
As SEO professionals, we generally focus on the question, “How do I rank my page?”
An equally, if not more important question we should be asking is, “How do search engines rank pages?”
Why Search Engines Rank Web Pages
Before we dive into how search engines rank web pages, let’s stop for a moment and think about why they rank them.
After all, it would be cheaper and easier for them to simply display pages randomly, by word count, by freshness, or any of a variety of easy sorting systems.
The reason they don’t do that is obvious. You wouldn’t use it.
So when we ask the question about rankings, what we need to always keep in mind is that the user we are trying to satisfy is not ours, they belong to the engine and the engines are loaning them to us.
If we misuse that user, they may not return to the engine and thus the engine can’t have that as their ad revenue will decline.
I like to think of the scenario like some of the resource pages on our own site.
If we recommend a tool or service, it is based on our experience with them and we believe they will serve our visitors as well. If we hear they do not, then we will remove them from our site.
That’s what the engines are doing.
But how?
Disclaimer
I do not have eavesdropping devices at Google or Bing.
Google has one sitting on my desk and another I carry around with me when I’m not at it, but for some reason, the message pickup doesn’t work the other way.
I state this to make clear that the following outline is based on about 20 years of watching the search engines evolve, reading patents (or more often – Bill Slawski’s analysis of patents), and starting each day for many years by reviewing the goings-on in the industry from SERP layout changes to acquisitions to algorithm updates.
Take what I am saying as an educated breakdown that’s hopefully about 90% right.
If you’re wondering why I think 90% – I learned from Bing’s Frédéric Dubut that 90% is a great number to use when guesstimating.
It’s Only A Simple 5 Steps – Easy
There are five steps to the complete process of ranking a page.
I am not including the technical challenges like load-balancing and I’m not talking about each various signal calculation.
I’m just talking about the core process that every query needs to go through to start its life as an information request and end it as a set of 10 blue links buried beneath a sea of ads.
Understand this process, understand who it is designed to serve, and you will be on your way to thinking properly about how to rank your pages to their users.
I also feel it’s necessary to note that the words used for these steps are mine and not some type of official name.
Feel free to use them but don’t expect any one of the engines to use the same terminology.
Step 1: Classify
The first step in the process is to classify the query coming in.
The classification of the query gives the engine the information it needs to perform all of the following steps.
Before complex classification could take place (read: back when the engines relied on keywords instead of entities) the engines basically had to apply the same signals to all queries.
As we will explore further below, this is no longer the case.
It’s in this first stage that the engine will apply such labels (again, not a technical term but an easy way to think about it) to a query such as:
- YMYL
- Local
- Unseen
- Adult
- Question
I have no idea how many different classifications there are but the first step the engine would need to make is to determine which apply to any given query.
Step 2: Context
The second step in the ranking process is to assign context.
Where possible, the engine needs to take into account any relevant information they have on the user entering the query.
We see this regularly for queries, even those we don’t ask. We see them here:
![]()
And we see them here:
![]()
The latter, of course, being an example of where I didn’t specifically enter the query.
Essentially, the second stage in the process is for the engine to determine what environmental and historical factors come into play.
They know the category of the query, here they apply, determine, or pull the data related to elements deemed relevant for that query category and type.
Some examples of environmental and historical information that would be considered are:
- Location
- Time
- Whether the query is a question
- The device being used for the query
- The format being used for the query
- Whether the query relates to previous queries
- Whether they have seen that query before
Step 3: Weights
Before we dive in let me ask you, how sick are you of hearing about RankBrain?
Well, buckle up because we’re about to bring it up again but only as an example of this third step.
Before an engine can determine what pages should rank they first need to determine which signals are most important.
For a query like [civil war] we get a result that looks like:
![]()
Solid result. But what happens if freshness had played a strong role? We’d end up with a result more like:
![]()
But we can’t rule out freshness. Had the query been [best shows on netflix], I’d care less about authority and more about how recently it was published.
I hardly want a heavily linked piece from 2008 outlining the best DVDs to order on their service.
So, with the query type in hand as well as the context elements pulled the engine can now rely on their understanding of which of their signals applies and with which weightings for the given combinations.
Some of this can certainly be accomplished manually by the many talented engineers and computer scientists employed and part of it will be handled by systems like RankBrain which is (for the 100th time) a machine learning algorithm designed to adjust the signal weights for previously unseen queries but later introduced into Google’s algorithms as a whole.
With the statement that roughly 90% of its ranking algorithms rely on machine learning, it can reasonably be assumed that Bing has similar systems.
Step 4: Layout
We’ve all seen it. In fact, you can see it in the civil war example above. For different queries the search results page layout changes.
The engines will determine what possible formats apply to a query intent, the user running the query, and the available resources.
The full page of the SERP for [civil war] looks like:
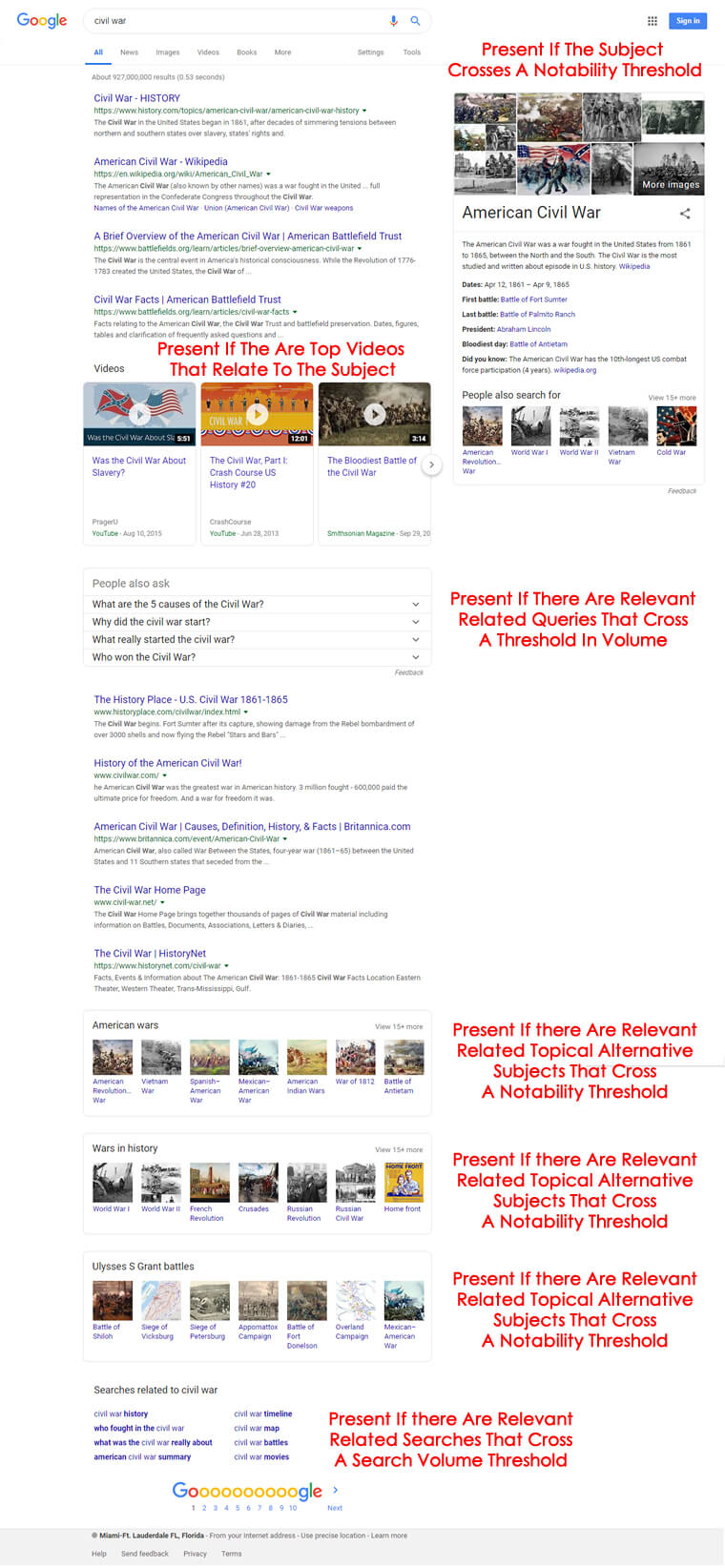
I’ve put an educated guess on the core factor used to determine when each element is present.
The truth is, it’s a moving target and relies on a knowledge of entities, how they connect, and how they are weighted.
That’s a highly complex subject so we won’t dive into it here.
What’s important to understand in the context of this piece is that the different elements of any given search results page need to be determined more-or-less on the fly.
This is to say, when a query is run and the first three steps completed the engine will reference a database of the various possible elements to insert onto the page, the possible placements, and then determine which will apply to the specific query.
An Aside: I noted above that the search results pages were generated more-or-less on the fly.
While this would be true of infrequent queries, for common queries it is far more likely that the engines keep a database of which elements they have already calculated to fit the likely user intent so as to not have to process that each time.
I would imagine there is a time limit on it after which it refreshes and I suspect that it refreshes the full entry at time of low use.
But moving on, the engine now knows the classification of a query, the context the information is being requested in, the signal weights that apply to such a query, and the layout most likely to meet the various possible intents for a query.
Finally, it’s time for ranking.
Step 5: Ranking
Interestingly, this is probably the easiest step of the process, though not as singular as one might think.
When we think of organic rankings we think of the 10 blue links. So let’s start there and look at the process thus far:
- The user enters a query.
- The engine considers the type of query and classifies it to understand what key criteria apply at a high level based on similar or identical previous query interactions.
- The engine considers the user’s position in space and time to consider their likely intents.
- The engine takes the query classifications and user-specific signals and uses this to determine which signals should hold what weights.
- The engine uses the above data to also determine which layouts, formats, and additional data may satisfy or supplement the user’s intent.
With all this in hand and with an algorithm already written, the engine needs simply crunch the numbers.
They will pull in the various sites that can be considered for ranking, apply the weights to their algorithms, and crunch the number to determine the order that the sites should appear in the search results.
Of course, they must do this for each element on the page in various ways.
Videos, stories, entities, and information all change, so the engines need to order not just the blue links but everything else on the page as well.
In Short
The ranking of the site is easy. It’s putting everything together to do it that’s the real work.
You may ask how understanding this can help you with your SEO efforts. It’s like understanding the core functions of how your computer works.
I can’t build a processor, but I know what they do, and I know what characteristics make for a faster one and how cooling impacts them.
Knowing this results in me having a faster machine that I need to update and upgrade far less often.
The same is true for SEO.
If you understand the core of how the engine function you will understand your place in that ecosystem.
And that will result in strategies designed with the engine in mind and serving the real user – their user.
Featured Image Credit: Paulo Bobita
