

Microsoft published a research study that demonstrates how advanced prompting techniques can cause a generalist AI like GPT-4 to perform as well as or better than a specialist AI that is trained for a specific topic. The researchers discovered that they could make GPT-4 outperform Google’s specially trained Med-PaLM 2 model that was explicitly trained in that topic.
Advanced Prompting Techniques
The results of this research confirms insights that advanced users of generative AI have discovered and are using to generate astonishing images or text output.
Advanced prompting is generally known as prompt engineering. While some may scoff that prompting can be so profound as to warrant the name engineering, the fact is that advanced prompting techniques are based on sound principles and the results of this research study underlines this fact.
For example, a technique used by the researchers, Chain of Thought (CoT) reasoning is one that many advanced generative AI users have discovered and used productively.
Chain of Thought prompting is a method outlined by Google around May 2022 that enables AI to divide a task into steps based on reasoning.
I wrote about Google’s research paper on Chain of Thought Reasoning which allowed an AI to break a task down into steps, giving it the ability to solve any kind of word problems (including math) and to achieve commonsense reasoning.
These principals eventually worked their way into how generative AI users elicited high quality output, whether it was creating images or text output.
Peter Hatherley (Facebook profile), founder of Authored Intelligence web app suites, praised the utility of chain of thought prompting:
“Chain of thought prompting takes your seed ideas and turns them into something extraordinary.”
Peter also noted that he incorporates CoT into his custom GPTs in order to supercharge them.
Chain of Thought (CoT) prompting evolved from the discovery that asking a generative AI for something is not enough because the output will consistently be less than ideal.
What CoT prompting does is to outline the steps the generative AI needs to take in order to get to the desired output.
The breakthrough of the research is that using CoT reasoning plus two other techniques allowed them to achieve stunning levels of quality beyond what was known to be possible.
This technique is called Medprompt.
Medprompt Proves Value Of Advanced Prompting Techniques
The researchers tested their technique against four different foundation models:
- Flan-PaLM 540B
- Med-PaLM 2
- GPT-4
- GPT-4 MedPrompt
They used benchmark datasets created for testing medical knowledge. Some of these tests were for reasoning, some were questions from medical board exams.
Four Medical Benchmarking Datasets
- MedQA (PDF)
Multiple choice question answering dataset - PubMedQA (PDF)
Yes/No/Maybe QA Dataset - MedMCQA (PDF)
Multi-Subject Multi-Choice Dataset - MMLU (Massive Multitask Language Understanding) (PDF)
This dataset consists of 57 tasks across multiple domains contained within the topics of Humanities, Social Science, and STEM (science, technology, engineering and math).
The researchers only used the medical related tasks such as clinical knowledge, medical genetics, anatomy, professional medicine, college biology and college medicine.
GPT-4 using Medprompt absolutely bested all the competitors it was tested against across all four medical related datasets.
Table Shows How Medprompt Outscored Other Foundation Models
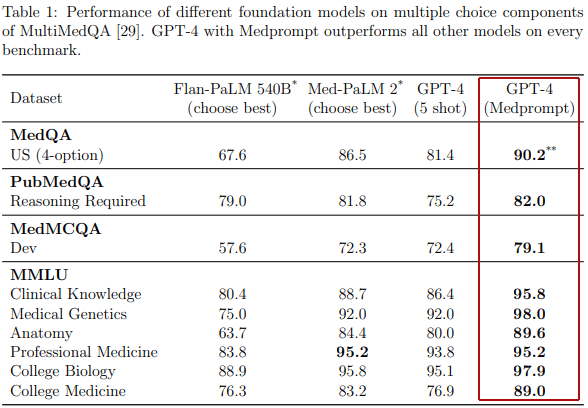
Why Medprompt is Important
The researchers discovered that using CoT reasoning, together with other prompting strategies, could make a general foundation model like GPT-4 outperform specialist models that were trained in just one domain (area of knowledge).
What makes this research especially relevant for everyone who uses generative AI is that the MedPrompt technique can be used to elicit high quality output in any knowledge area of expertise, not just the medical domain.
The implications of this breakthrough is that it may not be necessary to expend vast amounts of resources training a specialist large language model to be an expert in a specific area.
One only needs to apply the principles of Medprompt in order to obtain outstanding generative AI output.
Three Prompting Strategies
The researchers described three prompting strategies:
- Dynamic few-shot selection
- Self-generated chain of thought
- Choice shuffle ensembling
Dynamic Few-Shot Selection
Dynamic few-shot selection enables the AI model to select relevant examples during training.
Few-shot learning is a way for the foundational model to learn and adapt to specific tasks with just a few examples.
In this method, models learn from a relatively small set of examples (as opposed to billions of examples), with the focus that the examples are representative of a wide range of questions relevant to the knowledge domain.
Traditionally, experts manually create these examples, but it’s challenging to ensure they cover all possibilities. An alternative, called dynamic few-shot learning, uses examples that are similar to the tasks the model needs to solve, examples that are chosen from a larger training dataset.
In the Medprompt technique, the researchers selected training examples that are semantically similar to a given test case. This dynamic approach is more efficient than traditional methods, as it leverages existing training data without requiring extensive updates to the model.
Self-Generated Chain of Thought
The Self-Generated Chain of Thought technique uses natural language statements to guide the AI model with a series of reasoning steps, automating the creation of chain-of-thought examples, which frees it from relying on human experts.
The research paper explains:
“Chain-of-thought (CoT) uses natural language statements, such as “Let’s think step by step,” to explicitly encourage the model to generate a series of intermediate reasoning steps.
The approach has been found to significantly improve the ability of foundation models to perform complex reasoning.
Most approaches to chain-of-thought center on the use of experts to manually compose few-shot examples with chains of thought for prompting. Rather than rely on human experts, we pursued a mechanism to automate the creation of chain-of-thought examples.
We found that we could simply ask GPT-4 to generate chain-of-thought for the training examples using the following prompt:
Self-generated Chain-of-thought Template## Question: {{question}} {{answer_choices}} ## Answer model generated chain of thought explanation Therefore, the answer is [final model answer (e.g. A,B,C,D)]"
The researchers realized that this method could yield wrong results (known as hallucinated results). They solved this problem by asking GPT-4 to perform an additional verification step.
This is how the researchers did it:
“A key challenge with this approach is that self-generated CoT rationales have an implicit risk of including hallucinated or incorrect reasoning chains.
We mitigate this concern by having GPT-4 generate both a rationale and an estimation of the most likely answer to follow from that reasoning chain.
If this answer does not match the ground truth label, we discard the sample entirely, under the assumption that we cannot trust the reasoning.
While hallucinated or incorrect reasoning can still yield the correct final answer (i.e. false positives), we found that this simple label-verification step acts as an effective filter for false negatives.”
Choice Shuffling Ensemble
A problem with multiple choice question answering is that foundation models (GPT-4 is a foundational model) can exhibit position bias.
Traditionally, position bias is a tendency that humans have for selecting the top choices in a list of choices.
For example, research has discovered that if users are presented with a list of search results, most people tend to select from the top results, even if the results are wrong. Surprisingly, foundation models exhibit the same behavior.
The researchers created a technique to combat position bias when the foundation model is faced with answering a multiple choice question.
This approach increases the diversity of responses by defeating what’s called “greedy decoding,” which is the behavior of foundation models like GPT-4 of choosing the most likely word or phrase in a series of words or phrases.
In greedy decoding, at each step of generating a sequence of words (or in the context of an image, pixels), the model chooses the likeliest word/phrase/pixel (aka token) based on its current context.
The model makes a choice at each step without consideration of the impact on the overall sequence.
Choice Shuffling Ensemble solves two problems:
- Position bias
- Greedy decoding
This how it’s explained:
“To reduce this bias, we propose shuffling the choices and then checking consistency of the answers for the different sort orders of the multiple choice.
As a result, we perform choice shuffle and self-consistency prompting. Self-consistency replaces the naive single-path or greedy decoding with a diverse set of reasoning paths when prompted multiple times at some temperature> 0, a setting that introduces a degree of randomness in generations.
With choice shuffling, we shuffle the relative order of the answer choices before generating each reasoning path. We then select the most consistent answer, i.e., the one that is least sensitive to choice shuffling.
Choice shuffling has an additional benefit of increasing the diversity of each reasoning path beyond temperature sampling, thereby also improving the quality of the final ensemble.
We also apply this technique in generating intermediate CoT steps for training examples. For each example, we shuffle the choices some number of times and generate a CoT for each variant. We only keep the examples with the correct answer.”
So, by shuffling choices and judging the consistency of answers, this method not only reduces bias but also contributes to state-of-the-art performance in benchmark datasets, outperforming sophisticated specially trained models like Med-PaLM 2.
Cross-Domain Success Through Prompt Engineering
Lastly, what makes this research paper incredible is that the wins are applicable not just to the medical domain, the technique can be used in any kind of knowledge context.
The researchers write:
“We note that, while Medprompt achieves record performance on medical benchmark datasets, the algorithm is general purpose and is not restricted to the medical domain or to multiple choice question answering.
We believe the general paradigm of combining intelligent few-shot exemplar selection, self-generated chain of thought reasoning steps, and majority vote ensembling can be broadly applied to other problem domains, including less constrained problem solving tasks.”
This is an important achievement because it means that the outstanding results can be used on virtually any topic without having to go through the expense and time of intensely training a model on specific knowledge domains.
What Medprompt Means For Generative AI
Medprompt has revealed a new way to elicit enhanced model capabilities, making generative AI more adaptable and versatile across a range of knowledge domains for a lot less training and effort than previously understood.
The implications for the future of generative AI are profound, not to mention how this may influence the skill of prompt engineering.
Read the new research paper:
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine (PDF)
Featured Image by Shutterstock/Asier Romero
