

The primary goal of a search engine is to help users complete a task (and, of course, to sell advertising).
Sometimes that task can involve acquiring complex information. Sometimes the user simply needs a single answer to a question.
In this chapter, you’ll learn how search engines determine which category a query falls into and then how they determine the answer.
How Search Engines Qualify Query Types
Entire articles, or likely books, could be written on just this question alone.
But we’re going to try to summarize that all in a few hundred words.
Just to get it out of the way, RankBrain has little to no role here.
So what’s actually going on?
At its core, the first step in the process is to understand what information is being requested.
That is, classifying the query as a who, what, where, when, why or how query.
This classification can take place regardless of whether those specific words are included in the query as illustrated by:
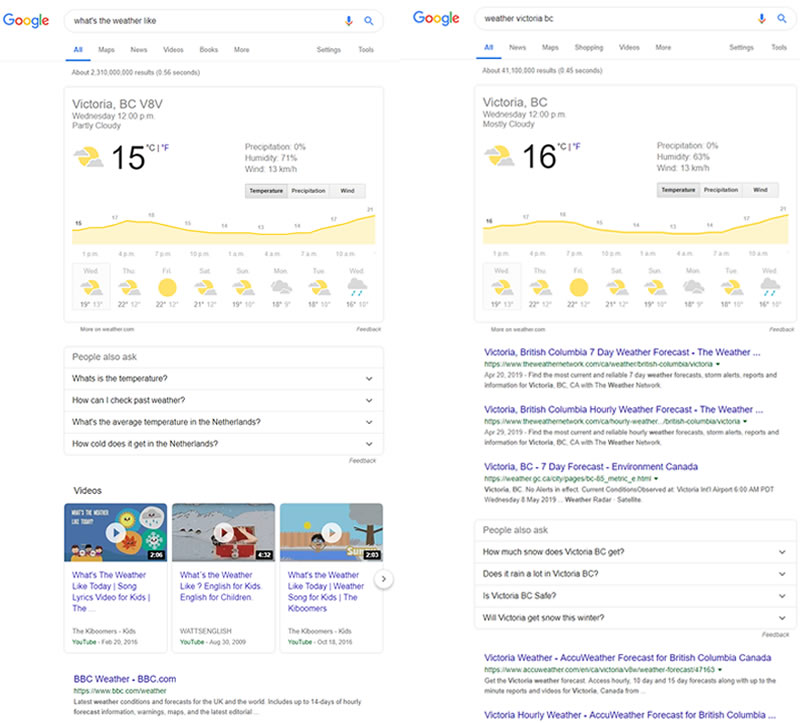
So, what we see happening here is two things:
- Google has determined the user is looking for an answer to a question as the likely primary intent.
- Google has determined that if that is not the primary intent of the user, that the secondary intents are likely different.
You may be wondering how the search engines can determine that the user is asking a question in the second example above. It isn’t built into the query, after all.
And in the first example, how do they infer that the user is looking for information on the weather in their location as opposed to just in general.
There are a number of systems that connect and provide data to create this environment. At its core, it relies on the following:
Canonical Queries
We tend to think of a query as a single request with a single response. This is not the case.
When a query is run, if there is not a known-good likely intent or when the engine may want to test their assumptions, one of the methods they have at their disposal is the creation of canonical queries.
Google outlined the process in a patent granted in 2016 titled, “Evaluating Semantic Interpretations Of A Search Query” (link is to my analysis for easier reading).
In short, the problem is summarized in the following image:
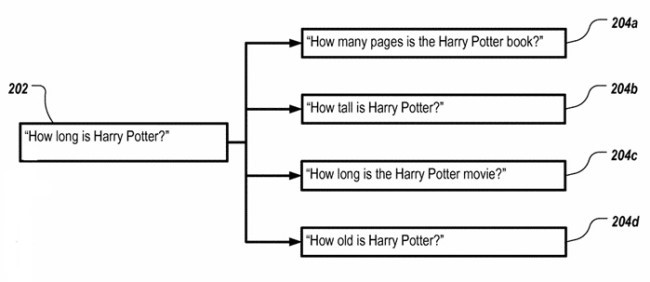
One query with multiple possible meanings.
In the patent, they outline a process by which all possible interpretations could be used to produce a result. In short, they would produce a result set for all five queries.
They would compare the results from the queries 204a, 204b, 204c, and 204d with the results from 202. The one from the 204-series that most closely matches that from 202 would be considered the likely intent.
Judging from the current results, it seems 204c won:
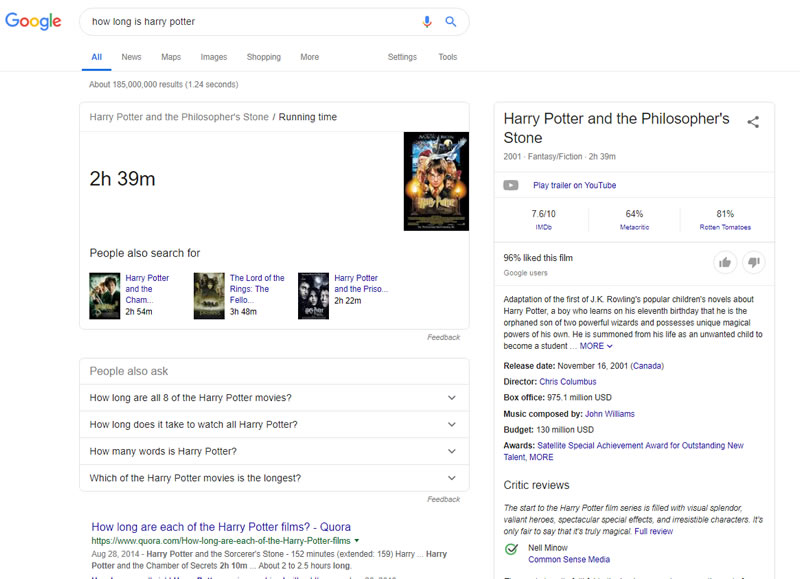
Which would have required two rounds of this process.
The first to select movies, the second to select which movie.
And the less people that click on a search result from this page, the more successful the result would be considered which is outlined in the patent in the statement:
“Using search results to evaluate the different semantic interpretations, other data sources such as click-through data, user-specific data, and others that are utilized when producing the search results are taken into account without the need to perform additional analysis.”
Relative to the context of the patent, this is not saying CTR is a direct metric. In fact, this statement is more akin to what John Mueller meant when answered to a question about Google using user metrics:
“… that’s something we look at across millions of different queries, and millions of different pages, and kind of see in general is this algorithm going the right way or is this algorithm going in the right way.”
Basically, they don’t use it to just the success of a single result, they use them to judge the success of the SERPs (including layout) as a whole.
Neural Matching
Google uses neural matching to essentially determine synonyms.
Basically, neural matching is an AI-driven process that allows Google (in this case) to understand synonyms from a very high level.
To use their example, it allows Google to produce results like:
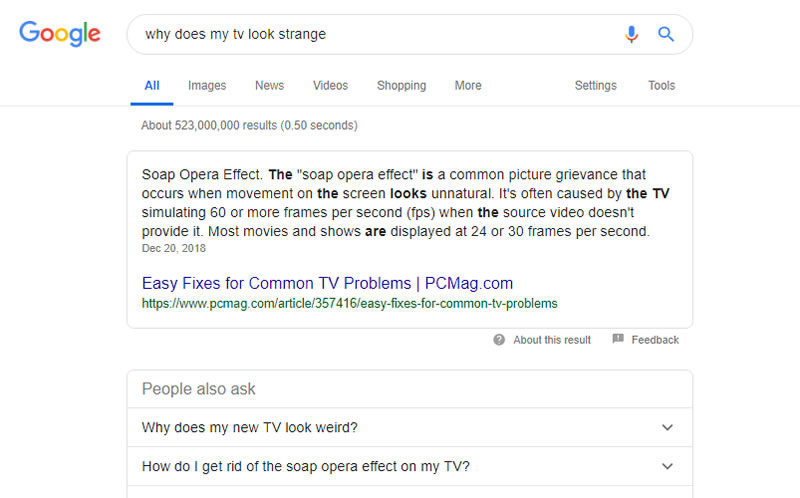
You can see that the query is for an answer to why my TV looks strange which the system recognized as a reference to the “soap opera effect.”
The ranking page doesn’t contain the word “strange.”
So much for keyword density.
Their AI systems are looking for synonyms at a very complex level to understand what information will address an intent, even when it’s not specifically requested.
Situational Similarities
There is a variety of examples and areas where situational context comes into play but at its core, we need to think of how query intent varies by situational conditions.
Above we mentioned a patent about systems that create canonical queries. Included in that patent is the idea of creating a template.
A template that could be used for other similar queries to start the process faster.
So, if it took resources to determine that when someone enters a single word that tends to have a broad context they likely want a definition, they can apply that more universally producing results like:
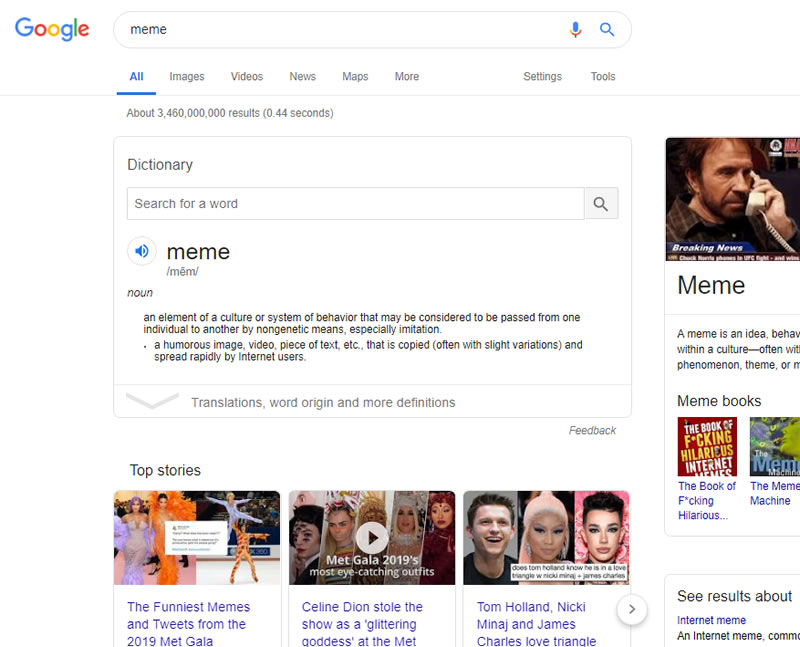
And from there begin looking for patterns of exceptions, like food.
And speaking of food, it serves as a great example supporting my belief (and I think logic) that it’s also very likely the engines use search volumes.
If more people search for restaurants than recipes for a term like “pizza”, I believe it’s safe to say they would use that as a metric and know if a food product doesn’t follow that pattern, then the template may not apply.
Seed Sets
Building on templates, I believe it is very likely, if not certain, that seed sets of data are used.
Scenarios where the engines train systems based on real-world understanding of what people want, programmed by engineers, and templates are generated.
Dave sat down at the Googleplex, wanted some pizza, Googled [pizza], got a top 10 list, thought, “that’s silly,” and started working with the team on a template.
I haven’t actually read anything about seed sets in this context, but it makes sense and most certainly exists.
Past Interactions
The search engines will test whether their understanding of an intent is correct by placing a result within an applicable layout and seeing what users do.
In our context above, if a possible intent of the query “what’s the weather like” is that I’m looking for an answer to a question, they will test that assumption.
It seems that on a large scale, it’s an answer people want.
So, What Does This Have to Do with Answering Questions?
Great question.
To understand how Google answers questions we needed to first understand how they can pull together the data to understand whether a query is a question.
Sure, it’s easy when it’s a who, what, where, when, why or how query.
But we need to think about how they know that a query like “weather” or “meme” is a query for a specific piece of information.
It is a Five Ws query without any Ws (or an H for that matter).
Once that is established using an interconnectedness of the techniques discussed above combined (and I’m sure a few I’ve missed), all that’s left is to find the answer.
So a user has entered a single word and the engine has jumped through its many hoops to establish that it is likely a request for a specific answer. They are now left to determine what that answer is.
For that, I’d recommend you start by reading what John Mueller has to say about featured snippets and work your way forward as applicable to your business.
Image Credits
Featured Image: Paulo Bobita
Screenshots taken by author
