

Last month here on Search Engine Journal, author Roger Montti covered the Google research paper on a new Natural Language Processing algorithm named SMITH.
The conclusion? That SMITH outperforms BERT for long documents.
Before we dive in, as of right now, SMITH is not live in Google’s algorithms. If my Spidey senses are right though, it’ll be rolling out with passage indexing, or preceding it.
Regular readers will know I have an interest in Machine Learning as it relates to search, and so I had to dive into the research paper for myself.
I also had to revisit some of the BERT docs to really wrap my brain about what was going on.
Is BERT about to be replaced?
Aren’t most documents on the web that aren’t thin content therefore long, and thus better for SMITH?
I’m going to take you to the conclusion first.
SMITH can do both jobs, and a bazooka can open a door. But you are still better off bringing your key, in many cases.
Why BERT or SMITH to Begin With?
What we’re really asking with this question is why a search engine would want to use Natural Language Processing (NLP).
The answer is quite simple; NLP assists in the transition from search engines understanding strings (keywords) to things (entities).
Where Google once had no idea what else should be on a page other than the keywords, or whether the content even made sense, with NLP it learned to better understand the context of the words.
The tone.
That “bank account” and “riverbank” are referring to different banks.
That the sentence, “Dave met up with Danny for a beer, beers, pint, glass, drink, ale, brew…” is not natural.
As an SEO professional, I miss the old days.
As someone who needs to find things on the internet, I do not.
Enter BERT
BERT is the best current NLP model we have for many, if not most, applications including understanding complex language structures.
The biggest leap forward with BERT in my opinion was in the first character, Bidirectional.
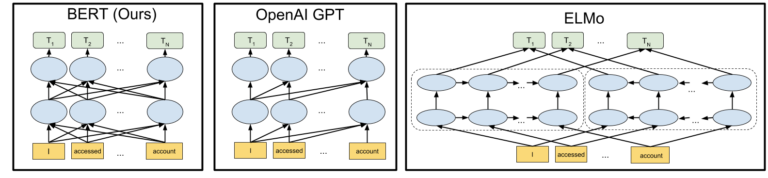
Rather than simply “reading” from left-to-right, it could also understand context going the other way around.
An overly simplified example might be in understanding the following sentence:
A car has lights.
If you can understand only left to right, when you hit the word “lights” you would classify the car as something that has lights because you have encountered the word car prior to it and could make the association.
But, if you were wanting to classify things on cars, lights may be missed because they had not been encountered prior to “car.”
It’s hard to learn in one direction only.
Additionally, the “under the hood” of BERT is remarkable and allows for processing language effectively with lower resource costs than previous models – an important consideration when one wants to apply it to the entire web.
One additional leap forward with BERT was its application of tokens.
In BERT, there are 30,000 tokens and each represents a common word with some leftover for fragments and characters in case a word is outside the 30,000.
Through the token processing and transformers, the way BERT was able to understand content gave it the ability I alluded to above, to understand that in the sentence:
“The man went to the bank. He then sat on the river bank.”
The first and last instances of “bank” should be assigned different values as they are referring to different things.
What About SMITH?
So now SMITH swaggers in, with better numbers and resource use in processing large documents.
BERT taps out at 512 tokens per document. After that, the computing cost gets too high for it to be functional, and often just isn’t.
SMITH, on the other hand, can handle 2,248 tokens. The documents can be 8x larger.
To understand why computing costs go up in a single NLP model, we simply need to consider what it takes to understand a sentence vs. a paragraph.
With a sentence, there is generally only one core concept to understand, and relatively few words meaning few connections between words and ideas to hold in memory.
Make that sentence a paragraph and the connections multiply exponentially.
Processing 8x the text actually requires many more times that in speed and memory optimization capacity using the same model.
SMITH gets around this by basically batching, and doing a lot of the processing offline.
But interestingly, for SMITH to function, it still leans heavily on BERT.
At its core, SMITH takes a document through the following process:
- It breaks the document into grouping sizes it can handle, favoring sentences (i.e., if the document would allocate 4.5 sentences to a block based on length, it would truncate that to four).
- It then processes each sentence block individually.
- A transformer then learns the contextual representations of each block and turns them into a document representation.
The diagram of the process looks like:
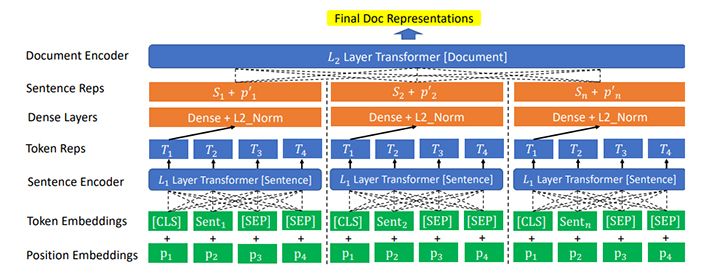
You can see a similarity between the bottom four rows, and the BERT process above. After that, we move to sentence-level representations and transforming that to a document level.
A Bit of Side Tech
Interestingly, to train the SMITH model, we take from BERT in two ways:
1. To train BERT they would take a word out of a sentence and supply options.
The better trained BERT was the more successful in choosing the right option. For example, they might give it the sentence:
The quick brown _____ jumped over the lazy dog.
Option 1 – lettuce
Options 2 – fox
The better trained, the more likely it is to pick Option 2.
This training method continues with SMITH, as well.
2. Because they’re training for large documents, they also take passages and remove sentences.
The more likely the system is at recognizing the omitted sentence, the better trained.
Same idea, different application.
I find this part interesting as an SEO pro, as it paints a world with Google generated content pieced together into walled-in SERPs. Sure, the user can leave, but why would they if Google can piece together short and long-form content from all the best sources in one place?
Think that won’t happen? It’s already starting and it looks like:
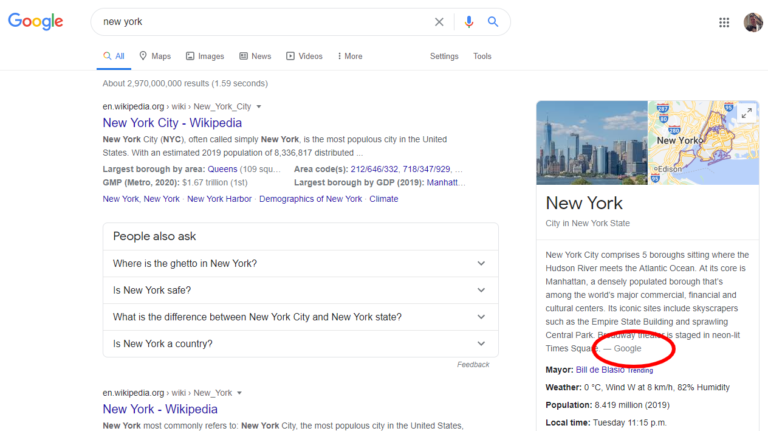
Though they’re still doing it poorly, as evidenced by this example from the Ryerson site:
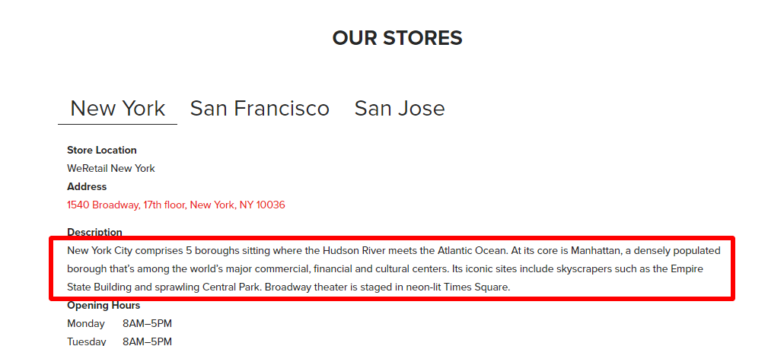
This next stage will just make it less blatant they’re just ripping off content.
Sounds Like SMITH Is Better…
It sure sounds like SMITH is better, doesn’t it?
And at many tasks, it will be.
But think of how you use the internet.
- “What’s the weather?”
- “Play a song.”
- “Directions to a restaurant.”
Many queries are satisfied not just with short answers, but with limited and often uncomplicated data.
Where SMITH gets involved is in understanding long and complex documents, and long and complex queries.
This will include the piecing together of documents and topics to create their own answers.
This will include determining how content can be broken apart (dare I say… into passages) so Google knows what to surface.
It will help each one to better understand how pages of content are related to each other, how links may be valued, and more.
So, each serves a purpose.
SMITH is the bazooka. It will paint the understanding of how things are. It is more costly in resources because it’s doing a bigger job, but is far less costly than BERT at doing that job.
BERT will help SMITH do that, and assist in understanding short queries and content chunks.
That is, until both are replaced, at which time we’ll move another leap forward and I’m going to bet that the next algorithm will be:
Bidirected Object-agnostic Regresson-based transformer Gateways.
The Star Trek nerds like me in the crowd will get it. 😉
More Resources:
- 5 Ways to Build a Google Algorithm Update Resistant SEO Strategy
- Why & How to Track Google Algorithm Updates
- 10 Important 2021 SEO Trends You Need to Know
Image Credits
All screenshots taken by author, January 2020
