

One of the main benefits of combining programming and SEO skills is that you can find clever solutions that would be difficult to see if you only know SEO or programming separately.
For instance, tracking the indexing of your most important pages is a crucial SEO task.
If they are not being indexed, you need to know the reason and take action. The best part is that we can learn all this for free directly from Google Search Console.
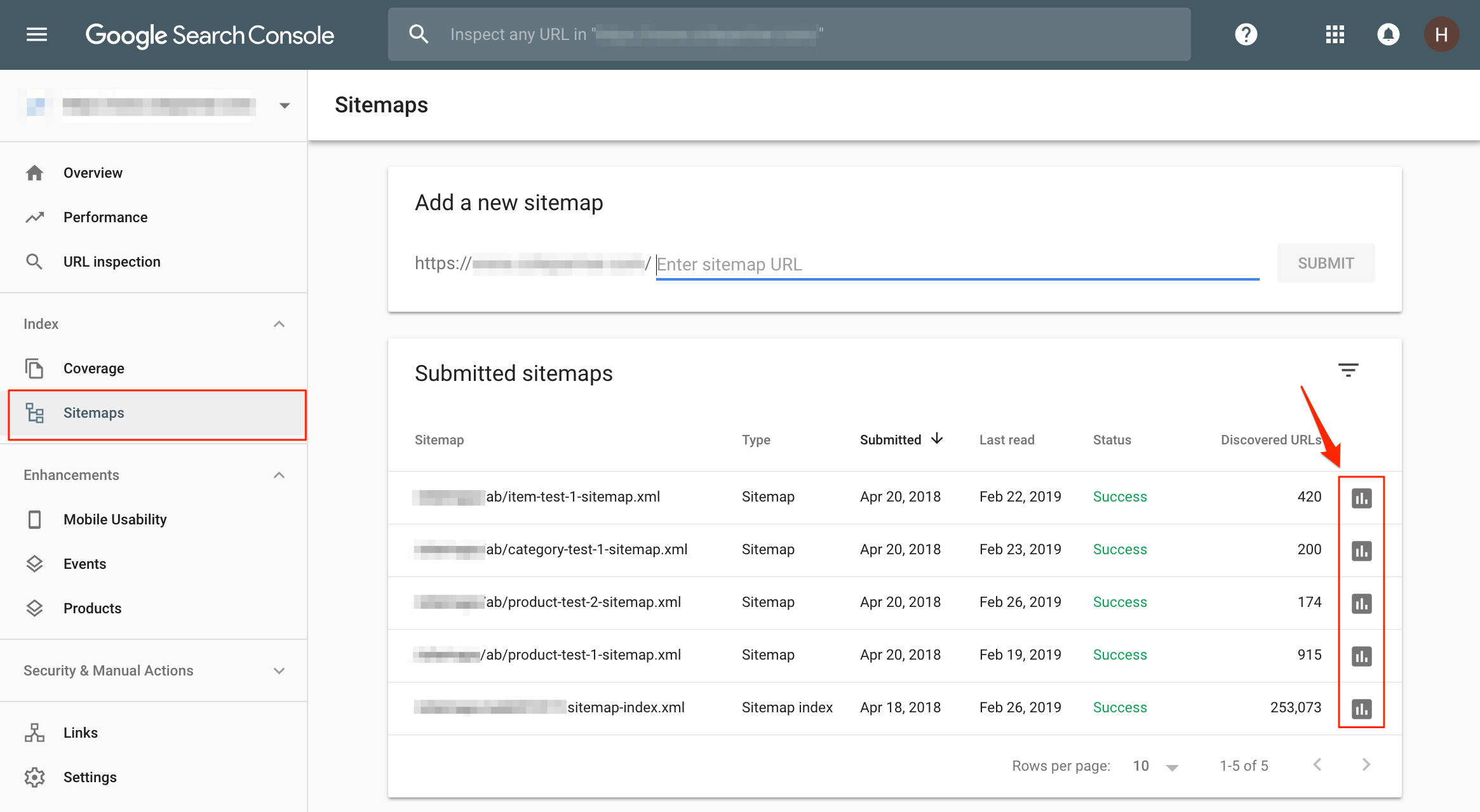
In the screenshot above, the XML sitemaps are grouped by page type, but the four sitemaps listed here are specifically used to track the progress of some SEO A/B tests we ran for this client.
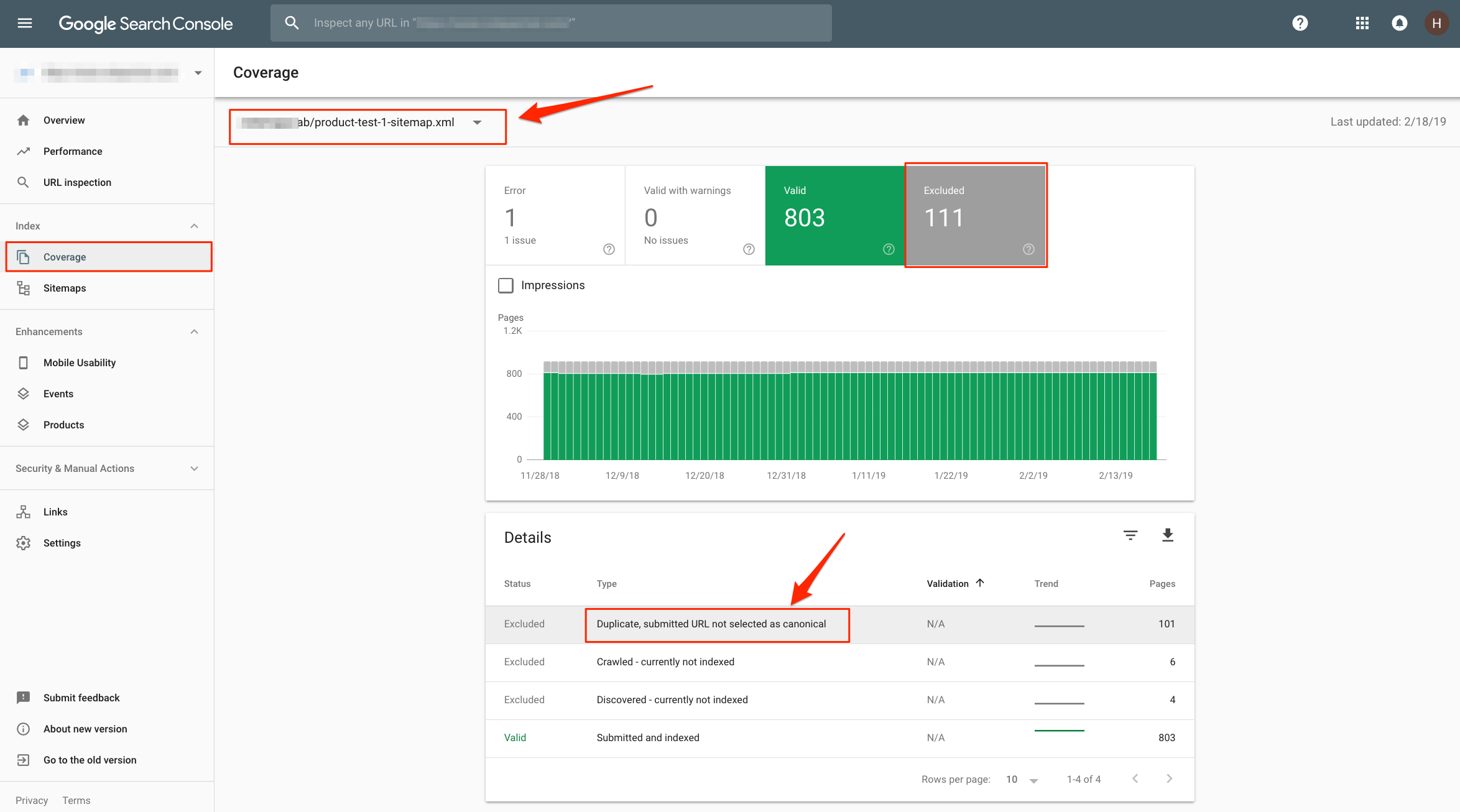
In the Index Coverage reports, we can check each sitemap, learn which specific pages are not indexed, why they are not indexed, and get a sense of how to fix them (if they can be fixed).
The remainder of this post will cover how to reorganize your XML sitemaps using any criteria that can help you isolate indexing problems on pages you care about.
Table of Contents
- Required libraries
- Read sitemap URLs from XML sitemap indices
- Read URLs from XML sitemaps
- Reorganizing sitemaps by popular words
- Creating a word cloud
- Breaking the 1k URL Index Coverage limit
- Reorganizing sitemaps by bestsellers
- Write XML sitemaps
- Resources to learn more
Required Libraries
In this article, we are going to use Python 3 and the following third-party libraries:
If you used Google Colab, you need to upgrade pandas. Type:
!pip install –upgrade pandas==0.23
Overall Process
We are going to read URLs from existing XML sitemaps, load them in the pandas data frames, create or use additional columns, group the URLs by the columns we will use as criteria, and write the groups of URLs into XML sitemaps.
Read Sitemap URLs from XML Sitemap Indices
Let’s start by reading a list of sitemap URLs in the Search Engine Journal sitemap index.
The partial output is:
The number of sitemaps are 30
{‘https://www.searchenginejournal.com/post-sitemap1.xml’: ‘2005-08-15T10:52:01-04:00’, …
Read URLs from XML Sitemaps
Now that we have sitemap URLs, we can pull the actual website URLs. For example purposes, we will only pull URLs from the post sitemaps.
The partial output is
https://www.searchenginejournal.com/post-sitemap1.xml
The number of URLs are 969
https://www.searchenginejournal.com/post-sitemap2.xml
The number of URLs are 958
https://www.searchenginejournal.com/post-sitemap3.xml
The number of URLs are 943
Next, we load them into a pandas data frame.
The output shows the first 10 URLs with their last modification timestamp.
Reorganizing Sitemaps by Popular Words
Search Engine Journal XML sitemaps use the Yoast SEO plugin, which while it separates categories and blogs, all posts are grouped into post-sitemapX.xml sitemap files.
We want to reorganize post sitemaps by the most popular words that appear in the slugs. We created the word cloud you see below with the most popular words we found. Let’s put this together!
Creating a Word Cloud

In order to organize sitemaps by their most popular URLs, we will create a word cloud. A word cloud is just the most popular words ordered by their frequency. We eliminate common words like “the”, “a”, etc. to have a clean group.
We first create a new column with only the paths of the URLs, then download English stopwords from the Nltk package.
The process is to first take only the path portion of the URLs, break the words by using – or / as separators, and count the word frequency. When counting, we exclude stop words and words that are only digits. Think the 5 in “5 ways to do X”.
The partial output is:
[(‘google‘, 4430), (‘search’, 2961), (‘seo‘, 1482), (‘yahoo’, 1049), (‘marketing’, 989), (‘new’, 919), (‘content’, 919), (‘social’, 821), …
Just for fun (as promised in the headline), here is the code that will create a visual word cloud with the word frequencies above.
Now, we add the wordcloud column as a category to the data frame with the sitemap URLs.
Here is what the output looks like.
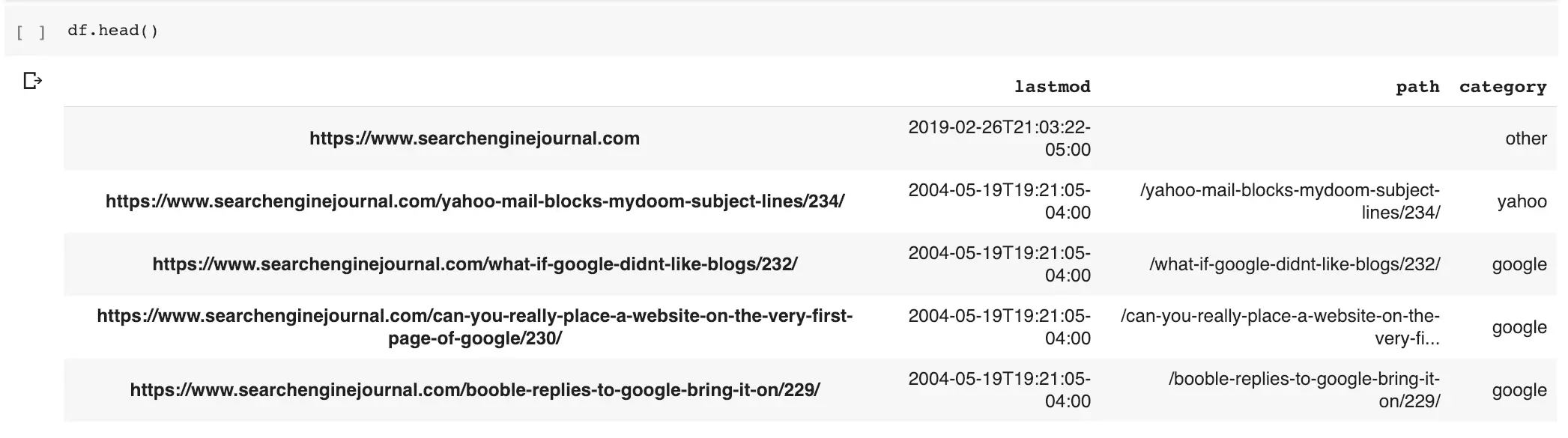
We can use this new category to review URLs that contain the popular word: Google.
df[df[“category”] == “google”]
This list only the URLs with that popular word in the path.
Breaking the 1k URL Index Coverage Limit
Google Search Console’s Index Coverage report is powerful, but it limits the reports to only one thousand URLs. We can split our already filtered XML sitemaps URLs further into groups of 1k URLs.
We can use pandas’ powerful indexing capability for this.
Reorganizing Sitemaps by Bestsellers
One of the most powerful uses of this technique is to break out pages that lead to conversions.
In ecommerce sites, we could break out the best sellers and learn which ones are not indexed. Easy money!
As SEJ is not a transactional site, I will create some fake transactions to illustrate this tactic. Normally, you’d fetch this data from Google Analytics.
I’m assuming that pages with the words “adwords”, “facebook”, “ads” or “media” have transactions.
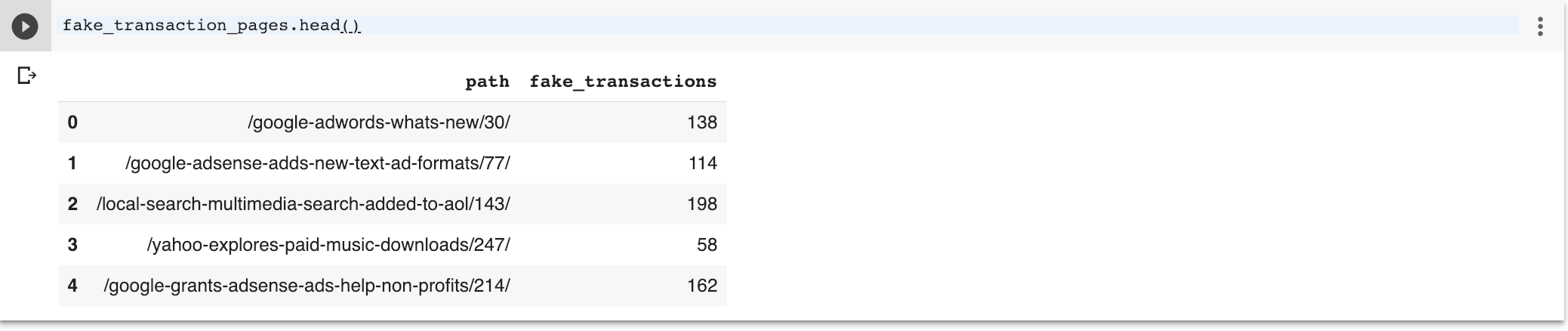
We create a fake transactions column with only the relative path as you would normally find in Google Analytics.
Next, we will merge the two data frames to add the transaction data to the original sitemap data frame. By default, the pandas merge function will perform an inner join, so only the rows in common are available.
df.merge(fake_transaction_pages, left_on=”path”, right_on=”path”)
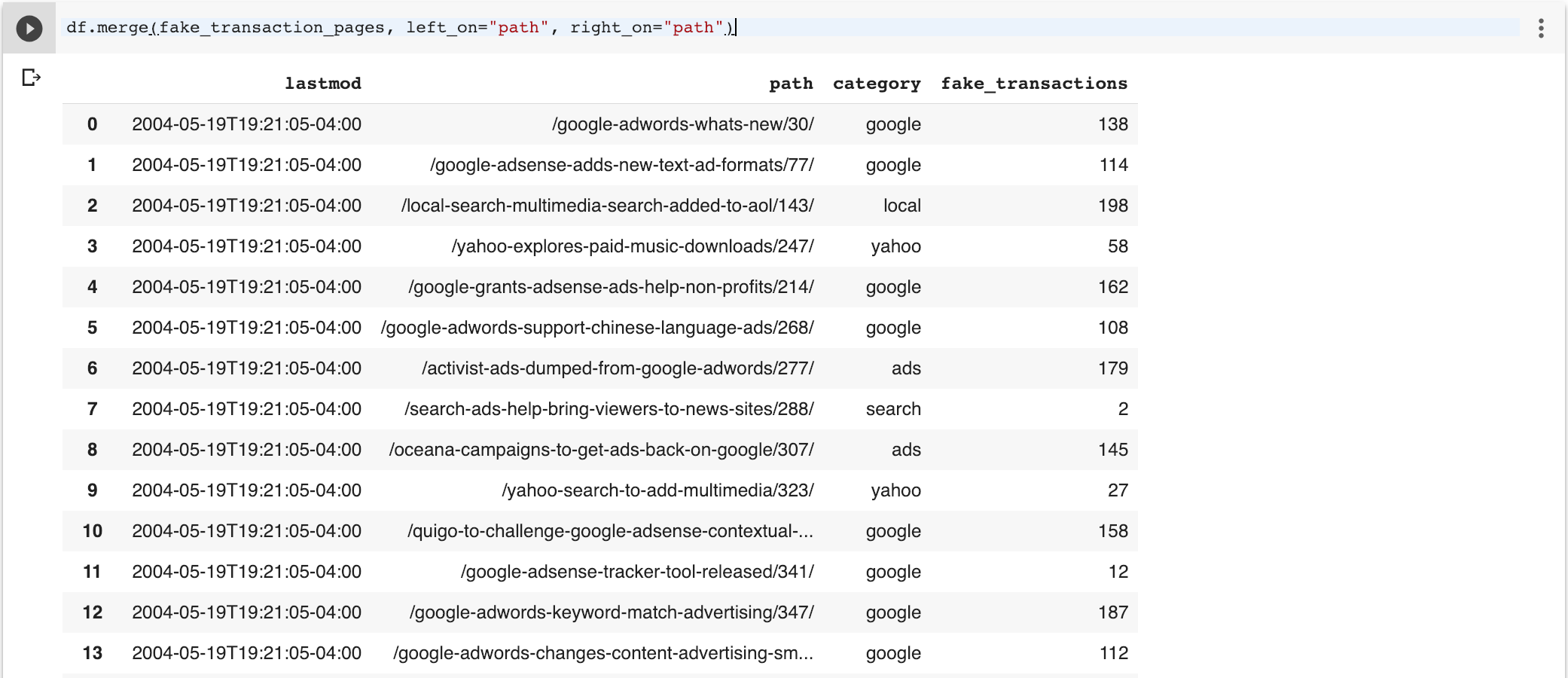
As I want all rows, I will change the join type to left so it includes all rows in the original data frame. Note the missing rows fake NaN (missing value) in the fake transactions column.
df.merge(fake_transaction_pages, left_on=”path”, right_on=”path”, how=”left”)
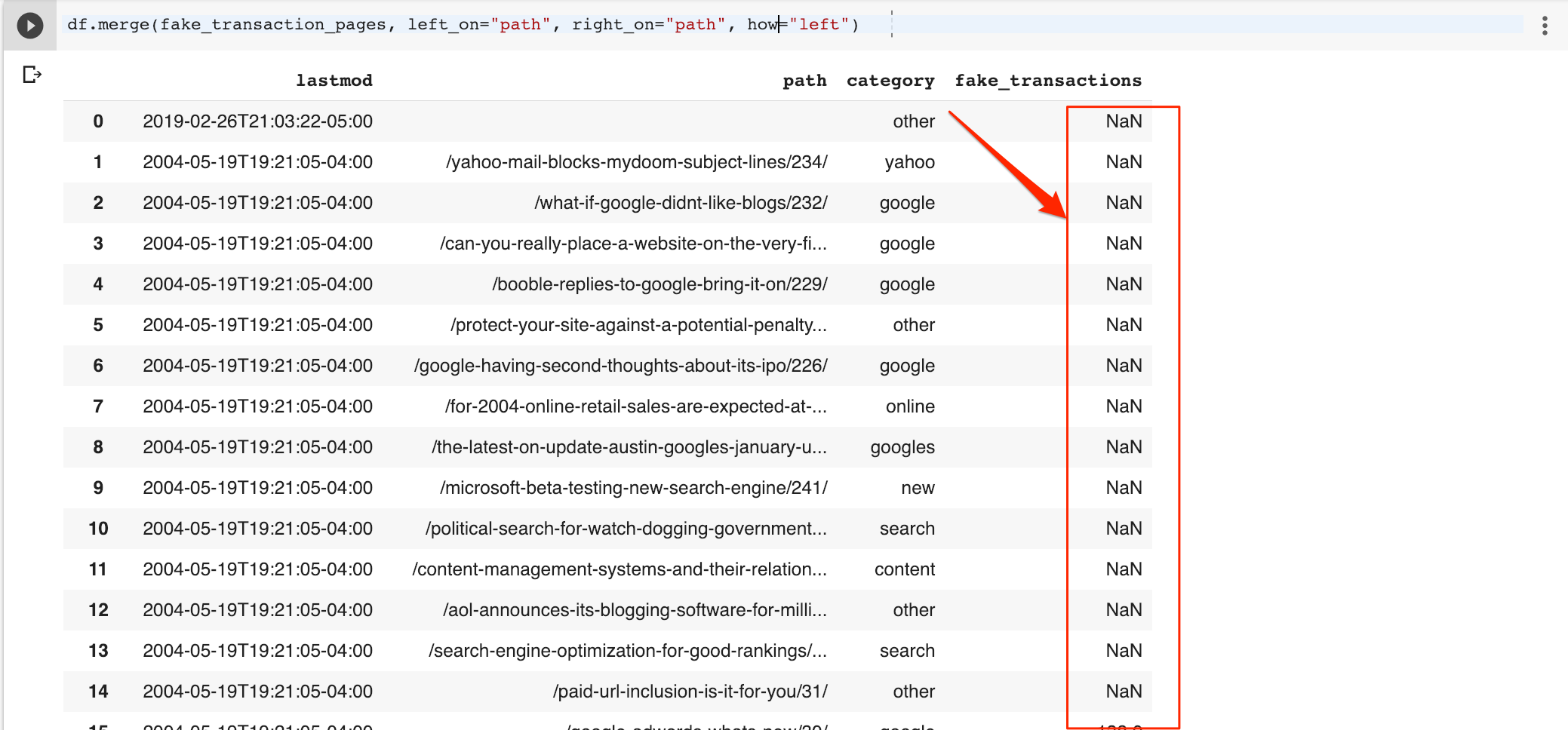
I can easily fill the missing values with zeros.
df.merge(fake_transaction_pages, left_on=”path”, right_on=”path”, how=”left”).fillna(0)
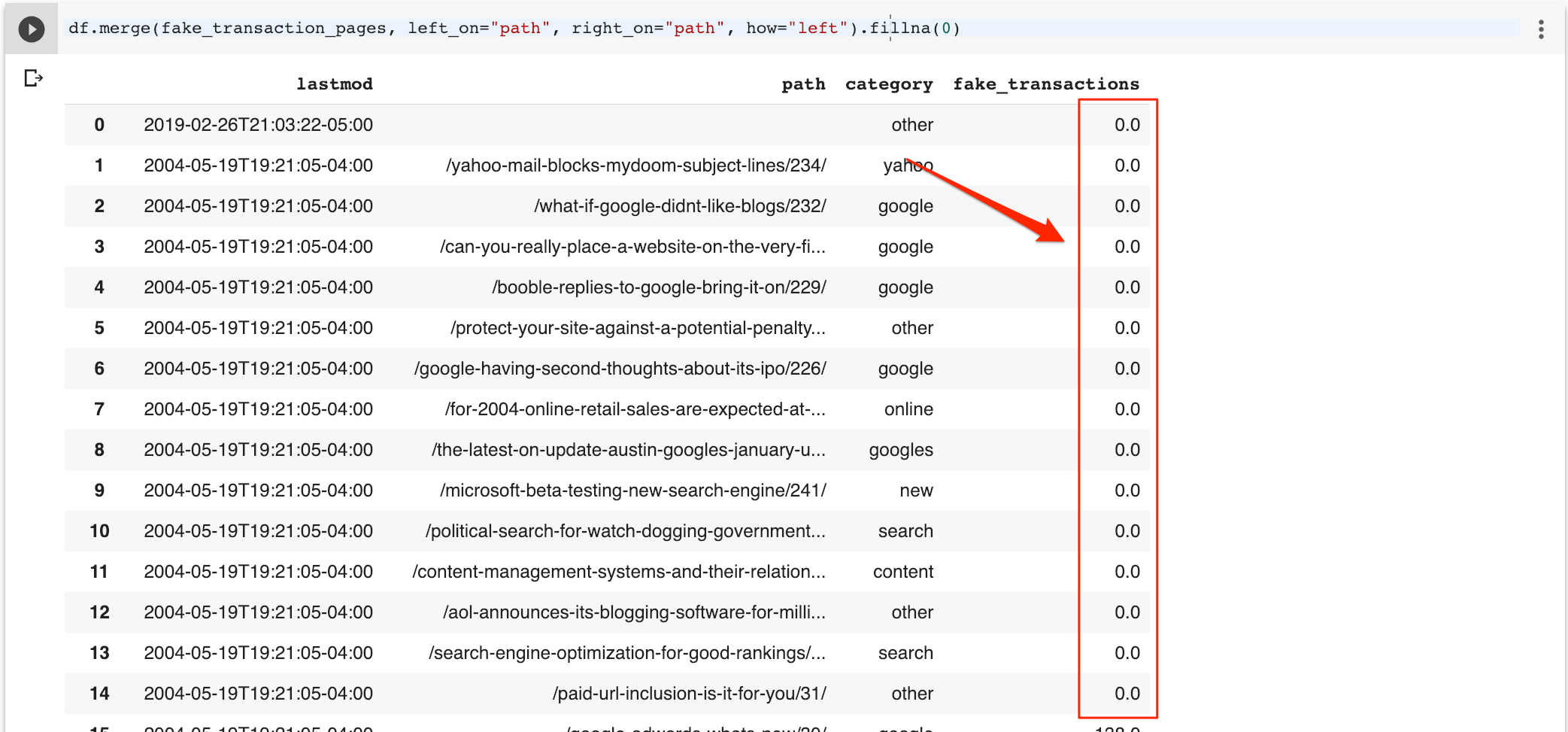
I can now get just the list of best sellers (by transaction) using this.
new_df=df.merge(fake_transaction_pages, left_on=”path”, right_on=”path”, how=”left”).fillna(0)
new_df[new_df.fake_transactions > 0]
Write XML Sitemaps
So far, we have seen how to group URLs using pandas data frames using different criteria, but how do we convert these URLs back into XML sitemaps? Quite easy!
There is always a hard way to do things and when it comes to creating XML sitemaps that would be to use BeautifulSoup, lxml or similar libraries to build the XML tree from scratch.
A simpler approach is to use a templating language like those used to build web apps. In our case, we will use a popular template language called Jinja2.
There are three components here:
- The template with a for loop to iterate of a context object called pages. It should be a Python tuple, where the first element is the URL, and the second one is the last modification timestamp.
- Our original pandas data frame has one index (the URL) and one column (the timestamp). We can call pandas itertuples() which will create a sequence that will be rendered nicely as an XML sitemap.
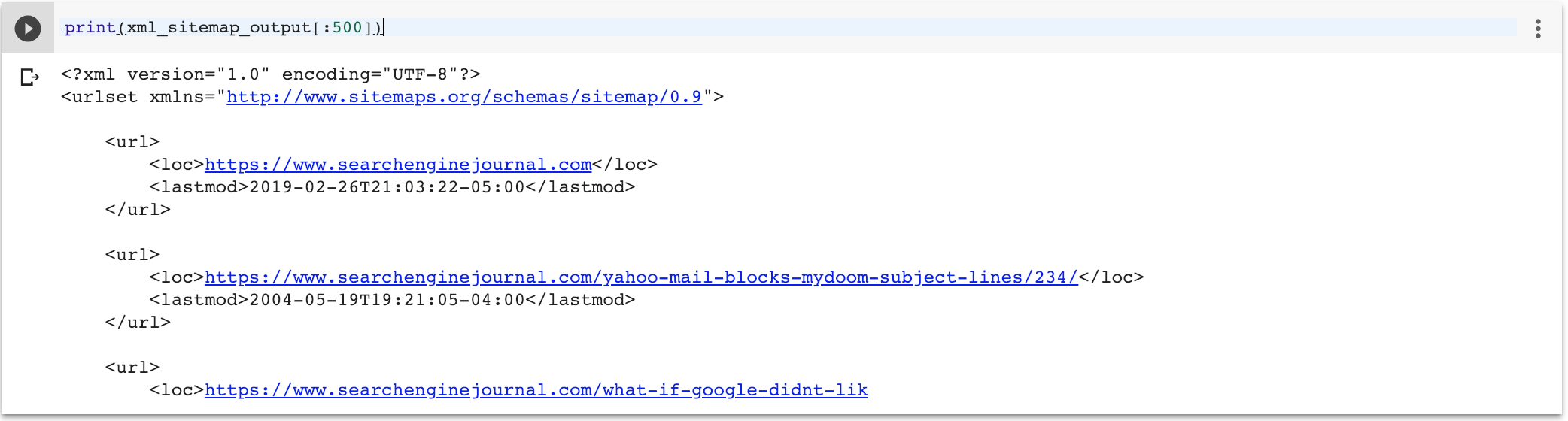
This is at least 10 times simpler than building the sitemaps from scratch!
Resources to Learn More
As usual, this is just a sample of the cool stuff you can do when you add Python scripting to your day-to-day SEO work. Here are some links to explore further.
- The official Python tutorial
- Parsing Tables and XML with Beautiful Soup 4
- 10 minutes to pandas
- Python Word Count
- How to join data frames in Python
- Extract URL from sitemap index
More Resources:
- How to Use Python to Analyze SEO Data: A Reference Guide
- How to Use XML Sitemaps to Boost SEO
- A Complete Guide to SEO: What You Need to Know in 2019
Image Credits
Screenshots taken by author, February 2019
Word cloud plot generated by author, February 2019
