

Finding webpages that have no links is difficult, but not impossible.
If there are pages on your website that users and search engines can’t reach, this is a problem you need to fix.
Fast.
These types of pages have a name: orphan pages.
In this post, you’ll learn what orphan pages are, why fixing them is important for SEO, and how to find every orphan page on your site.
What Is an Orphan Page?
A page without any links to it is called an orphan page.
Search engines, like Google, usually find new pages in one of two ways:
- The crawler follows a link from another page.
- The crawler finds the URL listed in your XML sitemap.
So if you want Google to crawl and index your page, they need to be able to find it.
Why Are Orphan Pages an SEO Issue?
Search engines can’t find orphan pages through links, so orphan pages often go unindexed and never show up in search results.
Even if your orphan pages are listed in your XML sitemap, they are still a problem for SEO.
Are Orphan Pages Bad?
Orphan pages aren’t great for either users or crawlers.
Users can’t reach those pages through your site’s natural structure so if there’s important or useful information on those pages, it’s wasted.
This can create a frustrating user experience.
With no internal links, no authority is passed to the pages, and search engines have no semantic or structural context in which to evaluate the page.
Without any way of knowing where the page fits into your site as a whole, it can be more difficult to determine which queries the page is relevant for.
Orphan vs. Dead End Pages
Before we dive into orphan pages, let’s take a moment to briefly clarify the difference between two SEO terms that can cause confusion.
As we’ve already established, an orphan page is a webpage that isn’t linked to by, or reachable from, any other page on the same website.
A dead-end page, on the other hand, is a webpage that doesn’t link to any other internal webpages or any external websites, thus creating a “dead end.”
When people land on this page, they can either hit back or just abandon the site.
When search engine crawlers land on the page, they have nowhere to go, and no link equity can be passed.
Today, with so many templates and themes available, it’s more difficult to create a dead end – but hardly impossible.
A dead end can easily be remedied by adding links to your on-page content, or making sure that sidebar or footer navigation is populated on every page.
All clear? Good.
Now let’s find your orphan pages.
1. Identify Your Crawlable Pages
You’ll need a list of all of the URLs that currently can be reached by crawling your site’s links.
You will need your own crawler – an SEO spider, to do this. ScreamingFrog is a good choice.
Whatever crawler you use, make sure it is set to crawl only pages that are indexable by search engines.
By that, I mean that it should not crawl pages that are:
- Noindexed
- Hidden from search engines by robots.txt.
Start the crawl from the homepage of the site.
Make sure to use the canonical URL, including proper https or http, and www or non-www.
Once you have crawled your site, export the URLs to a spreadsheet like this:
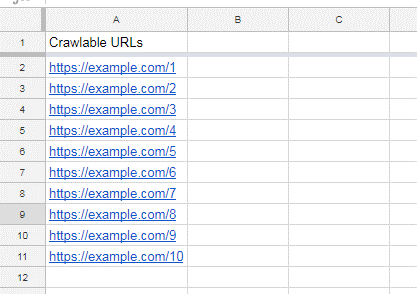
2. Resolve 2 Common Causes of Orphan Pages
There are two common causes of orphan pages that should be immediately addressed and dealt with.
Both these causes are essentially page duplicates that should automatically redirect consistently to only one URL.
If they don’t, it’s likely that some versions of the page are not linked to and as a result are orphans.
In this case, the fact that they are orphans isn’t the primary issue, the fact that they are duplicates is.
These may come up later while you are looking for orphan pages, and need to be dealt with, so it’s a good idea to get them out of the way beforehand.
Non-Canonical https/http or www/non-www
Every public page on your site should ideally use http or https consistently (preferably https), and www or non-www consistently.
To check if this is the case, try typing all of these variations of your site’s homepage into your browser:
- https://www.example.com
- http://www.example.com
- https://example.com
- http://example.com
All four variations should redirect automatically to the exact same URL.
For consistency, that page should be canonical to itself.
If one of these variations does not redirect properly, it can be a sign of similar problems on the wider site.
Check other URLs, using that variation, to see if it’s a more widespread issue.
You should test a few other pages of your site, and check your site’s .htaccess file to make sure that redirects for these are set up properly.
Here is how to force https in .htaccess. If you do this, verify that every page on your site has SSL capabilities, or your users will get a scary browser warning.
Here is how to force www or non-www. Again, verify that this won’t create any server errors.
Trailing Slashes
Another thing to watch out for is the consistent use of trailing slashes.
For example, these two URLs may produce the same content, but the URLs are not identical:
- https://example.com/page1/
- https://example.com/page1
Check a few pages on your site both with and without the trailing slash, and make sure that they redirect automatically to the same URL, and that they do so consistently.
Verify that this is set up properly in .htaccess.
Here’s how to force a trailing slash in .htaccess.
3. Get a List of URLs from Google Analytics
Crawlers, by definition, will have a difficult time finding orphan pages.
So using any SEO tool to find one is bound to be problematic.
One of the best places to start looking for orphan pages is your own Google Analytics data (or any other analytics packages you use).
As long as the pages in question have Google Analytics installed, if the page has ever been visited, there is a record of it somewhere in Google Analytics.
To get a comprehensive list of URLs, from the left sidebar, go to Behavior > Site Content > All Pages.
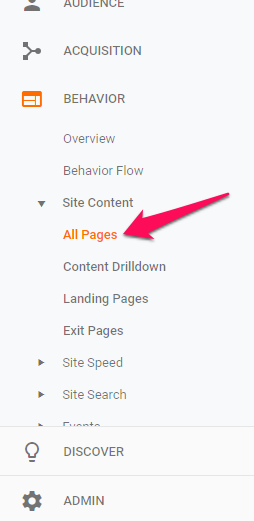
Because our orphan pages are difficult to find, the number of times they have been visited is likely to be quite low.
Click “Pageviews” so that the arrow is pointing upward, indicating that the list of URIs is sorted in ascending order from least to most pageviews.
This will move the pages most likely to be orphans to the top:

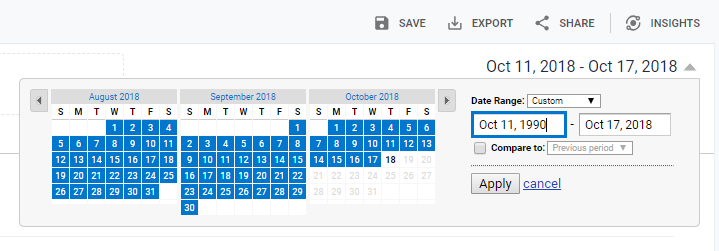
To make sure our list is as comprehensive as possible, go to the date range at the top right.
Set the starting date back to a time before Google Analytics was in place and click the Apply button:
Now we will need to expand our list of URLs as much as possible.
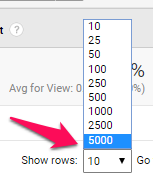
In the bottom right, click the Show rows dropdown menu and select the highest number of rows.
Our biggest obstacle is that Analytics can only list up to 5,000 URLs at a time:
If you have more than this, you will have to export 5,000 pages at a time until you have all your Google Analytics visitor data.
However, we are sorting pageviews by ascending, so our list should hopefully include all, and will most likely include most orphan URLs that have had a visitor.
It will likely take a bit of time for Analytics to fetch all of the data.
Be patient and don’t try to rush things, or you will risk crashing your browser.
Once the URLs are loaded, head up to the top right, select export, and export a Google Sheet, Excel file, or CSV spreadsheet to get your URLs.
If you’re slightly more technical, you can use the Google Analytics API to speed up this process; try using the pageviews metric against the pagePath dimension.
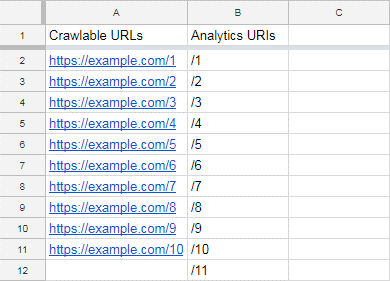
Now copy the URLs from your exported analytics file into your orphan page spreadsheet, like so:
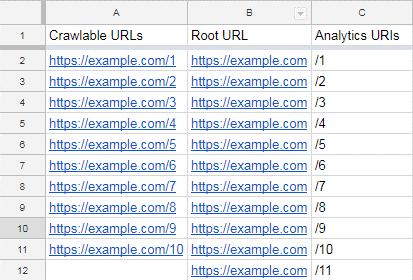
We will need to get these into URL format in order for them to be useful.
To do this, insert a new column and paste down the homepage URL, like so:
And use the concat() formula to combine these together into a URL in the next column over:
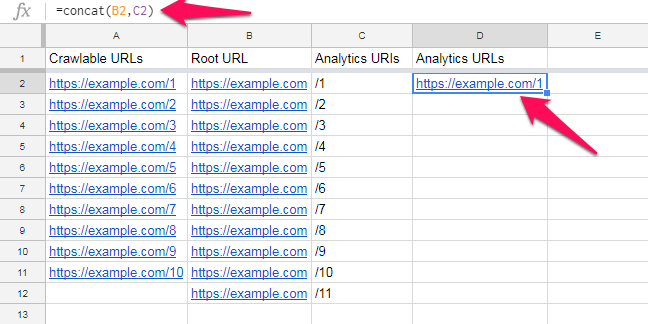
Then just drag the formula down to get the full list of URLs:
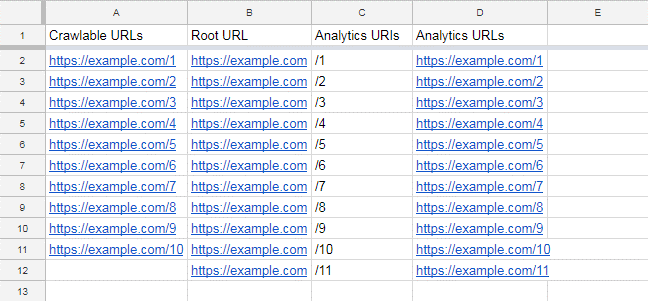
4. Identify Your Orphan URLs
To identify our orphan URLs, we will need to compare the list of Crawlable URLs and the list of found Analytics URLs in our spreadsheet.
In our hypothetical example, it’s obvious that https://example.com/11 is an orphan page, but in reality you will almost always have far more URLs to sift through, and we will need to automate the process of identifying our orphan URLs.
To do this, we need a formula that checks if each URL in our Analytics list is also found in our list of Crawlable URLs.
Here is an example of a formula that will accomplish this:
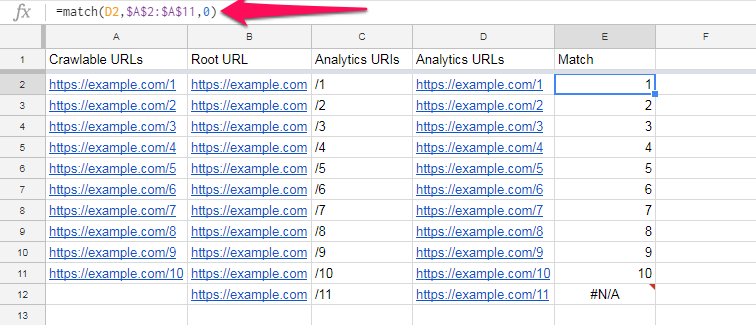
The “match” formula we have used in cell E2 here is:
=match(D2,$A$2:$A$11,0)
This formula checks if the URL in cell D2 is in the range $A$2:$A$11.
(If you’re not too familiar with spreadsheets, the dollar signs are there to make sure that when we drag the formula down the column, the range won’t change.)
The value “0” tells Google Sheets that the columns aren’t necessarily sorted. (See the Google Sheets documentation.)
If there is a match, the formula returns its position in the range, which in this case is the first position in the range.
What we’re more interested in, however, is if there isn’t a match.
As you can see, the formula returns the error “#N/A” for https://example.com/11, because it is not found in our list of Crawlable URLs. This means it is an orphan page.
To get a list of our orphan pages, then, all we need to do is sort our Match column to collect all of the “#N/A” results in one place.
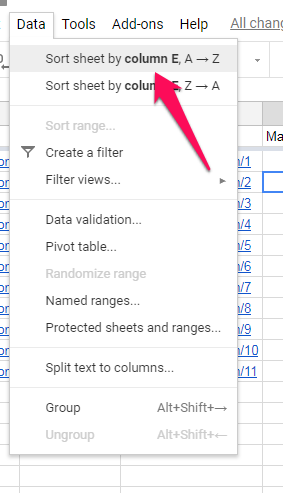
We can then copy our list of orphan URLs and paste them to a new sheet where we can address how to fix them.
5. Other Places to Look for Orphan URLs
You can repeat this process for identifying orphan URLs using data sources other than Google Analytics.
Any of the following tools will have a list of pages crawled from your site:
- SEMrush
- Ahrefs
- Moz Link Explorer
- Raven Tools
I would not recommend signing up for any of them exclusively to look for orphan pages, because they will need to somehow crawl these pages in order to find them.
SEMrush and Ahrefs have specific tools and practices to help you discover orphaned pages.
It is possible that in some cases these tools will find pages that aren’t directly crawlable because they were found using other means, usually at some point in history when the page was crawlable:
Work with your dev team to see if they can get the complete list of URLs on the site directly from the server, since this should be the most complete list available anywhere.
You can also look through your log files to find this data.
Log files contain information about:
- Who has visited your website.
- Where they came from.
- What pages they visited.
You can perform a second crawl of your site, ignoring directives like “nofollow” and “noindex”, and compare it to your original crawl.
There may be pages that are only accessible by crawlers who ignore those directives, and those can be another source of orphan pages.
Finally, you can get a list of URLs from the Google Search Console’s Search Analytics report.
Even though these pages are obviously indexed if they are showing up here, you may still find pages that aren’t crawlable from your internal links that will need to be fixed.
Conclusion: Finding & Fixing Orphan Pages
Orphan pages can’t be indexed by search engines if they don’t show up in your sitemap – and they can create other SEO issues even if they do.
When you have gone through these steps and found your orphan pages, ask yourself some questions:
- Is this page important? If it is, find where to integrate it. If not, remove it.
- Is this page ranking for any keywords, despite being an orphan page? If it is, find where to integrate it. If not, remove it.
- Where should the page exist within your website’s taxonomy?
- Is this page a duplicate or near duplicate? Consider folding that content into a similar page that isn’t an orphan.
- Is this page optimized? Could it be optimized and better linked from?
- Has the page been linked to from external sources?
Use the methods outlined in this post to find your orphan pages and get this issue resolved.
More Resources:
- Site Structure & Internal Linking in SEO: Why It’s Important
- SEO UX Play: Information Architecture & Linking Hierarchy
- 7 Reasons Why an HTML Sitemap Is a Must-Have
Image Credits
Featured Image: E2M Solutions
All screenshots taken by author
