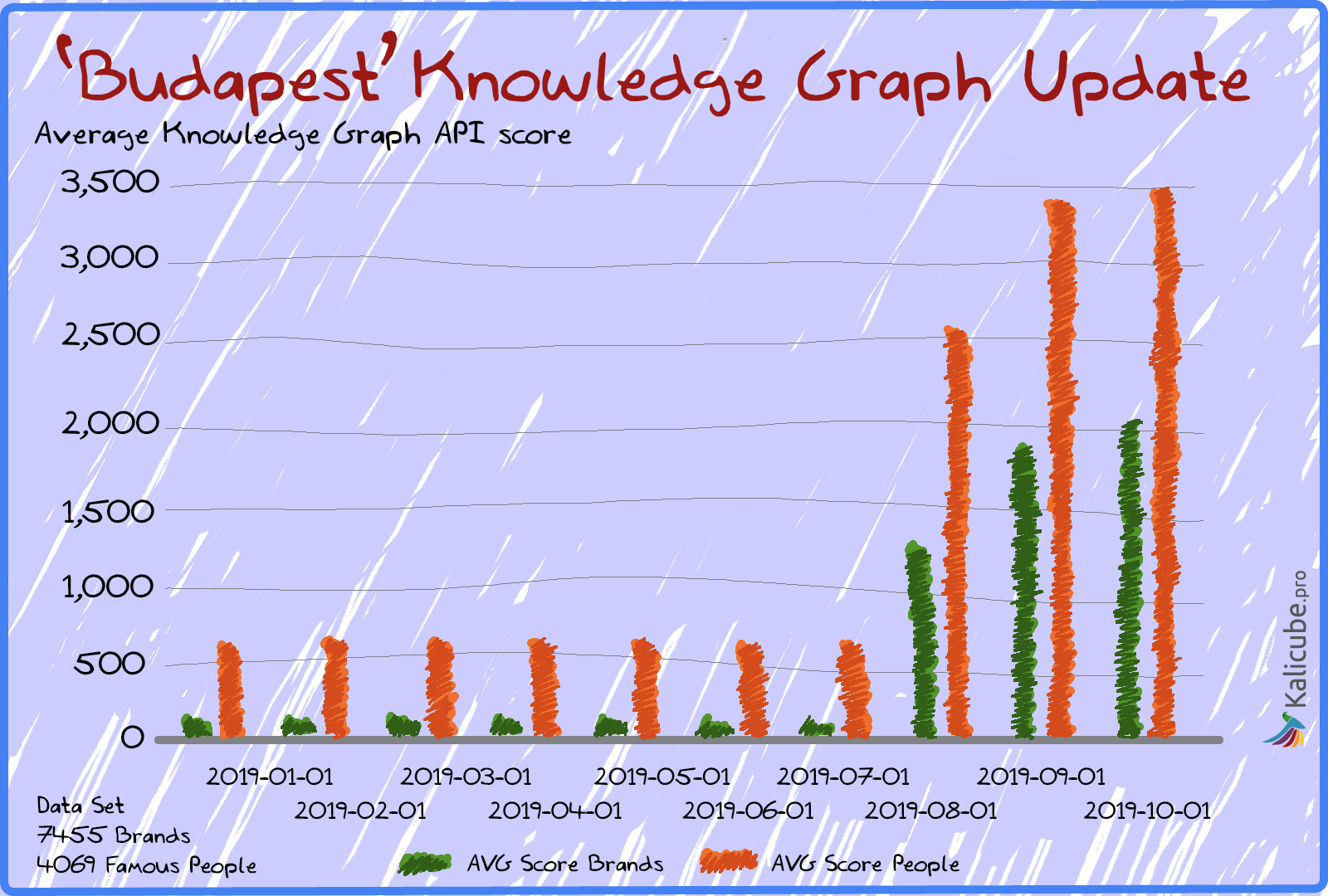
The Exciting Part: Summer 2019 = Stunning Knowledge Graph Algo Update – a.k.a. Budapest
In July/August 2019, two things changed.
- These salience scores went wild. The average went through the roof (note – my dataset did not change). Some big, big winners, some smaller winners, but also some losers.
- The number of entities returning something from the Knowledge Graph API went up.
Confidence / Salience Scores
- Salience scores for People increased five-fold.
- Salience scores for Brands increased 14-fold.
- Salience score for brands increased almost 3 times more than for people
- Average Salience score for brands overtook people.
- This seems to me to be the single most important takeaway from this update. Brands are now front and center in the Knowledge Graph.
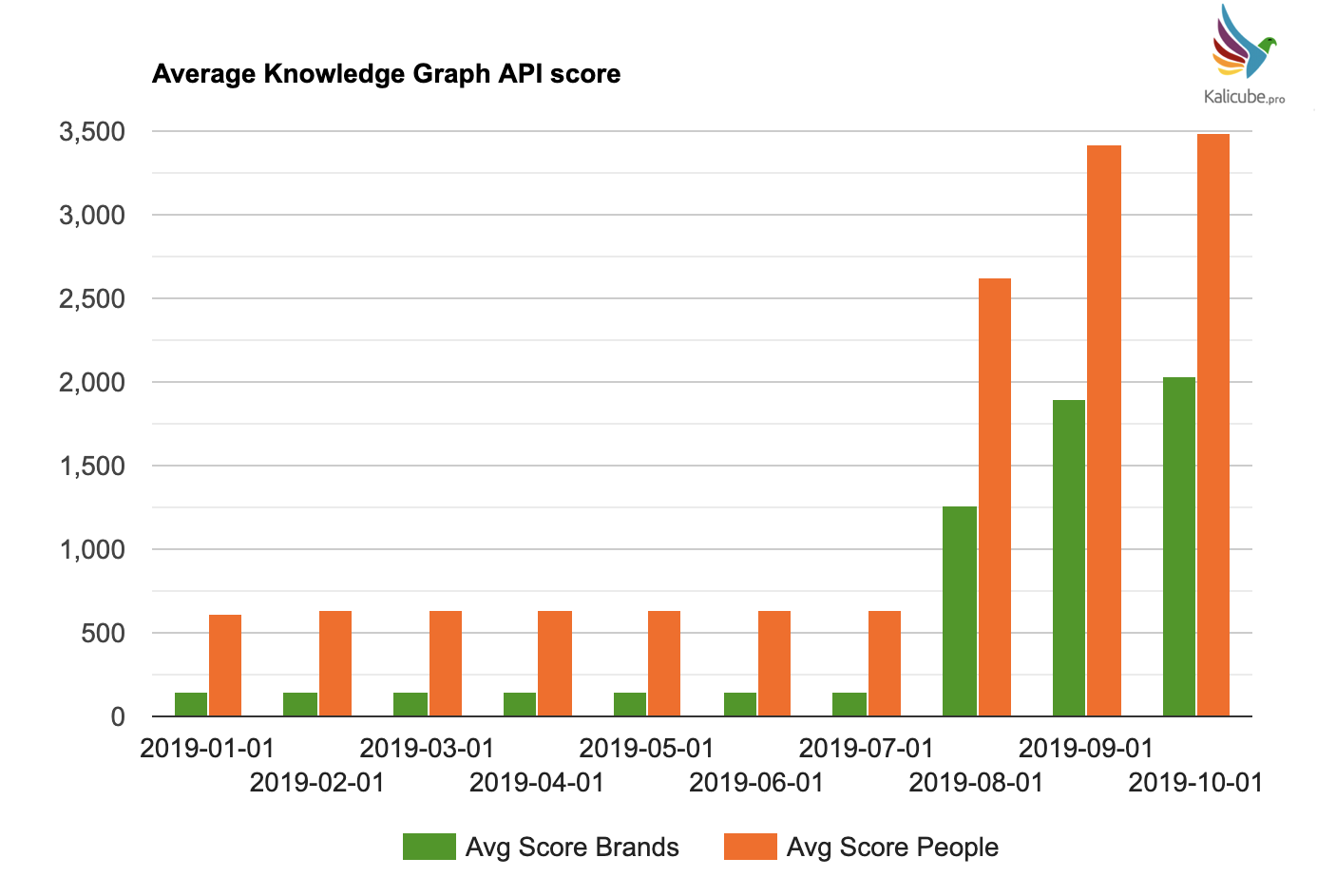
These are big numbers.
Hard to believe.
But I have checked, double-checked, and checked again.
Size / Number of Entities Present
Big changes here, too.
The number of brands with a place in the Knowledge Graph has increased by more than 42%.
The 7,504 brands are a pretty random bunch. A good spread of household names and lesser-known. So this seems to me to be a significant insight.
Google has more entities in the Knowledge Graph, or at least is significantly more confident in its ‘query string -> entity’ matching.
For people, the data is unfortunately biased.
The 4,069 people I have been tracking are mostly famous.
There is still a visible increase in August (a 3% increase to be exact), but since 99% of named entities already returned a result, on its own I would not have got excited about this.
It does make for good supporting evidence that the Knowledge Graph now contains a lot more entities than before the summer.
The impressive rise in brands returning something does indicate a significant increase in the size of the Knowledge Graph.
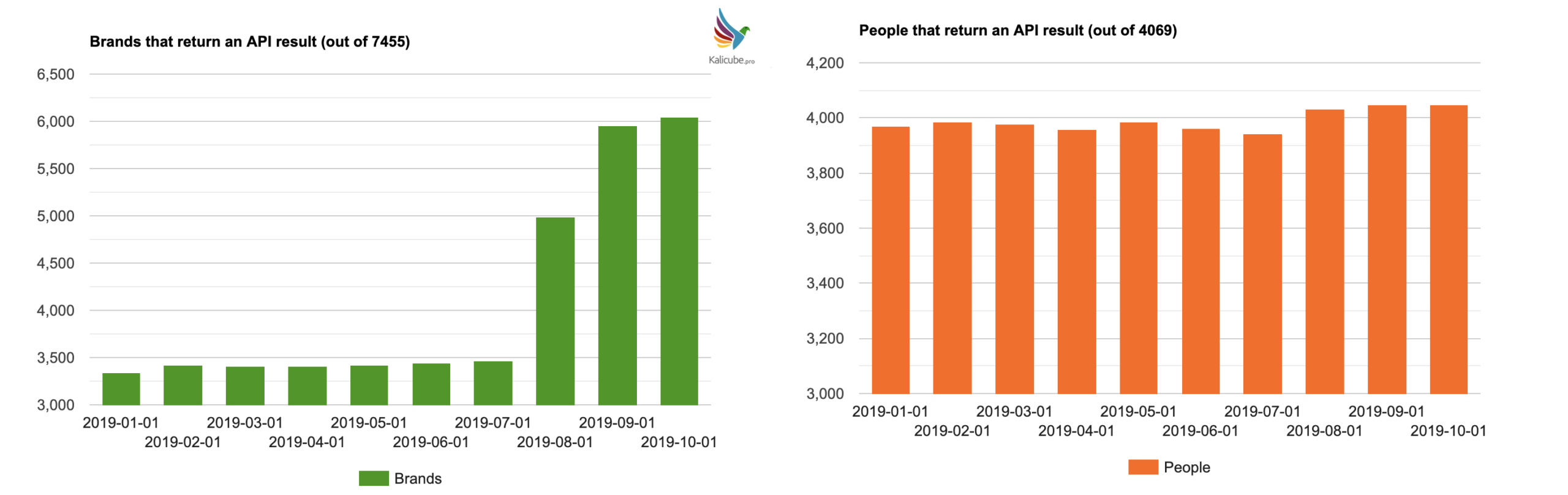
How often do we get a dataset that changes this radically, this quickly?
How exciting is that?
Key Factors in Salience: Popularity, Brand Awareness & Freshness
Popularity / Probability (So Much Finally Comes down to Probability)
It appears that the volume of references to (and potentially user behavior around results pertaining to…) an entity has become a much more important factor.
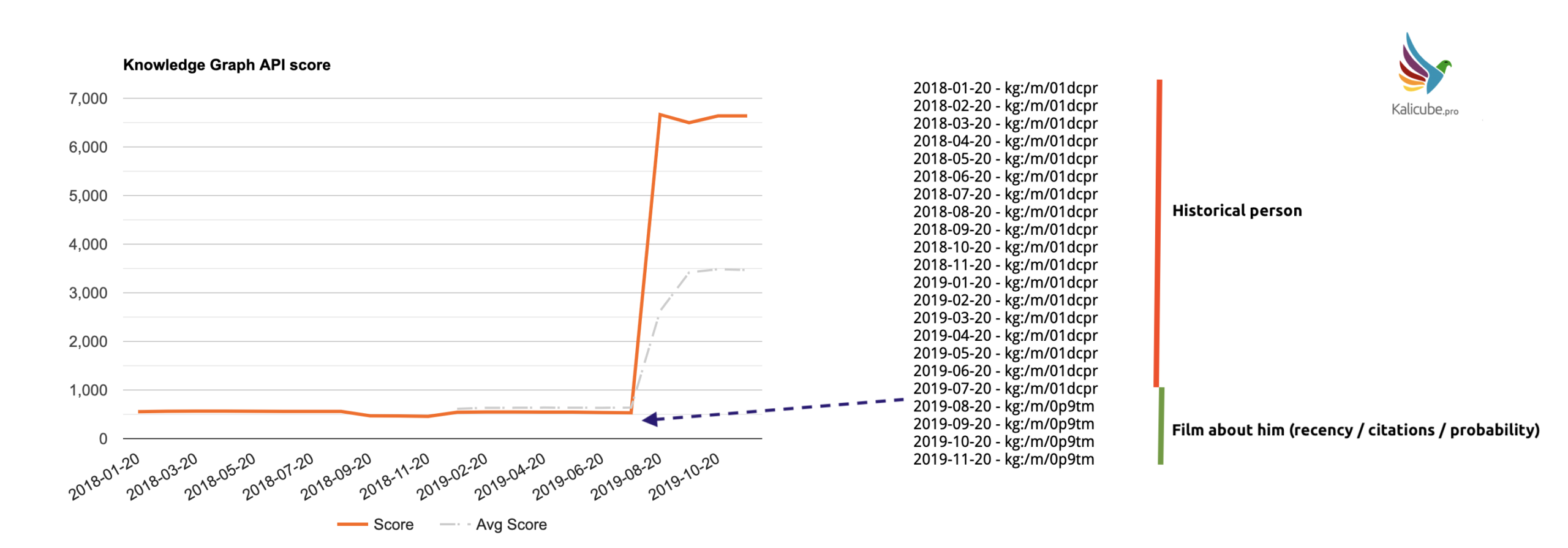
Looking at “Butch Cassidy”, before the summer, the highest salience was given to the historical person. Since the update, the film has taken over.
I would guess that is because there is a significantly larger volume of online references, possibly a more recent / fresh buzz (and possibly an analysis of historical search and click data).
Here we can see that the person was the most relevant until the update, and the film now dominates significantly.
Fresh and relevant citations, user behavior being brought to bear.
Very interesting.
Personally, I can’t get my head around this.
For info, the salience score for the person dropped from 535 to 330).
Brand Awareness (a.k.a. The Homer Effect)
Homer Simpson vs. Dan Castellaneta – a superb example of differing brand awareness for the same ‘thing’ (sorry Dan).
Homer Simpson = very strong brand awareness… and the salience score jumped tenfold.
Dan Castellaneta (the most directly related brand possible that the wider public knows less well) jumped “only” fourfold. The character is cited more often and on more trusted sources than the actor.
That is a lovely comparison that indicates beautifully the importance of brand awareness in this iteration of the Knowledge Graph.
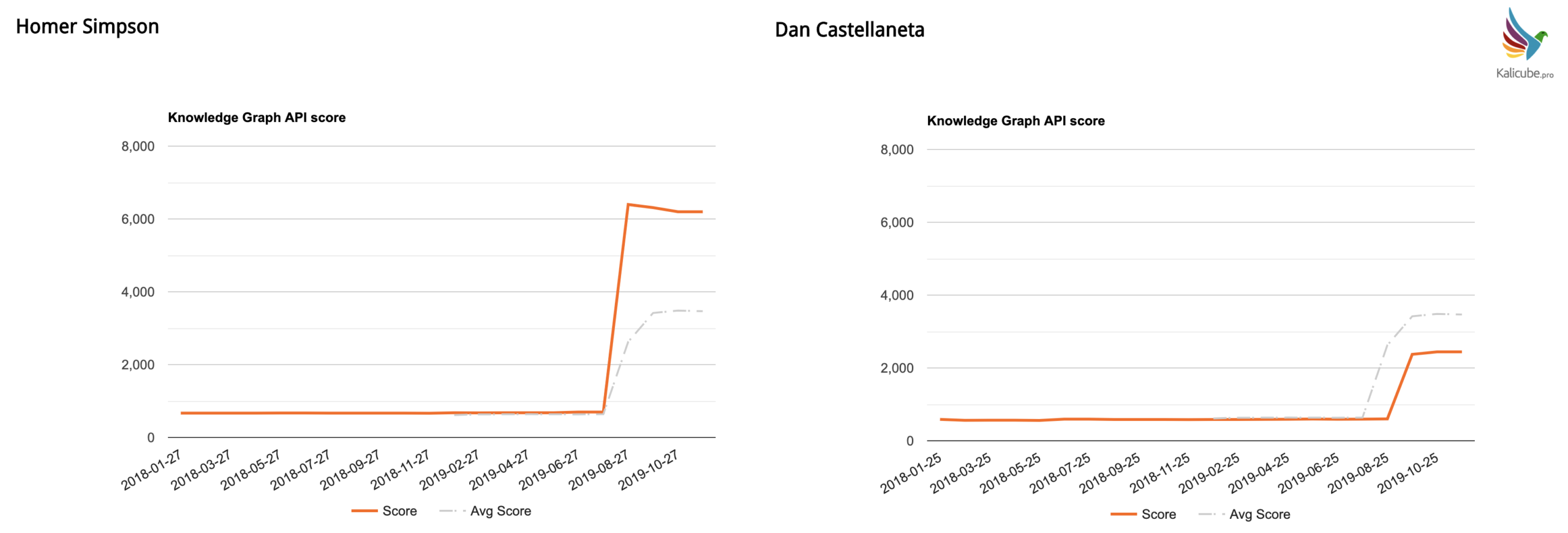
It is super important to remember that in comparison, Dan fell behind… But both these scores changed very significantly.
The Knowledge Graph just switched gear (perhaps 5 gears!).
Please do consider the following examples.
Not everyone is a winner.
Freshness / Citation Recency
It also seems that people and brands who have less fresh citations, or a lack of growth in citations, did not benefit from this update.
Looking at deceased actors… those who are “less-legendary” / “less-iconic” lose ground (a decrease in score).
Those who might be considered legendary beat the averages by a significant amount.
Perhaps this is because legends are regularly cited, and remain eternally “fresh” (even 60 years after their death).
Quantity and quality of recent citations appear to have immense importance in this update.
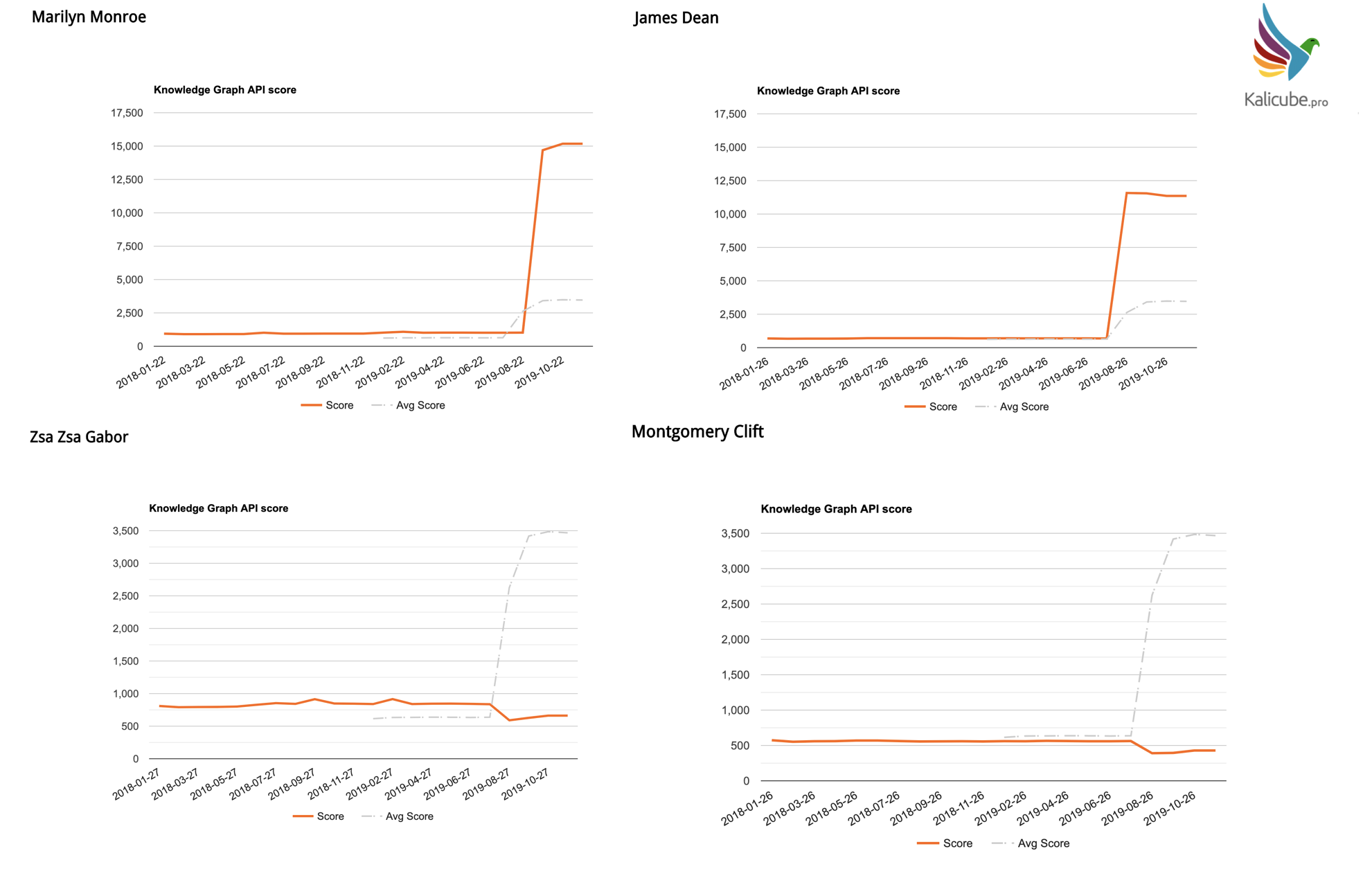
A Little Debate
Here are the big tech companies (sorry, I didn’t track Amazon).
They all see way above average jumps in salience scores. Seems to me that is logical.
References to them are fresh, numerous, and in sources that would tend to be “trusted” by… a technology company. 🙂 That said, the scale here is mind-blowing.
Google beat the rest hands down.
Although it might seem that Google is favoring themselves, it is logical that their brand name should see such a phenomenal increase.
But look at the figures again.
Google has a 600-fold increase. Facebook has a 500-fold increase. Apple has a 460-fold increase.
So in truth, Microsoft is the only one here that hasn’t made much progress (if you can consider a 56-fold increase “not-much-progress”).
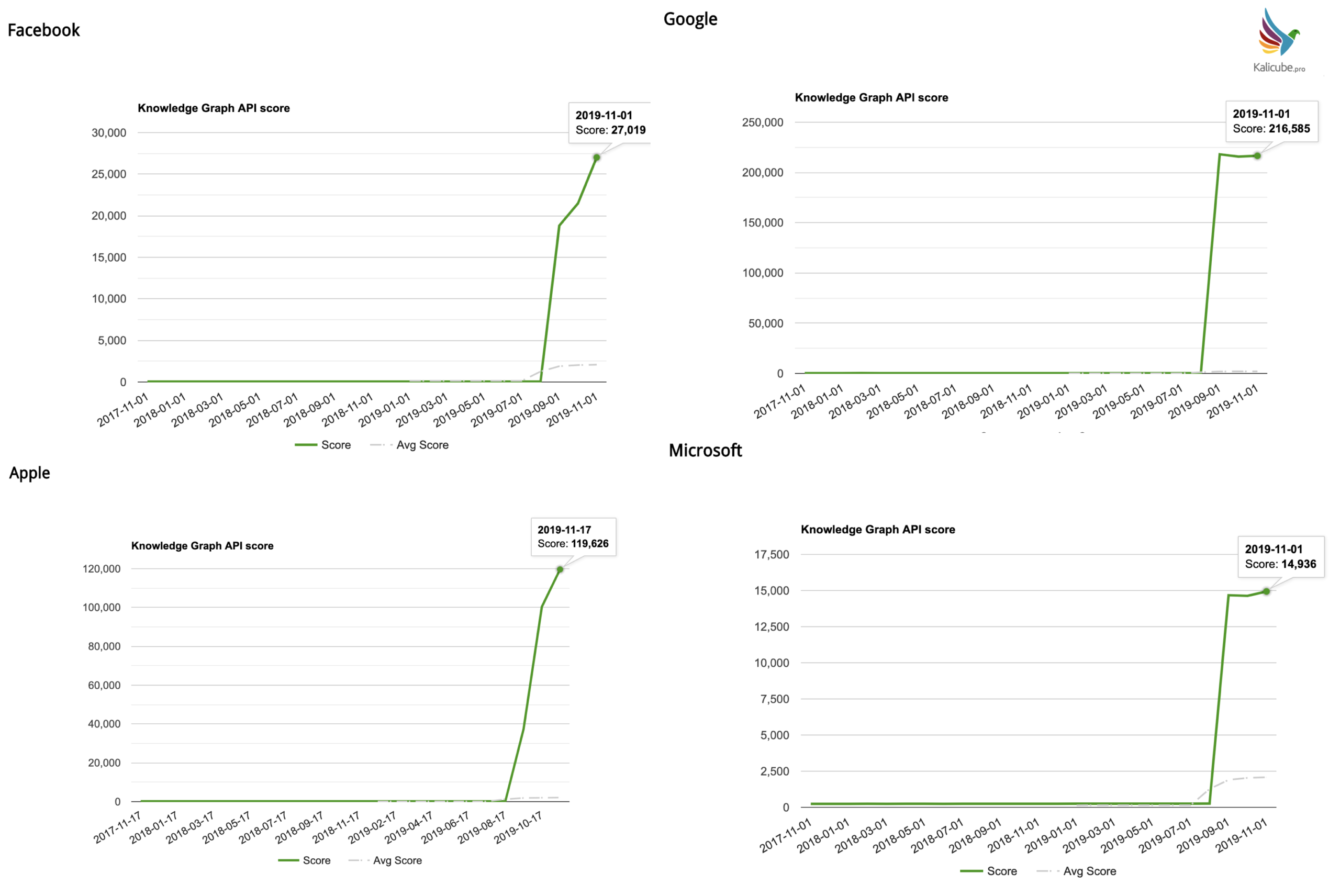
It does appear that this update is skewed and gives tech companies too much focus, Google in particular.
Google appears to be the focal point of its own Knowledge Graph, which means inherent bias.
If you are connected to Google, your brand will find Google’s Knowledge Graph much easier to navigate.
Moving forward, an inherent bias will tend to be exaggerated (so attach your brand to Google and piggyback).
Whatever personal advantage you can grab from this insight, such a bias will pose (as yet unimagined) problems. We’ll see. 🙂
If That Weren’t Enough – Another Update Just Happened
The ‘Depth’ of the Knowledge Graph Dropped
I am calling the average number of results that Google considers relevant to a given query the “depth” (covering entities, ambiguity, and related entities).
It just took a big hit.
No idea what happened here. Yet. 🙂
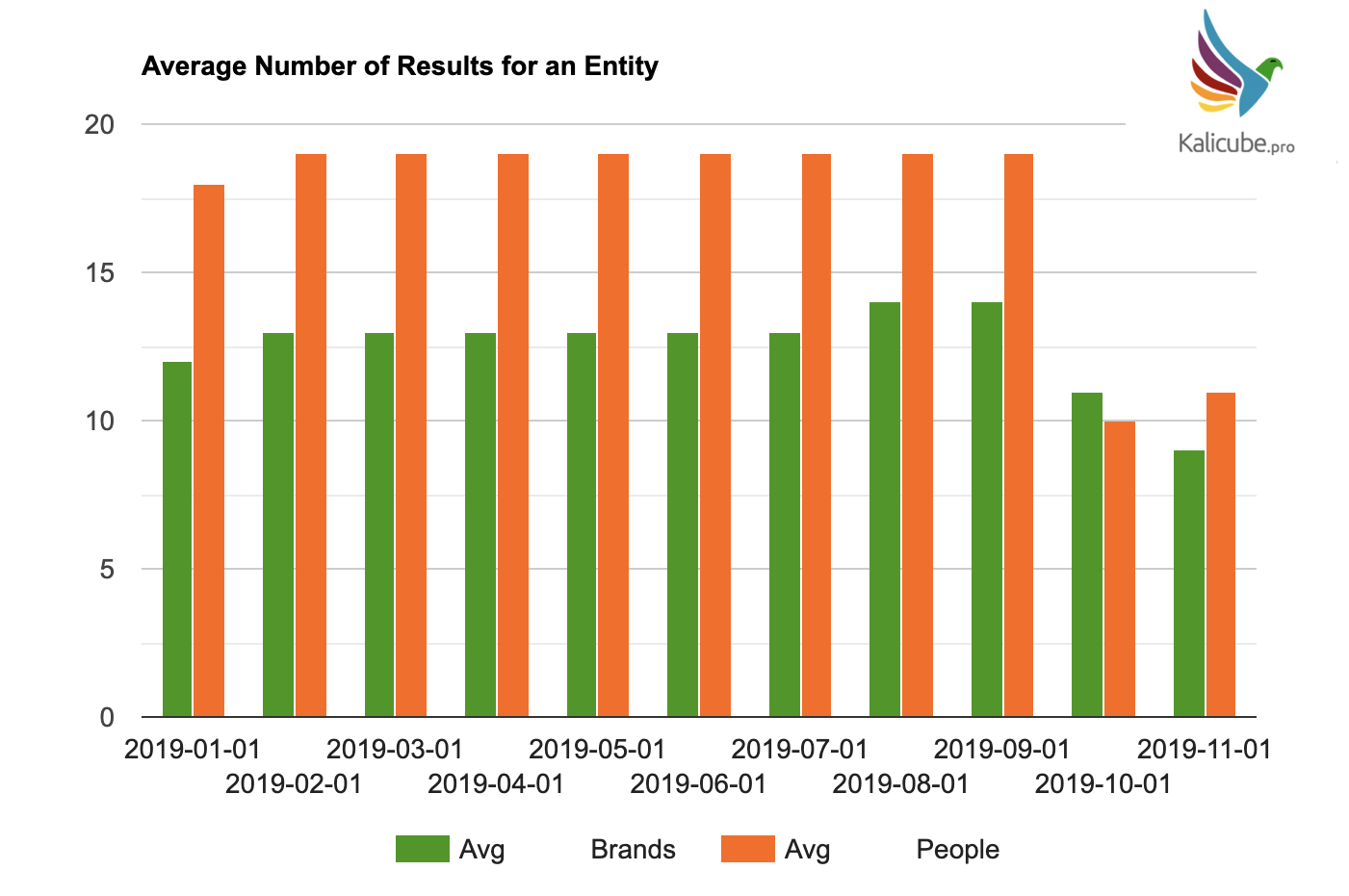
Presence of Knowledge Panels Dropped
I track the SERPs for all 7,455 brands and 4,069 people using data from Authoritas.
In October, on the dataset I am tracking, I saw a 20% drop in the number of SERPs contained a knowledge panel.
Data AccuRanker shared with me for the UK covering a much wider range of queries shows a 13% drop in the presence of knowledge panels mid-October.
Food for thought there, but definitely something “going on.”
Are the Two Related?
It is possible that there is a relationship between this drop in “depth” of the Knowledge Graph and the drop in Knowledge Panels.
I’ll call this new update the Paris update. And will investigate further.
For now, I am sooooo buzzed by the Budapest update that this is simply too much to handle.
P.S.: Naming the updates after the city I was visiting at the time seems like a nice idea.
Add Your Brand & Get Access to All the Data on Kalicube.pro
Please do add brands / personal brands to my ongoing brand-tracking experiment here.
Add your brand / another brand you are curious about / your name / another super person’s name – the more the merrier.
More Resources:
- How to Maximize Your Reach Using Google’s Knowledge Graph
- 10 Ways to Get Multiple Organic Page 1 Google Rankings
- Google Knowledge Panel Hijack Explained
Image Credits
Featured & In-Post Images: Kalicube.pro
