

The content generation technology and techniques I’m going to demonstrate in this column would seem out of a science fiction novel, but they are real and freely accessible now.
After I completed the coding experiments and started to write this piece, I pondered the positive and negative implications of sharing this information publicly.
As you will see, it is relatively easy now to produce machine-generated content and the quality of the generations is improving fast.
This led me to the sad conclusion that we would see far more spammy results than before.
Fortunately, Google recently released its 2019 spam report that put me at ease.
Ever look at your email spam folder? That's how search results might look without the steps we take to fight search spam. Our post today looks at how we work to keep spam out of Google's search results https://t.co/RA4lUoDXEF
— Google SearchLiaison (@searchliaison) June 9, 2020
“Last year, we observed that more than 25 billion of the pages we find each day are spammy. (If each of those pages were a page in a book, that would be more than 20 million copies of “War & Peace” each day!)
Our efforts have helped ensure that more than 99% of visits from our results lead to spam-free experiences.
In the last few years, we’ve observed an increase in spammy sites with auto-generated and scraped content with behaviors that annoy or harm searchers, such as fake buttons, overwhelming ads, suspicious redirects and malware. These websites are often deceptive and offer no real value to people. In 2019, we were able to reduce the impact on Search users from this type of spam by more than 60% compared to 2018.”
While Google reports a staggering number of spam pages per day, they report an impressive 99% success rate in suppressing spam across the board.
More importantly, they’ve been making incredible progress in suppressing machine-generated spam content.
In this column, I’m going to explain with code how a computer is able to generate content using the latest advances in NLG.
I will go over the theory and some guidelines to keep your content useful.
This will help you avoid getting caught with all the web spam Google and Bing are working around the clock to get rid of.
Thin Content Pages
In my article about title and meta description generation, I shared an effective technique that relies on summarizing page content to produce meta tags.
Once you follow the steps, you can see that it works really well and can even produce high quality, novel texts.
But, what if the pages don’t include any content to summarize? The technique fails.
Let me tell you a very clever trick to solve this.
If such pages have quality backlinks, you can use the anchor text and the text surrounding the backlink as the text to summarize.
Wait!
But why?
Let me take back all the way to 1998, to the founding of the Google search engine.
In the paper describing their new search engine, Page and Brin shared a very interesting insight in section 2.2.
“Most search engines associate the text of a link with the page that the link is on. In addition, we associate it with the page the link points to. This has several advantages. First, anchors often provide more accurate descriptions of web pages than the pages themselves. Second, anchors may exist for documents which cannot be indexed by a text-based search engine, such as images, programs, and databases. This makes it possible to return web pages which have not actually been crawled.”
Here is the technical plan:
- We will get backlinks and corresponding anchor texts using the new Bing Webmaster Tools.
- We will scrape the surrounding text from the highest quality backlinks.
- We will create summaries and long-form content using the scraped text.
Bing Webmaster Tools Backlinks Report
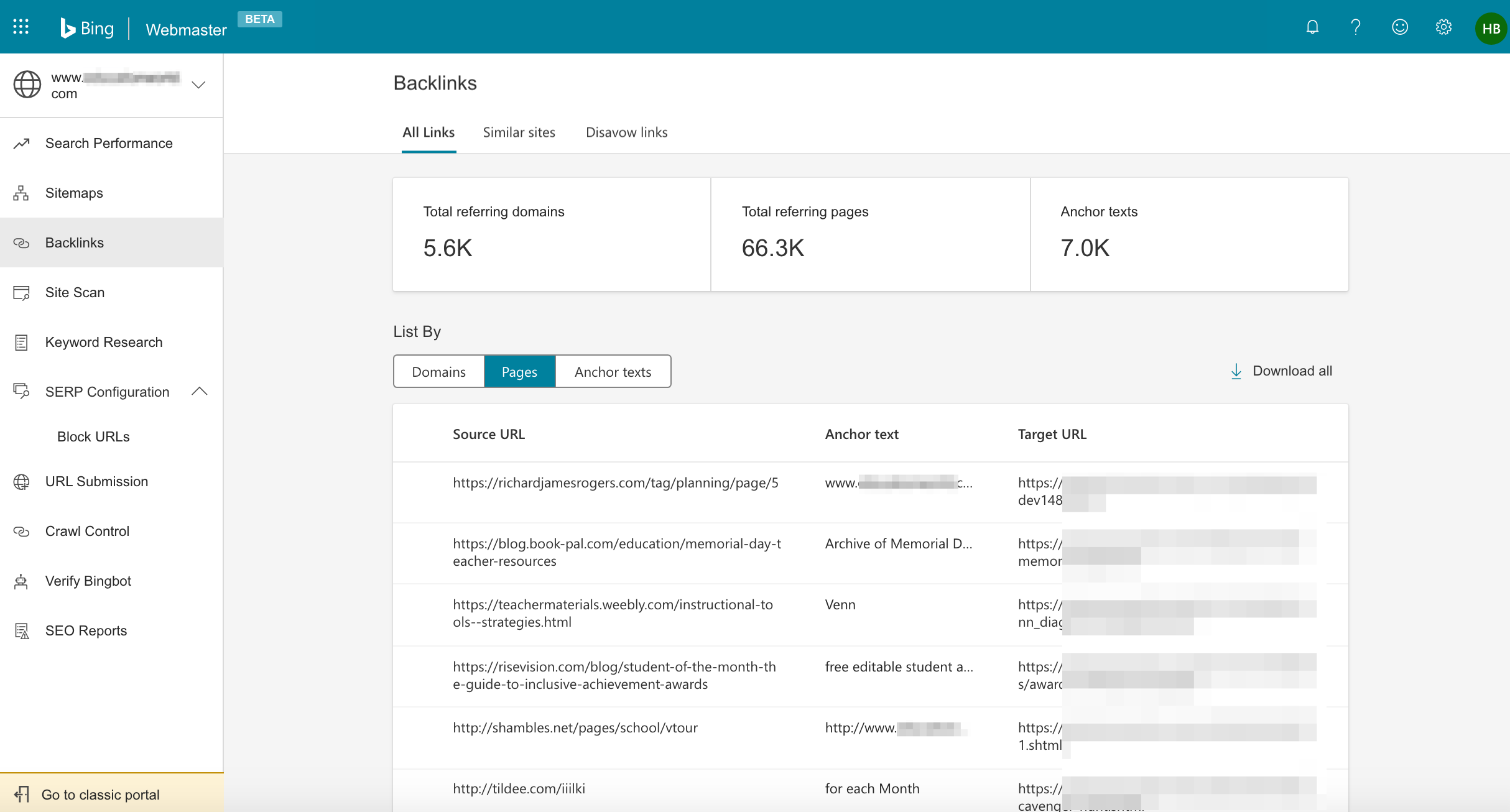
One feature I like in the new backlinks tool in BWT, is that it can provide links not just pointing to your own site, but some other sites as well.
I expect this to become a popular free alternative to the paid tools.
I exported the CSV file with the big list of links and anchors, but when I tried to load it using Python pandas and found a number of formatting issues.
Random anchor texts can include commas and cause issues with a comma-delimited file.
I solved them by opening the file in Excel and saving it in Excel format.
Scraping Surrounding Text with Python
As you can see in my screenshot above, many of the anchor texts are pretty short.
We can scrape the pages to get the paragraph that contains them.
First, let’s load the report we exported from BWT.
import pandas as pd
df = pd.read_excel("www.domain.com_ReferringPages_6_7_2020.xlsx")
df.head()
I reviewed the Target URL by the number of inbound links using.
df.groupby("Target Url").count().tail()
I pulled the backlinks from one of the pages to evaluate the idea using this code.
backlinks = set(df[df["Target Url"] == "https://domain.com/example-page"]["Source Url"])Now, let’s see how we can use a target URL and a backlink to pull the relevant anchor text that includes the anchor.
Fetching Text from Backlinks
First, let’s install requests-html.
!pip install requests-html
from requests_html import HTMLSession
session = HTMLSession()In order to keep the code simple, I’m going to manually produce a CSS selector to grab the text surrounding the link.
It is not difficult to calculate this given the link and anchor on the page using JavaScript or Python code.
Maybe that is a good idea for you to try as homework.
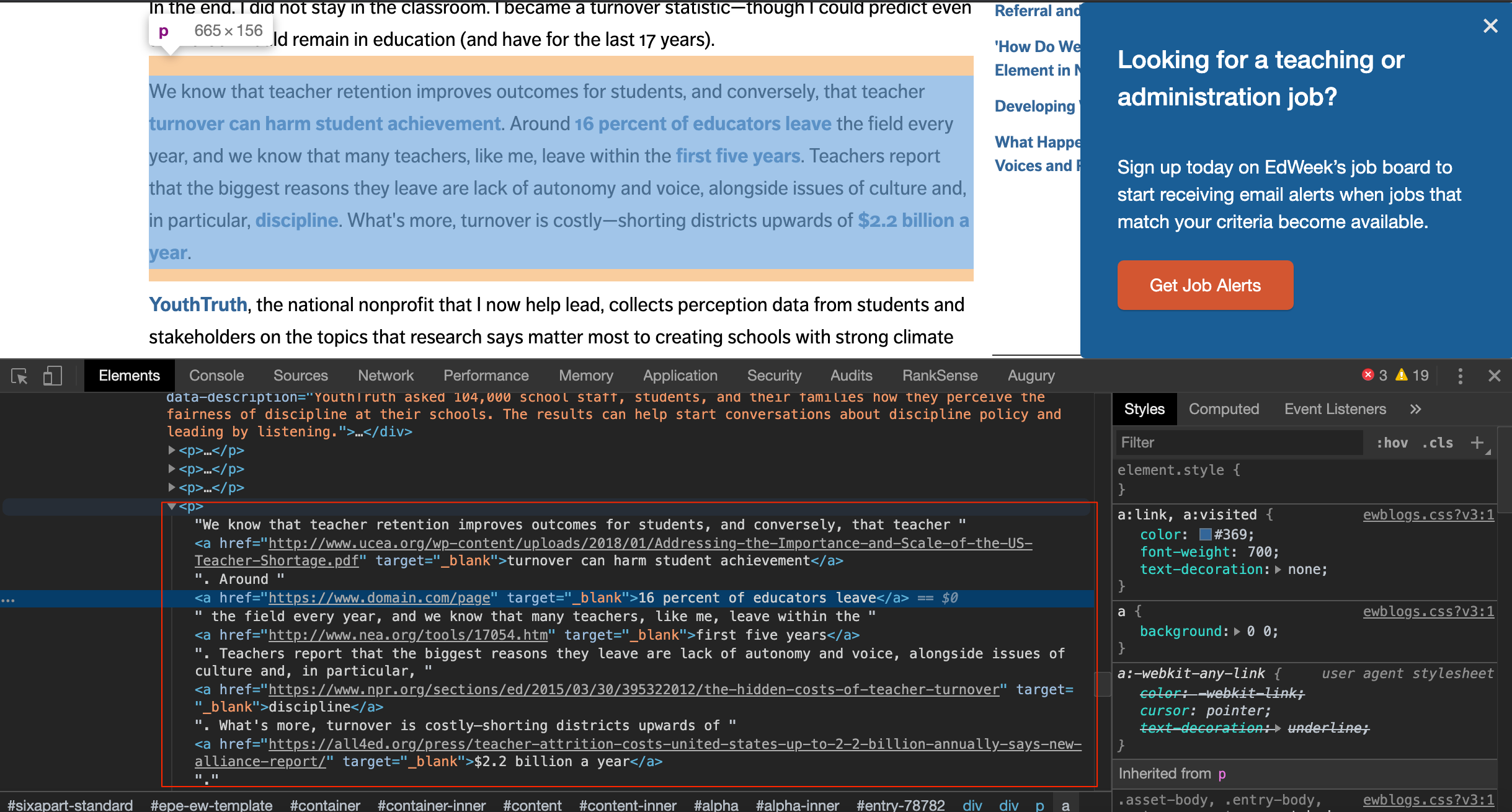
Open an example backlink page and using the Chrome Developer Tools, you can right-click on the paragraph of interest and copy a CSS selector.
This is the selector I used.
with session.get(url) as r:
selector="#entry-78782 > div.asset-content.entry-content > div > p:nth-child(5)"
paragraph = r.html.find(selector, first=True)
text = paragraph.textThis is the text that came back. I bolded the text of our example anchor text.
We know that teacher retention improves outcomes for students, and conversely, that teacher turnover can harm student achievement. Around 16 percent of educators leave the field every year, and we know that many teachers, like me, leave within the first five years. Teachers report that the biggest reasons they leave are lack of autonomy and voice, alongside issues of culture and, in particular, discipline. What’s more, turnover is costly—shorting districts upwards of $2.2 billion a year.
Now, let’s get to the fun part!
Neural Text Generation
We are going to use the same summarization code we used to generate titles and meta descriptions in my previous article, but with a twist.
Instead of specifying a desirable summary length shorter than the original paragraph, we will specify a longer length. Will that work? Let’s see!
!pip install transformers
from transformers import pipeline
summarizer = pipeline('summarization')
generated_text = summarizer(text, min_length=150, max_length=250)
print(generated_text)I get this interesting warning.
Your max_length is set to 250, but you input_length is only 99. You might consider decreasing max_length manually, e.g. summarizer(‘…’, max_length=50)
Let’s see the generated text.
[{'summary_text': "Around 16 percent of educators leave the field every year. Teachers report that the biggest reasons they leave are lack of autonomy and voice, alongside issues of culture and discipline. Turnover is costly, shorting districts upwards of $2.2 billion a year, according to a report by the National Council of Teachers of English, the nation's largest teacher organization. The report also found that teacher retention improves outcomes for students, and conversely, that teacher turnover can harm student achievement. The study was published in the Journal of Education, published by Simon & Schuster, a division of Penguin Random House, on November 14. For more, visit www.simonandschuster.com. For confidential support, call the National Suicide Prevention Lifeline at 1-800-273-8255 or visit http://www.suicidepreventionlifeline.org/."}]The original text had 492 characters and the generated text 835.
But, look at the quality and the novel sentences showing up in the generated text. Absolutely, mind-blowing!
Can this technique generate even longer text? Yes!
generated_text = summarizer(text, min_length=300, max_length=600)
print(generated_text)
[{'summary_text': "Around 16 percent of educators leave the field every year. Teachers report that the biggest reasons they leave are lack of autonomy and voice, alongside issues of culture and discipline. Turnover is costly, shorting districts upwards of $2.2 billion a year, according to a report by the National Council of Teachers of English, the nation's largest teacher organization. The report also found that teacher retention improves outcomes for students, and conversely, that teacher turnover can harm student achievement. The study was published in the Journal of Education, published by Simon & Schuster, a division of Penguin Random House, on November 14. For more, visit www.simonandschuster.com. For confidential support, call the National Suicide Prevention Lifeline at 1-800-273-8255 or visit\xa0http://www.suicidepreventionlifeline.org/. For support in the U.S., call the Samaritans on 08457 90 90 90 or visit a local Samaritans branch, see www.samaritans.org for details. In the UK, contact the National College of Education on 0300 123 90 90, or\xa0 visit\xa0the Samaritans\xa0in the UK. For help in the United States, call\xa0the\xa0National Suicide Prevention Line on 1\xa0800\xa0273\xa08255,\xa0or\xa0in\xa0the UK on 0800\xa0123\xa09255. For support on suicide matters in the\xa0U.S. call the\xa0National\xa0College\xa0of Education,\xa0England\xa0on 08457\xa090 90 90. For information on suicide prevention in the UK and\xa0Europe, visit the National\xa0College of England and Wales."}]This generated text has 1,420 characters and maintains the logical flow!
The beast powering this technique is a model from Facebook called BART.
The authors of the paper describe it as a generalized form of BERT.
Let’s see how this works.
How Neural Text Generation Works

Have you taken aptitude or IQ tests where you are presented with a sequence of numbers and you need to guess the next one?
In essence, that is what our model did above when we provided some initial text and asked our models to predict what goes next.
It turned our initial text into a sequence of numbers, guessed the next number, and took the new sequence that includes the guessed number and repeated the same process again.
This continues until it hits the length limit we specified.
Now, these are not just regular numbers, but vector and more specifically (in the case of BERT and BART) bi-directional word embeddings.
I explained vectors and bi-directional word embedding using a GPS analogy in my deep learning articles part 1 and part 2. Please make sure to check them out.
In summary, embeddings encode rich information about the words they represent which dramatically increases the quality of the predictions.
So, here is one example of how this works.
Given the text: “The best programming language for SEOs doing repetitive tasks is ____ and for SEOs doing front-end audits is ____”, we ask the model to complete the sentence.
The first step is to convert the words into numbers/embeddings, where each embedding identifies the word in context.
Then, turn this into a puzzle the computer can solve to figure out the numbers/embeddings that can fill in the blanks given the context.
The algorithm that can solve these types of puzzles is called a language model.
A language model is similar to the grammatical rules in English or any other language.
For example, if the text is a question, it must end with a question mark.
The difference is that all the words and symbols are represented by numbers/embeddings.
Now, where it gets interesting is that in deep learning (what we are using here), you don’t need to manually create a big list of grammar rules.
The model learns the rules empirically through efficient trial and error.
This is done during what is called a pre-training phase where the models are trained over a massive corpus of data for several days and using very powerful hardware.
The best part for us is that the results of these efforts are made free for anyone to use.
Aren’t we really fortunate?
BERT is an example of a language model and so are GPT-2 and BART.
How to Use This for Good
As I mentioned above, this stuff is really powerful and could be used to churn useless content at scale relatively cheaply.
I personally wouldn’t want to waste time wading through garbage while I search.
Over time, I’ve come to realize that in order for content to perform in search, it needs to:
- Be useful.
- Satisfy a real need.
If it doesn’t, no matter if it is computer or human-produced, it won’t get any engagement or validation from end-users.
The chances of ranking and performing are really low.
This is why I prefer techniques like summarization and translation or question/answering where you have greater control over the generation.
They can help you make sure that you are adding new value.
Community Projects & Learning Resources
I tried to keep this article light in code and the explanations as simple as possible to allow more people in the community to join in the fun.
But, if you are more technically inclined, I think you will enjoy this more granular and mathematical explanation of the topic.
Make sure to also follow the links in the “Further reading section” in the linked article above.
Now, to some exciting news.
I asked the community to share the Python projects they are working on. I was expecting maybe a handful, and I was completely blown away by how many I got back. #DONTWAIT 🐍🔥
This one's Python and JS, but I'll put it out there anyway! Chrome extension for busting spam on Google Maps. The server code is in Python and does address validation and classification. pic.twitter.com/Rvzfr5ku4N
— zchtodd (@zchtodd) June 8, 2020
1. RPA in python to automate repetitive screenshot taking https://t.co/zyaafY0bcd
2. Search console API + NLP to check for pages where word in meta title does not match the queries used by visitors: https://t.co/KsYGds7w1r— Michael Van Den Reym (@vdrweb) June 8, 2020
3. Check status code of all url's with search console impressions using search console API https://t.co/qX0FxSoqgN
— Michael Van Den Reym (@vdrweb) June 8, 2020
Hi Hamlet!
I'm working on a redirect checker with fuzzy-matching capabilities.
There will be a @GoogleColab notebook, yet ideally I'd also want to deploy in @streamlit so folks can assess the quality of their redirects in 1 click, via drag and drop.
I'll share shortly 🙂
— Charly Wargnier (@DataChaz) June 9, 2020
@hamletbatista https://t.co/oPt5M393Lu
Worked on this using @streamlit
Write more compelling Meta Titles.
Explainer video: https://t.co/YvVoFMQ4FS— Anubhav Bittoo Narula (@anubhavn22) June 9, 2020
Scrapear redes sociales y pasarlo por npl o Red neuronal para saber el sentimiento del escrito y de ahí sacar gráficas con datastudio o kibana (perdona que responda en español pero mi inglés es bastante mejorable)
— JaviLázaro (@JaviLazaroSEO) June 8, 2020
1. Reading the log files and posting 5xx/4xx on real time basis to slack !
2. Keyword Intent vs Url Match Score.— Venus Kalra (@venuskalra) June 9, 2020
— Marat Gaziev (@MaratGaziev) June 9, 2020
I'm building a package for #SEO's & online marketers, containing among other things:
– Crawler
– robots.txt tester
– SERP checker
– Sitemap to DataFrame converter
– URL to DataFrame converterand more 🙂 https://t.co/BMVeeQaTxE
— Elias Dabbas (@eliasdabbas) June 9, 2020
Some content analysis with Beautiful Soup + the Knowledge box API + Cloud Entity API! 🐍🐍🐍
— Jess but 6 feet away (@jessthebp) June 8, 2020
More Resources:
- How to Produce Quality Titles & Meta Descriptions Automatically
- Automated Intent Classification Using Deep Learning
- Automated Intent Classification Using Deep Learning (Part 2)
Image Credits
All screenshots taken by author, June 2020
