

Topic clusters and recommender systems can help SEO experts to build a scalable internal linking architecture.
And as we know, internal linking can impact both user experience and search rankings. It’s an area we want to get right.
In this article, we will use Wikipedia data to build topic clusters and recommender systems with Python and the Pandas data analysis tool.
To achieve this, we will use the Scikit-learn library, a free software machine learning library for Python, with two main algorithms:
- TF-IDF: Term frequency-inverse document frequency.
- NMF: Non-negative matrix factorization, which is a group of algorithms in multivariate analysis and linear algebra that can be used to analyze dimensional data.
Specifically, we will:
- Extract all of the links from a Wikipedia article.
- Read text from Wikipedia articles.
- Create a TF-IDF map.
- Split queries into clusters.
- Build a recommender system.
Here is an example of topic clusters that you will be able to build:

Moreover, here’s the overview of the recommender system that you can recreate.
Ready? Let’s get a few definitions and concepts you’ll want to know out of the way first.
The Difference Between Topic Clusters & Recommender Systems
Topic clusters and recommender systems can be built in different ways.
In this case, the former is grouped by IDF weights and the latter by cosine similarity.
In simple SEO terms:
- Topic clusters can help to create an architecture where all articles are linked to.
- Recommender systems can help to create an architecture where the most relevant pages are linked to.
What Is TF-IDF?
TF-IDF, or term frequency-inverse document frequency, is a figure that expresses the statistical importance of any given word to the document collection as a whole.
TF-IDF is calculated by multiplying term frequency and inverse document frequency.
TF-IDF = TF * IDF
- TF: Number of times a word appears in a document/number of words in the document.
- IDF: log(Number of documents / Number of documents that contain the word).
To illustrate this, let’s consider this situation with Machine Learning as a target word:
- Document A contains the target word 10 times out of 100 words.
- In the entire corpus, 30 documents out of 200 documents also contain the target word.
Then, the formula would be:
TF-IDF = (10/100) * log(200/30)
What TF-IDF Is Not
TF-IDF is not something new. It’s not something that you need to optimize for.
According to John Mueller, it’s an old information retrieval concept that isn’t worth focusing on for SEO.
There is nothing in it that will help you outperform your competitors.
Still, TF-IDF can be useful to SEOs.
Learning how TF-IDF works gives insight into how a computer can interpret human language.
Consequently, one can leverage that understanding to improve the relevancy of the content using similar techniques.
What Is Non-negative Matrix Factorization (NMF)?
Non-negative matrix factorization, or NMF, is a dimension reduction technique often used in unsupervised learning that combines the product of non-negative features into a single one.
In this article, NMF will be used to define the number of topics we want all the articles to be grouped under.
Definition Of Topic Clusters
Topic clusters are groupings of related terms that can help you create an architecture where all articles are interlinked or on the receiving end of internal links.
Definition Of Recommender Systems
Recommender systems can help to create an architecture where the most relevant pages are linked to.
Building A Topic Cluster
Topic clusters and recommender systems can be built in different ways.
In this case, topic clusters are grouped by IDF weights and the Recommender systems by cosine similarity.
Extract All The Links From A Specific Wikipedia Article
Extracting links on a Wikipedia page is done in two steps.
First, select a specific subject. In this case, we use the Wikipedia article on machine learning.
Second, use the Wikipedia API to find all the internal links on the article.
Here is how to query the Wikipedia API using the Python requests library.
import requests
main_subject = 'Machine learning'
url = 'https://en.wikipedia.org/w/api.php'
params = {
'action': 'query',
'format': 'json',
'generator':'links',
'titles': main_subject,
'prop':'pageprops',
'ppprop':'wikibase_item',
'gpllimit':1000,
'redirects':1
}
r = requests.get(url, params=params)
r_json = r.json()
linked_pages = r_json['query']['pages']
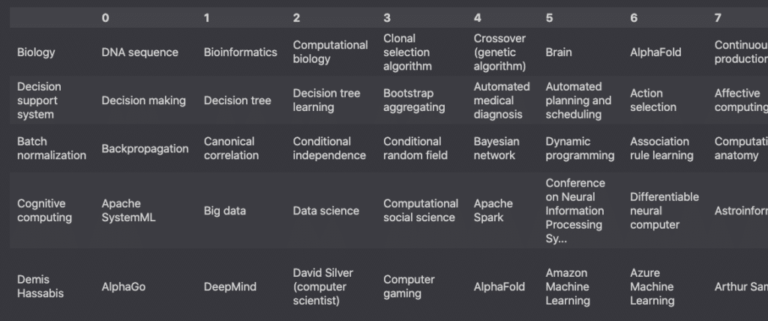
page_titles = [p['title'] for p in linked_pages.values()]
At last, the result is a list of all the pages linked from the initial article.
-
Screenshot from Pandas, February 2022
These links represent each of the entities used for the topic clusters.
Select A Subset Of Articles
For performance purposes, we will select only the first 200 articles (including the main article on machine learning).
# select first X articles num_articles = 200 pages = page_titles[:num_articles] # make sure to keep the main subject on the list pages += [main_subject] # make sure there are no duplicates on the list pages = list(set(pages))
Read Text From The Wikipedia Articles
Now, we need to extract the content of each article to perform the calculations for the TF-IDF analysis.
To do so, we will fetch the API again for each of the pages stored in the pages variable.
From each response, we will store the text from the page and add it to a list called text_db.
Note that you may need to install tqdm and lxml packages to use them.
import requests
from lxml import html
from tqdm.notebook import tqdm
text_db = []
for page in tqdm(pages):
response = requests.get(
'https://en.wikipedia.org/w/api.php',
params={
'action': 'parse',
'page': page,
'format': 'json',
'prop':'text',
'redirects':''
}
).json()
raw_html = response['parse']['text']['*']
document = html.document_fromstring(raw_html)
text = ''
for p in document.xpath('//p'):
text += p.text_content()
text_db.append(text)
print('Done')
This query will return a list in which each element represent the text of the corresponding Wikipedia page.
## Print number of articles
print('Number of articles extracted: ', len(text_db))
Output:
Number of articles extracted: 201
As we can see, there are 201 articles.
This is because we added the article on “Machine learning” on top of the top 200 links from that page.
Furthermore, we can select the first article (index 0) and read the first 300 characters to gain a better understanding.
# read first 300 characters of 1st article text_db[0][:300]
Output:
'\nBiology is the scientific study of life.[1][2][3] It is a natural science with a broad scope but has several unifying themes that tie it together as a single, coherent field.[1][2][3] For instance, all organisms are made up of cells that process hereditary information encoded in genes, which can '
Create A TF-IDF Map
In this section, we will rely on pandas and TfidfVectorizer to create a Dataframe that contains the bi-grams (two consecutive words) of each article.
Here, we are using TfidfVectorizer.
This is the equivalent of using CountVectorizer followed by TfidfTransformer, which you may see in other tutorials.
In addition, we need to remove the “noise”. In the field of Natural Language Processing, words like “the”, “a”, “I”, “we” are called “stopwords”.
In the English language, stopwords have low relevancy for SEOs and are overrepresented in documents.
Hence, using nltk, we will add a list of English stopwords to the TfidfVectorizer class.
import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer from nltk.corpus import stopwords
# Create a list of English stopwords stop_words = stopwords.words('english')
# Instantiate the class vec = TfidfVectorizer( stop_words=stop_words, ngram_range=(2,2), # bigrams use_idf=True )
# Train the model and transform the data tf_idf = vec.fit_transform(text_db)
# Create a pandas DataFrame df = pd.DataFrame( tf_idf.toarray(), columns=vec.get_feature_names(), index=pages )
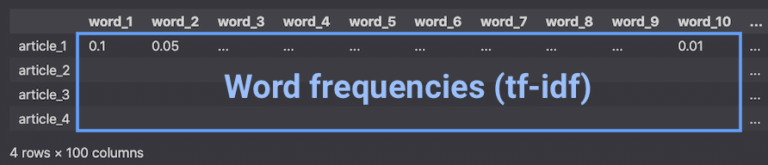
# Show the first lines of the DataFrame df.head()

In the DataFrame above:
- Rows are the documents.
- Columns are the bi-grams (two consecutive words).
- The values are the word frequencies (tf-idf).
Sort The IDF Vectors
Below, we are sorting the Inverse document frequency vectors by relevance.
idf_df = pd.DataFrame(
vec.idf_,
index=vec.get_feature_names(),
columns=['idf_weigths']
)
idf_df.sort_values(by=['idf_weigths']).head(10)
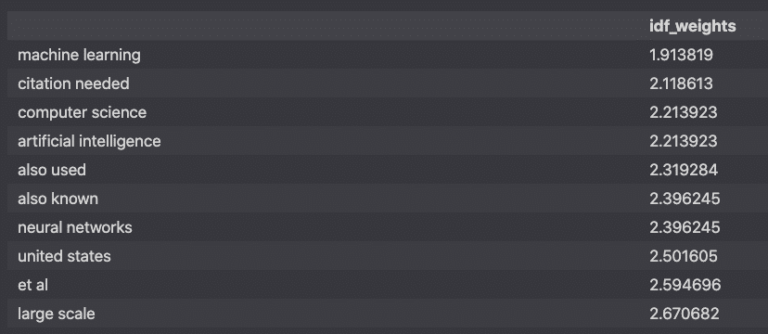
Specifically, the IDF vectors are calculated from the log of the number of articles divided by the number of articles containing each word.
The greater the IDF, the more relevant it is to an article.
The lower the IDF, the more common it is across all articles.
- 1 mention out of 1 articles = log(1/1) = 0.0
- 1 mention out of 2 articles = log(2/1) = 0.69
- 1 mention out of 10 articles = log(10/1) = 2.30
- 1 mention out of 100 articles = log(100/1) = 4.61
Split Queries Into Clusters Using NMF
Using the tf_idf matrix, we will split queries into topical clusters.
Each cluster will contain closely related bi-grams.
Firstly, we will use NMF to reduce the dimensionality of the matrix into topics.
Simply put, we will group 201 articles into 25 topics.
from sklearn.decomposition import NMF from sklearn.preprocessing import normalize # (optional) Disable FutureWarning of Scikit-learn from warnings import simplefilter simplefilter(action='ignore', category=FutureWarning) # select number of topic clusters n_topics = 25 # Create an NMF instance nmf = NMF(n_components=n_topics) # Fit the model to the tf_idf nmf_features = nmf.fit_transform(tf_idf) # normalize the features norm_features = normalize(nmf_features)
We can see that the number of bigrams stays the same, but articles are grouped into topics.
# Compare processed VS unprocessed dataframes
print('Original df: ', df.shape)
print('NMF Processed df: ', nmf.components_.shape)
Secondly, for each of the 25 clusters, we will provide query recommendations.
# Create clustered dataframe the NMF clustered df
components = pd.DataFrame(
nmf.components_,
columns=[df.columns]
)
clusters = {}
# Show top 25 queries for each cluster
for i in range(len(components)):
clusters[i] = []
loop = dict(components.loc[i,:].nlargest(25)).items()
for k,v in loop:
clusters[i].append({'q':k[0],'sim_score': v})
Thirdly, we will create a data frame that shows the recommendations.
# Create dataframe using the clustered dictionary
grouping = pd.DataFrame(clusters).T
grouping['topic'] = grouping[0].apply(lambda x: x['q'])
grouping.drop(0, axis=1, inplace=True)
grouping.set_index('topic', inplace=True)
def show_queries(df):
for col in df.columns:
df[col] = df[col].apply(lambda x: x['q'])
return df
# Only display the query in the dataframe
clustered_queries = show_queries(grouping)
clustered_queries.head()
Finally, the result is a DataFrame showing 25 topics along with the top 25 bigrams for each topic.
Building A Recommender System
Now, instead of building topic clusters, we will now build a recommender system using the same normalized features from the previous step.
The normalized features are stored in the norm_features variable.
# compute cosine similarities of each cluster
data = {}
# create dataframe
norm_df = pd.DataFrame(norm_features, index=pages)
for page in pages:
# select page recommendations
recommendations = norm_df.loc[page,:]
# Compute cosine similarity
similarities = norm_df.dot(recommendations)
data[page] = []
loop = dict(similarities.nlargest(20)).items()
for k, v in loop:
if k != page:
data[page].append({'q':k,'sim_score': v})
What the code above does is:
- Loops through each of the pages selected at the start.
- Selects the corresponding row in the normalized dataframe.
- Computes the cosine similarity of all the bigram queries.
- Selects the top 20 queries sorted by similarity score.
After the execution, we are left with a dictionary of pages containing lists of recommendations sorted by similarity score.
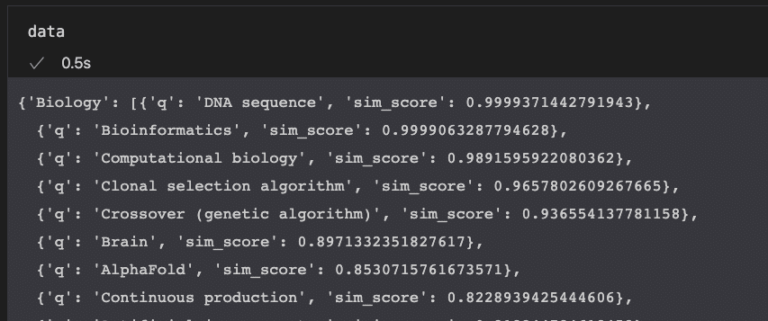
The next step is to convert that dictionary into a DataFrame.
# convert dictionary to dataframe
recommender = pd.DataFrame(data).T
def show_queries(df):
for col in df.columns:
df[col] = df[col].apply(lambda x: x['q'])
return df
show_queries(recommender).head()
The resulting DataFrame shows the parent query along with sorted recommended topics in each column.
Voilà!
We are done building our own recommender system and topic cluster.
Interesting Contributions From The SEO Community
I am a big fan of Daniel Heredia, who has also played around with TF-IDF by finding relevant words with TF IDF, textblob, and Python.
Python tutorials can be daunting.
A single article may not be enough.
If that is the case, I encourage you to read Koray Tuğberk GÜBÜR’s tutorial, which exposes a similar way to use TF-IDF.
Billy Bonaros also came up with a creative application of TF-IDF in Python and showed how to create a TF-IDF keyword research tool.
Conclusion
In the end, I hope you have learned a logic here that can be adapted to any website.
Understanding how topic clusters and recommender systems can help improve a website’s architecture is a valuable skill for any SEO pro wishing to scale your work.
Using Python and Scikit-learn, you have learned how to build your own – and have learned the basics of TF-IDF and of non-negative matrix factorization in the process.
More resources:
- How Search Engines Use Machine Learning: 9 Things We Know For Sure
- Python SEO Script: Top Keyword Opportunities Within Striking Distance
- Advanced Technical SEO: A Complete Guide
Featured Image: Kateryna Reka/Shutterstock
