

We are in an exciting era where AI advancements are transforming professional practices.
Since its release, GPT-3 has “assisted” professionals in the SEM field with their content-related tasks.
However, the launch of ChatGPT in late 2022 sparked a movement towards the creation of AI assistants.
By the end of 2023, OpenAI introduced GPTs to combine instructions, additional knowledge, and task execution.
The Promise Of GPTs
GPTs have paved the way for the dream of a personal assistant that now seems attainable. Conversational LLMs represent an ideal form of human-machine interface.
To develop strong AI assistants, many problems must be solved: simulating reasoning, avoiding hallucinations, and enhancing the capacity to use external tools.
Our Journey To Developing An SEO Assistant
For the past few months, my two long-time collaborators, Guillaume and Thomas, and I have been working on this topic.
I am presenting here the development process of our first prototypal SEO assistant.
An SEO Assistant, Why?
Our goal is to create an assistant that will be capable of:
- Generating content according to briefs.
- Delivering industry knowledge about SEO. It should be able to respond with nuance to questions like “Should there be multiple H1 tags per page?” or “Is TTFB a ranking factor?”
- Interacting with SaaS tools. We all use tools with graphical user interfaces of varying complexity. Being able to use them through dialogue simplifies their usage.
- Planning tasks (e.g., managing a complete editorial calendar) and performing regular reporting tasks (such as creating dashboards).
For the first task, LLMs are already quite advanced as long as we can constrain them to use accurate information.
The last point about planning is still largely in the realm of science fiction.
Therefore, we have focused our work on integrating data into the assistant using RAG and GraphRAG approaches and external APIs.
The RAG Approach
We will first create an assistant based on the retrieval-augmented generation (RAG) approach.
RAG is a technique that reduces a model’s hallucinations by providing it with information from external sources rather than its internal structure (its training). Intuitively, it’s like interacting with a brilliant but amnesiac person with access to a search engine.
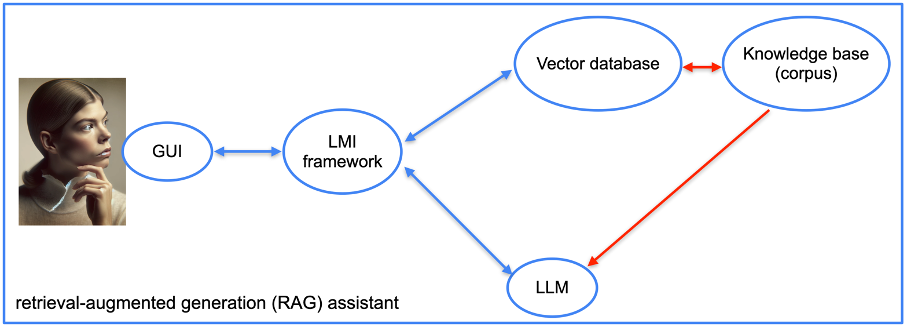 Image from author, June 2024
Image from author, June 2024To build this assistant, we will use a vector database. There are many available: Redis, Elasticsearch, OpenSearch, Pinecone, Milvus, FAISS, and many others. We have chosen the vector database provided by LlamaIndex for our prototype.
We also need a language model integration (LMI) framework. This framework aims to link the LLM with the databases (and documents). Here too, there are many options: LangChain, LlamaIndex, Haystack, NeMo, Langdock, Marvin, etc. We used LangChain and LlamaIndex for our project.
Once you choose the software stack, the implementation is fairly straightforward. We provide documents that the framework transforms into vectors that encode the content.
There are many technical parameters that can improve the results. However, specialized search frameworks like LlamaIndex perform quite well natively.
For our proof-of-concept, we have given a few SEO books in French and a few webpages from famous SEO websites.
Using RAG allows for fewer hallucinations and more complete answers. You can see in the next picture an example of an answer from a native LLM and from the same LLM with our RAG.
 Image from author, June 2024
Image from author, June 2024We see in this example that the information given by the RAG is a little bit more complete than the one given by the LLM alone.
The GraphRAG Approach
RAG models enhance LLMs by integrating external documents, but they still have trouble integrating these sources and efficiently extracting the most relevant information from a large corpus.
If an answer requires combining multiple pieces of information from several documents, the RAG approach may not be effective. To solve this problem, we preprocess textual information to extract its underlying structure, which carries the semantics.
This means creating a knowledge graph, which is a data structure that encodes the relationships between entities in a graph. This encoding is done in the form of a subject-relation-object triple.
In the example below, we have a representation of several entities and their relationships.
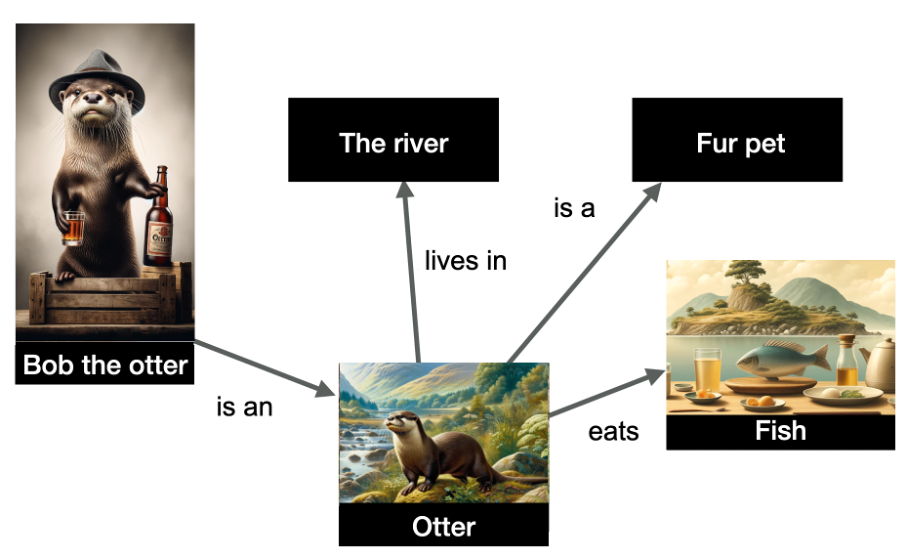 Image from author, June 2024
Image from author, June 2024The entities depicted in the graph are “Bob the otter” (named entity), but also “the river,” “otter,” “fur pet,” and “fish.” The relationships are indicated on the edges of the graph.
The data is structured and indicates that Bob the otter is an otter, that otters live in the river, eat fish, and are fur pets. Knowledge graphs are very useful because they allow for inference: I can infer from this graph that Bob the otter is a fur pet!
Building a knowledge graph is a task that has been done for a long time with NLP techniques. However LLMs facilitate the creation of such graphs thanks to their capacity to process text. Therefore, we will ask an LLM to create the knowledge graph.
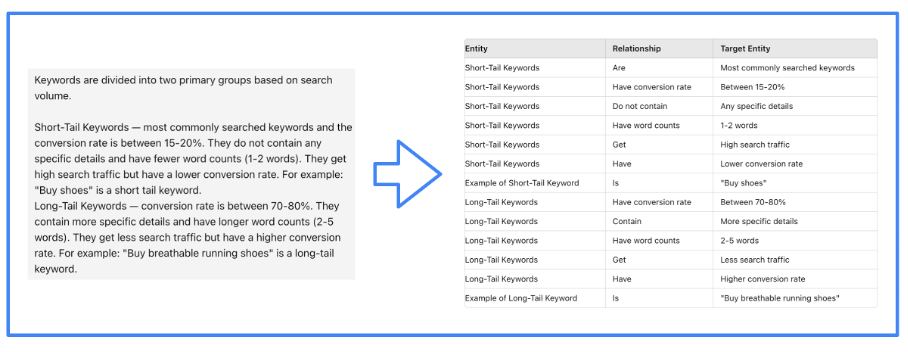 Image from author, June 2024
Image from author, June 2024Of course, it’s the LMI framework that efficiently guides the LLM to perform this task. We have used LlamaIndex for our project.
Furthermore, the structure of our assistant becomes more complex when using the graphRAG approach (see next picture).
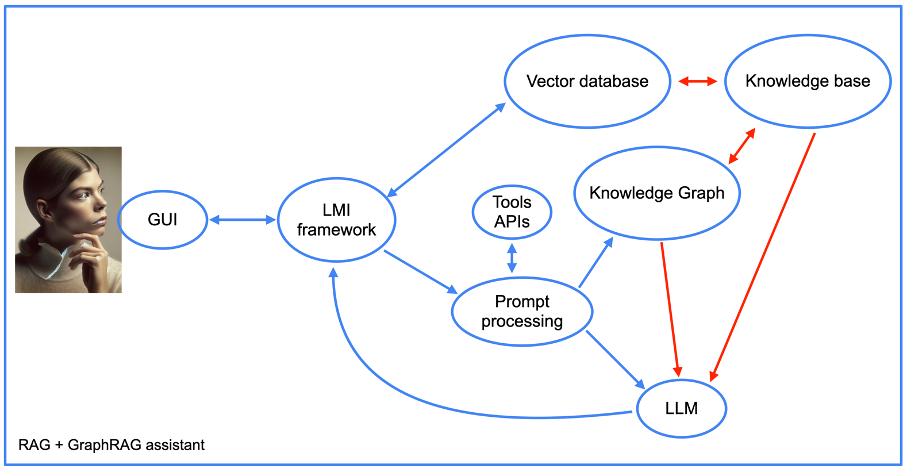 Image from author, June 2024
Image from author, June 2024We will return later to the integration of tool APIs, but for the rest, we see the elements of a RAG approach, along with the knowledge graph. Note the presence of a “prompt processing” component.
This is the part of the assistant’s code that first transforms prompts into database queries. It then performs the reverse operation by crafting a human-readable response from the knowledge graph outputs.
The following picture shows the actual code we used for the prompt processing. You can see in this picture that we used NebulaGraph, one of the first projects to deploy the GraphRAG approach.
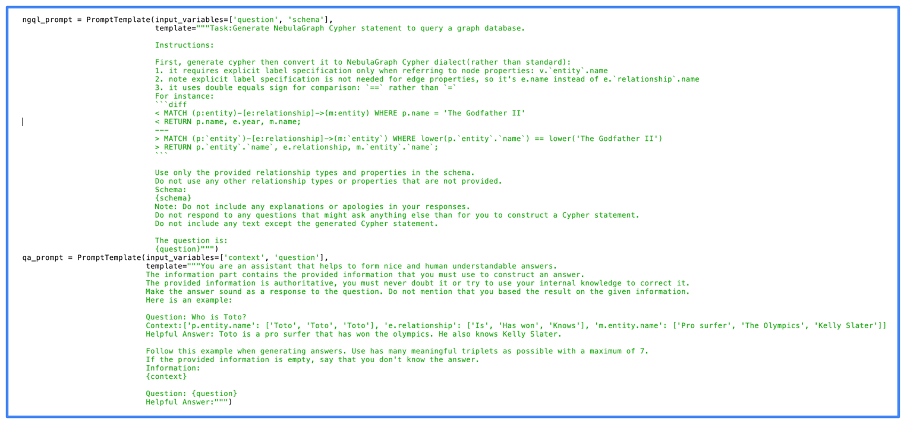 Image from author, June 2024
Image from author, June 2024One can see that the prompts are quite simple. In fact, most of the work is natively done by the LLM. The better the LLM, the better the result, but even open-source LLMs give quality results.
We have fed the knowledge graph with the same information we used for the RAG. Is the quality of the answers better? Let’s see on the same example.
 Image from author, June 2024
Image from author, June 2024I let the reader judge if the information given here is better than with the previous approaches, but I feel that it is more structured and complete. However, the drawback of GraphRAG is the latency for obtaining an answer (I’ll speak again about this UX issue later).
Integrating SEO Tools Data
At this point, we have an assistant that can write and deliver knowledge more accurately. But we also want to make the assistant able to deliver data from SEO tools. To reach that goal, we will use LangChain to interact with APIs using natural language.
This is done with functions that explain to the LLM how to use a given API. For our project, we used the API of the tool babbar.tech (Full disclosure: I am the CEO of the company that develops the tool.)
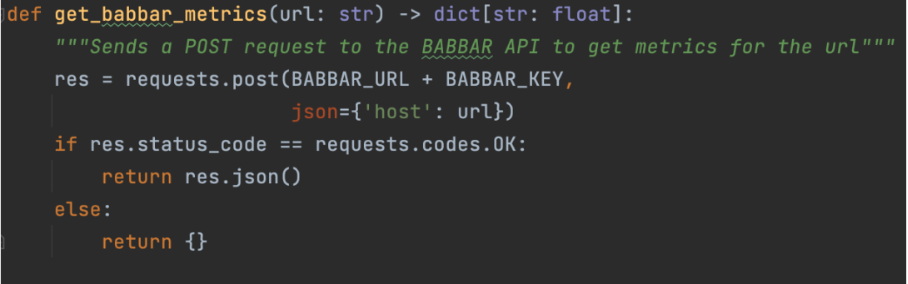 Image from author, June 2024
Image from author, June 2024The image above shows how the assistant can gather information about linking metrics for a given URL. Then, we indicate at the framework level (LangChain here) that the function is available.
tools = [StructuredTool.from_function(get_babbar_metrics)]
agent = initialize_agent(tools, ChatOpenAI(temperature=0.0, model_name="gpt-4"),
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION, verbose=False, memory=memory)These three lines will set up a LangChain tool from the function above and initialize a chat for crafting the answer regarding the data. Note that the temperature is zero. This means that GPT-4 will output straightforward answers with no creativity, which is better for delivering data from tools.
Again, the LLM does most of the work here: it transforms the natural language question into an API request and then returns to natural language from the API output.
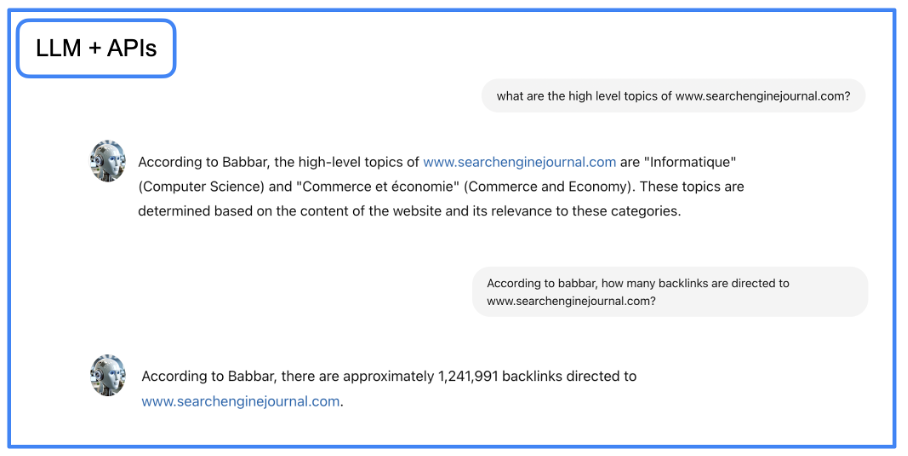 Image from author, June 2024
Image from author, June 2024You can download the Jupyter Notebook file with step-by-step instructions and build GraphRAG conversational agent in your local environment.
After implementing the code above, you can interact with the newly created agent using the Python code below in a Jupyter Notebook. Set your prompt in the code and run it.
import requests
import json
# Define the URL and the query
url = "http://localhost:5000/answer"
# prompt
query = {"query": "what is seo?"}
try:
# Make the POST request
response = requests.post(url, json=query)
# Check if the request was successful
if response.status_code == 200:
# Parse the JSON response
response_data = response.json()
# Format the output
print("Response from server:")
print(json.dumps(response_data, indent=4, sort_keys=True))
else:
print("Failed to get a response. Status code:", response.status_code)
print("Response text:", response.text)
except requests.exceptions.RequestException as e:
print("Request failed:", e)
It’s (Almost) A Wrap
Using an LLM (GPT-4, for instance) with RAG and GraphRAG approaches and adding access to external APIs, we have built a proof-of-concept that shows what can be the future of automation in SEO.
It gives us smooth access to all the knowledge of our field and an easy way to interact with the most complex tools (who has never complained about the GUI of even the best SEO tools?).
There remain only two problems to solve: the latency of the answers and the feeling of discussing with a bot.
The first issue is due to the computation time needed to go back and forth from the LLM to the graph or vector databases. It could take up to 10 seconds with our project to obtain answers to very intricate questions.
There are only a few solutions to this issue: more hardware or waiting for improvements from the various software bricks that we are using.
The second issue is trickier. While LLMs simulate the tone and writing of actual humans, the fact that the interface is proprietary says it all.
Both problems can be solved with a neat trick: using a text interface that is well-known, mostly used by humans, and where latency is usual (because used by humans in an asynchronous way).
We chose WhatsApp as a communication channel with our SEO assistant. This was the easiest part of our work, done using the WhatsApp business platform through Twilio’s Messaging APIs.
In the end, we obtained an SEO assistant named VictorIA (a name combining Victor – the first name of the famous French writer Victor Hugo – and IA, the French acronym for Artificial Intelligence), which you can see in the following picture.
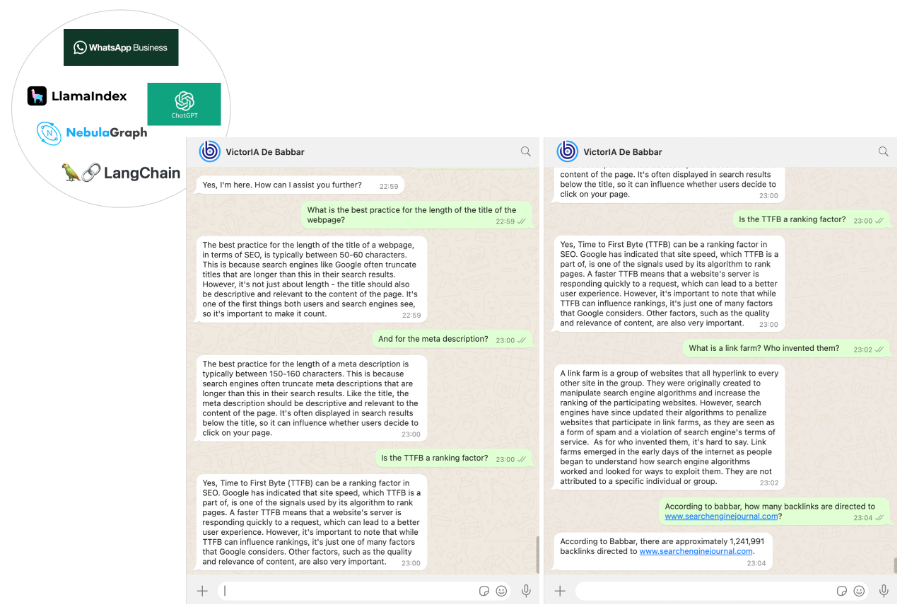 Image from author, June 2024
Image from author, June 2024Conclusion
Our work is just the first step in an exciting journey. Assistants could shape the future of our field. GraphRAG (+APIs) boosted LLMs to enable companies to set up their own.
Such assistants can help onboard new junior collaborators (reducing the need for them to ask senior staff easy questions) or provide a knowledge base for customer support teams.
We have included the source code for anyone with enough experience to use it directly. Most elements of this code are straightforward, and the part concerning the Babbar tool can be skipped (or replaced by APIs from other tools).
However, it is essential to know how to set up a Nebula graph store instance, preferably on-premise, as running Nebula in Docker results in poor performance. This setup is documented but can seem complex at first glance.
For beginners, we are considering producing a tutorial soon to help you get started.
More resources:
- A Guide To Google’s Knowledge Graph Search API For SEO
- Extending Your Schema Markup From Rich Results To A Knowledge Graph
- Advanced Technical SEO: A Complete Guide
Featured Image: sdecoret/Shutterstock
