

Inflection AI, the creators of the PI AI Personal Assistant announced the creation of a powerful new large language model called Inflection-2 that outperforms Google’s PaLM language model across a range of benchmarking datasets.
Pi Personal Assistant
Pi is a personal assistant that is available on the web and as an app for Android and Apple mobile devices.
It can also be added as a contact in WhatsApp and accessed via Facebook and Instagram direct message.
Pi is designed to be a chatbot assistant that can answer questions, research anything from products, science, or products and it can function like a discussion companion that dispenses advice.
The new LLM will be incorporated into PI AI soon after undergoing safety testing.
Inflection-2 Large Language Model
Inflection-2 is a large language model that outperforms Google’s PaLM 2 Large model, which is currently Google’s most sophisticated model.
Inflection-2 was tested across multiple benchmarks and compared against PaLM 2 and Meta’s LLaMA 2 and other large language models (LLMs).
For example, Google’s PaLM 2 barely edged past Inflection-2 on the Natural Questions corpus, a dataset of real-world questions.
PaLM 2 scored 37.5 and Inflection-2 scored 37.3, with both outperforming LLaMA 2, which scored 33.0.
MMLU – Massive Multitask Language Understanding
Inflection AI published the benchmarking scores on the MMLU dataset, which is designed to test LLMs in a way that’s similar to testing humans.
The test is on 57 subjects in STEM (Science, Technology, Engineering, and Math) and a wide range of other subjects like law.
The purpose of the dataset is to identify where the LLM is strongest and where it is weak.
According to the research paper for this benchmarking dataset:
“We propose a new test to measure a text model’s multitask accuracy.
The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more.
To attain high accuracy on this test, models must possess extensive world knowledge and problem solving ability.
We find that while most recent models have near random-chance accuracy, the very largest GPT-3 model improves over random chance by almost 20 percentage points on average.
However, on every one of the 57 tasks, the best models still need substantial improvements before they can reach expert-level accuracy.
Models also have lopsided performance and frequently do not know when they are wrong.
Worse, they still have near-random accuracy on some socially important subjects such as morality and law.
By comprehensively evaluating the breadth and depth of a model’s academic and professional understanding, our test can be used to analyze models across many tasks and to identify important shortcomings.”
These are the MMLU benchmarking dataset scores in order of weakest to strongest:
- LLaMA 270b 68.9
- GPT-3.5 70.0
- Grok-1 73.0
- PaLM-2 Large 78.3
- Claude-2 _CoT 78.5
- Inflection-2 79.6
- GPT-4 86.4
As can be seen above, only GPT-4 scores higher than Inflection-2.
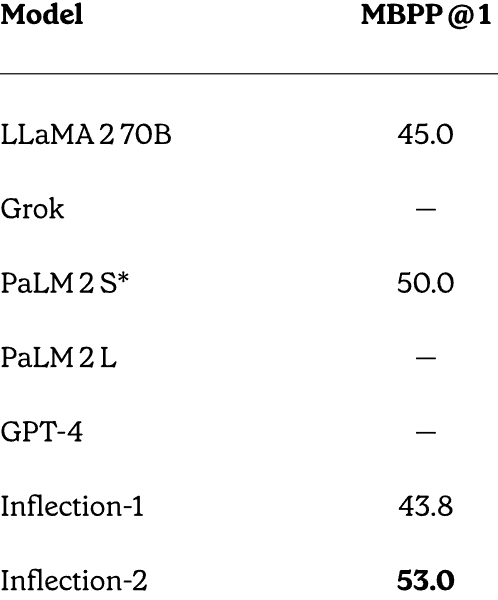
MBPP – Code and Math Reasoning Performance
Inflection AI did a head to head comparison between GPT-4, PaLM 2, LLaMA and Inflection-2 on math and code reasoning tests and did surprisingly well considering that it was not specifically trained for solving math problems.
The benchmarking dataset used is called MBPP (Mostly Basic Python Programming) This dataset consists of over 1,000 crowd-sourced Python programming problems.
What makes the scores especially notable is that Inflection AI tested against PaLM-2S, which is a variant large language model that was specifically fine-tuned for coding.
MBPP Scores:
- LLaMA-2 70B: 45.0
- PaLM-2S: 50.0
- Inflection-2: 53.0
Screenshot of Complete MBPP Scores
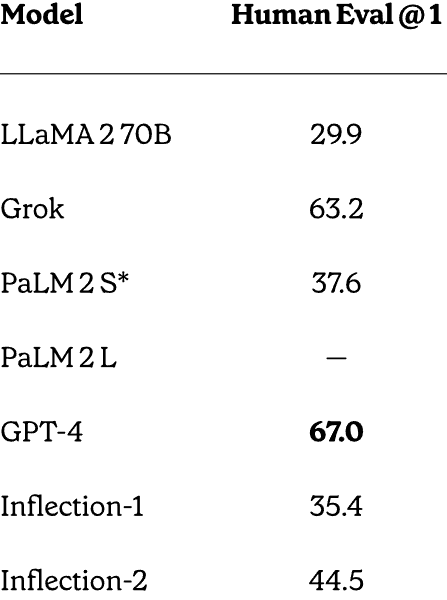
HumanEval Dataset Test
Inflection-2 also outperformed PaLM-2 on the HumanEval problem solving dataset that was developed and released by OpenAI.
Hugging Face describes this dataset:
“The HumanEval dataset released by OpenAI includes 164 programming problems with a function sig- nature, docstring, body, and several unit tests.
They were handwritten to ensure not to be included in the training set of code generation models.
The programming problems are written in Python and contain English natural text in comments and docstrings.
The dataset was handcrafted by engineers and researchers at OpenAI.”
These are the scores:
- LLaMA-2 70B: 29.9
- PaLM-2S: 37.6
- Inflection-2: 44.5
- GPT-4: 67.0
As can be seen above, only GPT-4 scored higher than Inflection-2. Yet it should again be noted that Inflection-2 was not fine-tuned to solve these kinds of problems, which makes these scores an impressive achievement.
Screenshot of Complete HumanEval Scores
Inflection AI explains why these scores are significant:
“Results on math and coding benchmarks.
Whilst our primary goal for Inflection-2 was not to optimize for these coding abilities, we see strong performance on both from our pre-trained model.
It’s possible to further enhance our model’s coding capabilities by fine-tuning on a code-heavy dataset.”
An Even More Powerful LLM Is Coming
The Inflection AI announcement stated that Inflection-2 was trained on 5,000 NVIDIA H100 GPUs. They are planning on training an even larger model on a 22,000 GPU cluster, several orders bigger than the 5,000 GPU cluster Inflection-2 was trained on.
Google and OpenAI are facing strong competition from both closed and open source startups. Inflection AI joins the top ranks of startups with powerful AI under development.
The PI personal assistant is a conversational AI platform with an underlying technology that is state of the art with the possibility of becoming even more powerful than other platforms that charge for access.
Read the official announcement:
Inflection-2: The Next Step Up
Visit PI personal assistant online
Featured Image by Shutterstock/Malchevska
