



Why are log files important for SEO?
For starters, they contain information that is not available elsewhere
Log files are also one of the only ways to see Google’s actual behavior on your site. They provide useful data for analysis and can help inform valuable optimizations and data-driven decisions.
Performing log file analysis regularly can help you to understand which content is being crawled and how often, and answer other questions around search engines crawling behavior on your site.
It can be an intimidating task to perform, so this post provides a starting point for your log file analysis journey.
What are Log Files?
Log files are records of who accessed a website and what content they accessed. They contain information on who has made the request to access the website (also known as ‘The Client’).
This could be a search engine bot, such as Googlebot or Bingbot, or a person viewing the site. Log file records are collected and kept by the web server of the site, and they are usually kept for a certain period of time.
What Data Does a Log File Contain?
A log file typically looks like this:
27.300.14.1 – – [14/Sep/2017:17:10:07 -0400] “GET https://allthedogs.com/dog1/ HTTP/1.1” 200 “https://allthedogs.com” “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
Broken down, this contains:
- The client IP.
- A timestamp with the date and time of the request.
- The method of accessing the site, which could be either GET or POST.
- The URL that is requested, which contains the page accessed.
- The Status Code of the page requested, which displays the success or failure of the request.
- The User Agent, which contains extra information about the client making the request, including the browser and bot (for example, if it is coming from mobile or desktop).
Certain hosting solutions may also provide other information, which could include:
- The host name.
- The server IP.
- Bytes downloaded.
- The time taken to make the request.
How to Access Log Files
As mentioned, log files are stored by the web server for a certain period of time and are only made available to the webmaster(s) of the site.
The method to access these depends on the hosting solution, and the best way to find out how they can be accessed is to search their docs, or even to Google it!
For some, you can access log files from a CDN or even your command line. These can then be downloaded locally to your computer and parsed from the format they are exported in.
Why is Log File Analysis Important?
Performing log file analysis can help provide useful insights into how your website is seen by search engine crawlers.
This can help you inform an SEO strategy, find answers to questions, or justify optimizations you may be looking to make.
It’s Not All About Crawl Budget
Crawl budget is an allowance given by Googlebot for the number of pages it will crawl during each individual visit to the site. Google’s John Mueller has confirmed that the majority of sites don’t need to worry too much about crawl budget.
However, it is still beneficial to understand which pages Google is crawling and how frequently it is crawling them.
I like to view it as making sure the site is being crawled both efficiently and effectively. Ensuring the key pages on the site are being crawled and that new pages and often changing pages are found and crawled quickly is important for all websites.
Different SEO Analyzers
There are several different tools available to help with log file analysis, including:
- Splunk.
- Logz.io.
- Screaming Frog Log File Analyser.
If you are using a crawling tool, there is often the ability to combine your log file data with a crawl of your site to expand your data set further and gain even richer insights with the combined data.
Search Console Log Stats
Google also offers some insights into how they are crawling your site within the Google Search Console Crawl Stats Report.
I won’t go into too much detail in this post, as you can find out more here.
Essentially, the report allows you to see crawl requests from Googlebot for the last 90 days.
You will be able to see a breakdown of status codes and file type requests, as well as which Googlebot type (Desktop, Mobile, Ad, Image, etc.) is making the request and whether they are new pages found (discovery) or previously crawled pages (refresh).
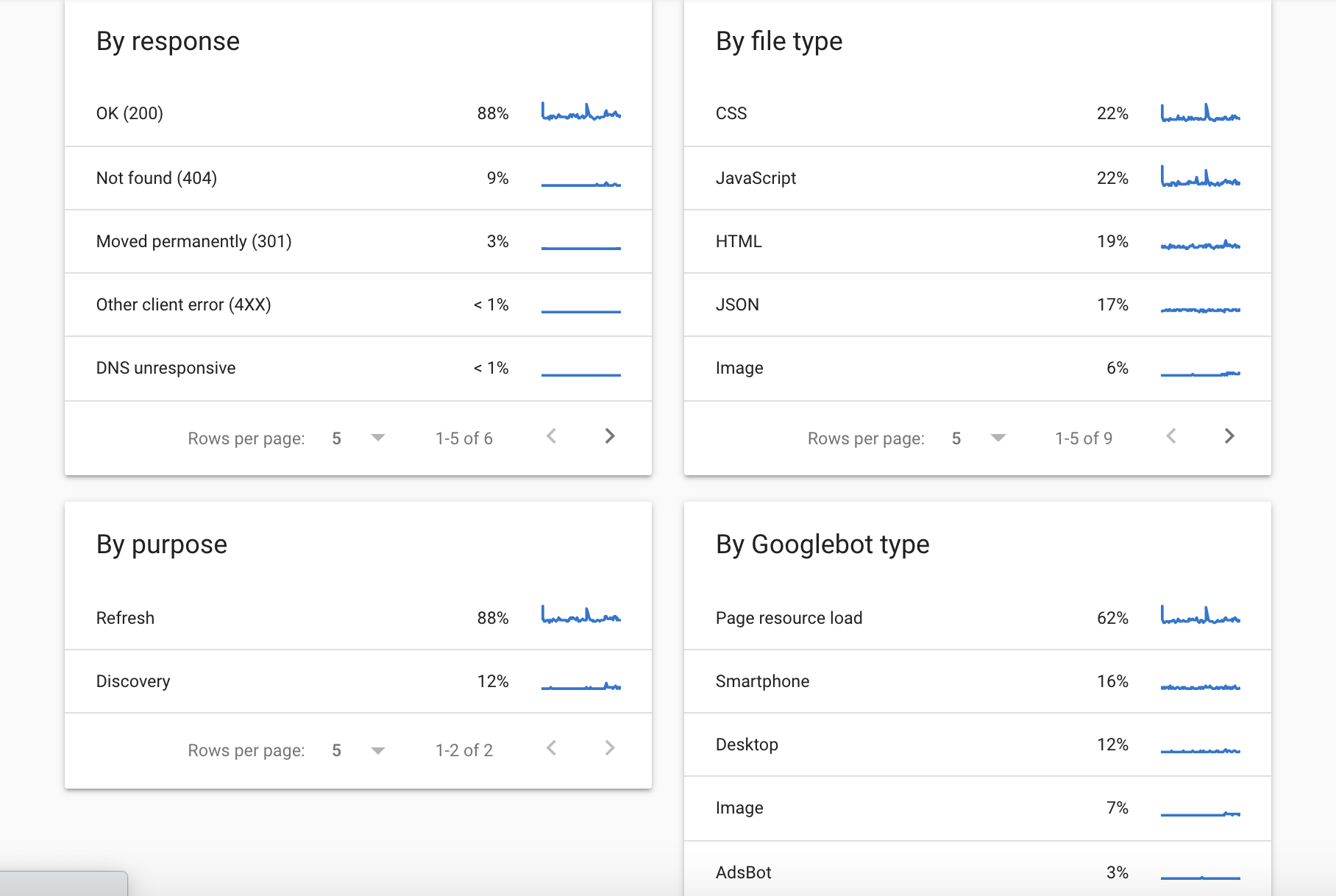 Screenshot from Google Search Console, September 2021
Screenshot from Google Search Console, September 2021GSC also shares some example pages that are crawled, along with the date and time of the request.
However, it’s worth bearing in mind that this is a sampled example of pages so will not display the full picture that you will see from your site’s log files.
Performing Log File Analysis
Once you have your log file data, you can use it to perform some analysis.
As log file data contains information from every time a client accesses your website, the recommended first step in your analysis is to filter out non-search engine crawlers so you are only viewing the data from search engine bots.
If you are using a tool to analyze log files, there should be an option to choose which user agent you would like to extract the information from.
You may already have some insights that you are looking for, or questions that you may find answers for.
However, if not, here are some example questions you can use to begin your log file analysis:
- How much of my site is actually getting crawled by search engines?
- Which sections of my site are/aren’t getting crawled?
- How deep is my site being crawled?
- How often are certain sections of my site being crawled?
- How often are regularly updated pages being crawled?
- How soon are new pages being discovered and crawled by search engines?
- How has site structure/architecture change impacted search engine crawling?
- How fast is my website being crawled and resources downloaded?
In addition, here are some suggestions for things to review from your log file data and use in your analysis.
Status Codes
You can use log files to understand how crawl budget is being distributed across your site.
Grouping together the status codes of the pages crawled will display how much resource is being given to important 200 status code pages compared to being used unnecessarily on broken or redirecting pages.
You can take the results from the log file data and pivot them in order to see how many requests are being made to different status codes.
You can create pivot tables in Excel but may want to consider using Python to create the pivots if you have a large amount of data to review.
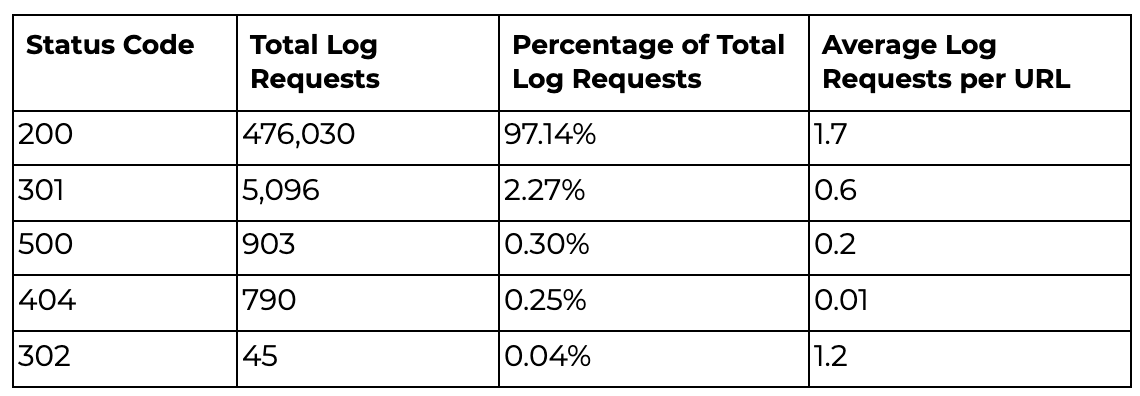 Screenshot from Microsoft Excel, September 2021
Screenshot from Microsoft Excel, September 2021Pivot tables are a nice way to visualize aggregated data for different categories and I find them particularly useful for analyzing large log file datasets.
Indexability
You can also review how search engine bots are crawling indexable pages on your site, compared to non-indexable pages.
Combining log file data with a crawl of your website can help you to understand if there are any pages that may be wasting crawl budget if they are not necessary to add to a search engine’s index.
 Screenshot from Microsoft Excel, September 2021
Screenshot from Microsoft Excel, September 2021Most vs. Least Crawled Pages
Log file data can also help you to understand which pages are being crawled the most by search engine crawlers.
This enables you to ensure that your key pages are being found and crawled, as well as that new pages are discovered efficiently, and regularly updated pages are crawled often enough.
Similarly, you will be able to see if there are any pages that are not being crawled or are not being seen by search engine crawlers as often as you would like.
Crawl Depth and Internal Linking
By combining your log file data with insights from a crawl of your website, you will also be able to see how deep in your site’s architecture search engine bots are crawling.
If, for example, you have key product pages at levels four and five but your log files show that Googlebot doesn’t crawl these levels often, you may want to look to make optimizations that will increase the visibility of these pages.
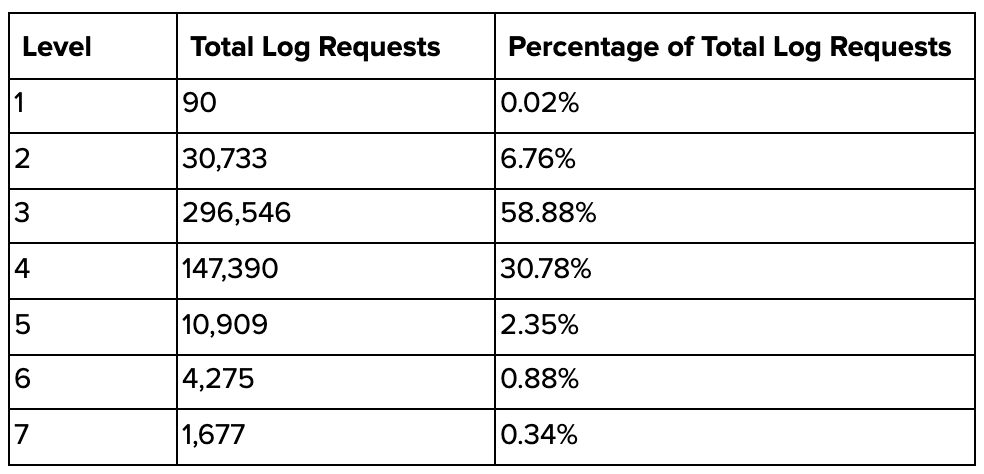 Screenshot from Microsoft Excel, September 2021
Screenshot from Microsoft Excel, September 2021One option for this is internal links, which is another important data point you can review from your combined log file and crawl insights.
Generally, the more internal links a page has, the easier it is to discover. So by combining log file data with internal link statistics from a site crawl, you can understand both the structure and discoverability of pages.
You can also map bot hits with internal links and conclude whether there is a correlation between the two.
Key Site Categories
Segmenting data from log files by folder structure can allow you to identify which categories are visited the most frequently by search engine bots, and ensure the most important sections of the site are seen often enough crawlers.
Depending on the industry, different site categories will be of different importance. Therefore, it’s important to understand on a site-by-site basis which folders are the most important and which need to be crawled the most.
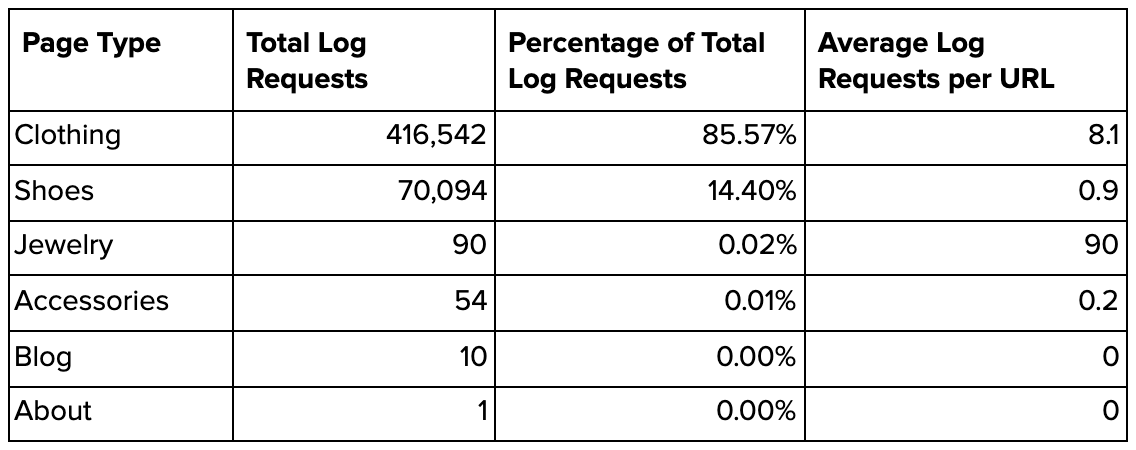 Screenshot from Microsoft Excel, September 2021
Screenshot from Microsoft Excel, September 2021Log file data over time
Collecting log file data over time is useful for reviewing how a search engine’s behavior changes over time.
This can be particularly useful if you are migrating content or changing a site’s structure and want to understand how the change has impacted search engines crawling of your site.
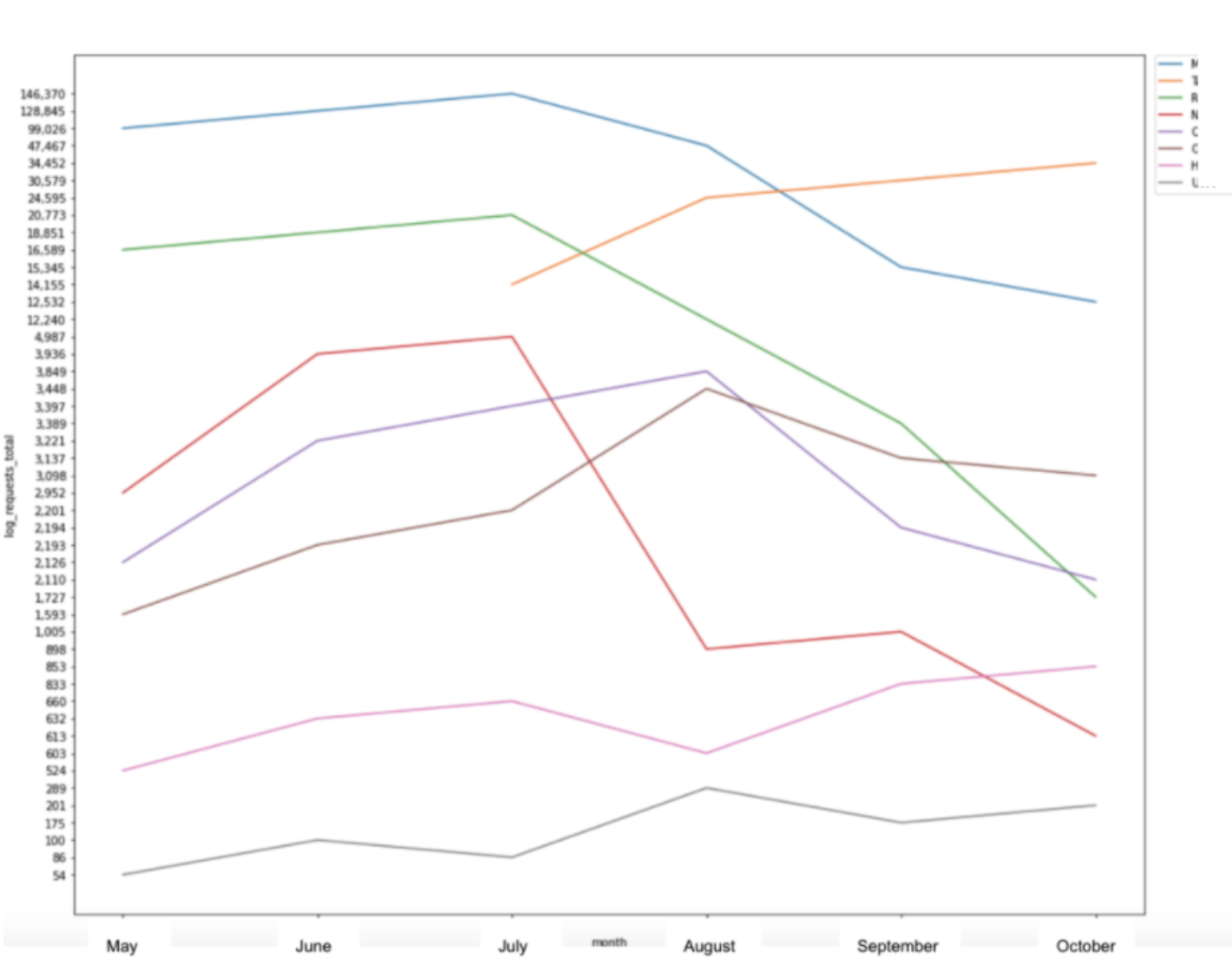 Screenshot from Microsoft Excel, September 2021
Screenshot from Microsoft Excel, September 2021The above example shows Google’s change in crawling when a new folder structure is added (yellow line) and another is removed and redirected (green line).
We can also see how long it took for Google to understand and update its crawling strategy.
Desktop vs. Mobile
As mentioned, log file data also shows the user agent that was used to access the page and can therefore inform you whether they were accessed by a mobile or desktop bot.
This can, in turn, help you to understand how many pages of your site are crawled by mobile vs. desktop and how this has changed over time.
You may also find that a certain section of your site is primarily being crawled by a desktop user agent and will therefore want to do further analysis as to why Google are preferring this over mobile-first crawling.
Optimizations to Make From Log File Analysis
Once you have performed some log file analysis and discovered valuable insights, there may be some changes you need to make to your site.
For example, if you discover that Google is crawling a large number of broken or redirecting pages on your site this can highlight an issue with these pages being too accessible for search engine crawlers.
You would therefore want to ensure that you don’t have any internal links to these broken pages, as well as clean up any redirecting internal links.
You may also be analyzing log file data in order to understand how changes that have been made have impacted crawling, or to collect data ahead of upcoming changes you or another team may be making.
For example, if you are looking to make a change to a website’s architecture, you will want to ensure that Google is still able to discover and crawl the most important pages on your site.
Other examples of changes you may look to make following log file analysis include:
- Removing non-200 status code pages from sitemaps.
- Fixing any redirect chains.
- Disallowing non-indexable pages from being crawled if there is nothing contained on them that is useful for search engines to find.
- Ensure there are no important pages that accidentally contain a noindex tag.
- Add canonical tags to highlight the importance of particular pages.
- Review pages that are not crawled as frequently as they should be and ensure they are easier to find by increasing the number of internal links to them.
- Update internal links to the canonicalized version of the page.
- Ensure internal links are always pointing to 200 status code, indexable pages.
- Move important pages higher up in the site architecture with more internal links from more accessible pages.
- Assess where crawl budget is being spent and make recommendations for potential site structure changes if needed.
- Review crawl frequency to site categories and ensure they are being crawled regularly.
Final Thoughts
Performing regular log file analysis is useful for SEO professionals to better understand how their website is crawled by search engines such as Google, as well as discovering valuable insights to help with making decisions based on the data.
I hope this has helped you to understand a little more about log files and how to begin your log file analysis journey with some examples of things to review.
More Resources:
- How Search Engines Crawl & Index: Everything You Need to Know
- How to Use Python to Parse & Pivot Server Log Files for SEO
- Advanced Technical SEO: A Complete Guide
Featured image: Alina Kvaratskhelia/Shutterstock
