

Crawling is essential for every website, large and small alike.
If your content is not being crawled, you have no chance to gain visibility on Google surfaces.
Let’s talk about how to optimize crawling to give your content the exposure it deserves.
What Is Crawling In SEO
In the context of SEO, crawling is the process in which search engine bots (also known as web crawlers or spiders) systematically discover content on a website.
This may be text, images, videos, or other file types that are accessible to bots. Regardless of the format, content is exclusively found through links.
How Web Crawling Works
A web crawler works by discovering URLs and downloading the page content.
During this process, they may pass the content over to the search engine index and will extract links to other web pages.
These found links will fall into different categorizations:
- New URLs that are unknown to the search engine.
- Known URLs that give no guidance on crawling will be periodically revisited to determine whether any changes have been made to the page’s content, and thus the search engine index needs updating.
- Known URLs that have been updated and give clear guidance. They should be recrawled and reindexed, such as via an XML sitemap last mod date time stamp.
- Known URLs that have not been updated and give clear guidance. They should not be recrawled or reindexed, such as a HTTP 304 Not Modified response header.
- Inaccessible URLs that can not or should not be followed, for example, those behind a log-in form or links blocked by a “nofollow” robots tag.
- Disallowed URLs that search engine bots will not crawl, for example, those blocked by the robots.txt file.
All allowed URLs will be added to a list of pages to be visited in the future, known as the crawl queue.
However, they will be given different levels of priority.
This is dependent not only upon the link categorization but a host of other factors that determine the relative importance of each page in the eyes of each search engine.
Most popular search engines have their own bots that use specific algorithms to determine what they crawl and when. This means not all crawl the same.
Googlebot behaves differently from Bingbot, DuckDuckBot, Yandex Bot, or Yahoo Slurp.
Why It’s Important That Your Site Can Be Crawled
If a page on a site is not crawled, it will not be ranked in the search results, as it is highly unlikely to be indexed.
But the reasons why crawling is critical go much deeper.
Speedy crawling is essential for time-limited content.
Often, if it is not crawled and given visibility quickly, it becomes irrelevant to users.
For example, audiences will not be engaged by last week’s breaking news, an event that has passed, or a product that is now sold out.
But even if you don’t work in an industry where time to market is critical, speedy crawling is always beneficial.
When you refresh an article or release a significant on-page SEO change, the faster Googlebot crawls it, the faster you’ll benefit from the optimization – or see your mistake and be able to revert.
You can’t fail fast if Googlebot is crawling slowly.
Think of crawling as the cornerstone of SEO; your organic visibility is entirely dependent upon it being done well on your website.
Measuring Crawling: Crawl Budget Vs. Crawl Efficacy
Contrary to popular opinion, Google does not aim to crawl and index all content of all websites across the internet.
Crawling of a page is not guaranteed. In fact, most sites have a substantial portion of pages that have never been crawled by Googlebot.
If you see the exclusion “Discovered – currently not indexed” in the Google Search Console page indexing report, this issue is impacting you.
But if you do not see this exclusion, it doesn’t necessarily mean you have no crawling issues.
There is a common misconception about what metrics are meaningful when measuring crawling.
Crawl budget fallacy
SEO pros often look to crawl budget, which refers to the number of URLs that Googlebot can and wants to crawl within a specific time frame for a particular website.
This concept pushes for maximization of crawling. This is further reinforced by Google Search Console’s crawl status report showing the total number of crawl requests.
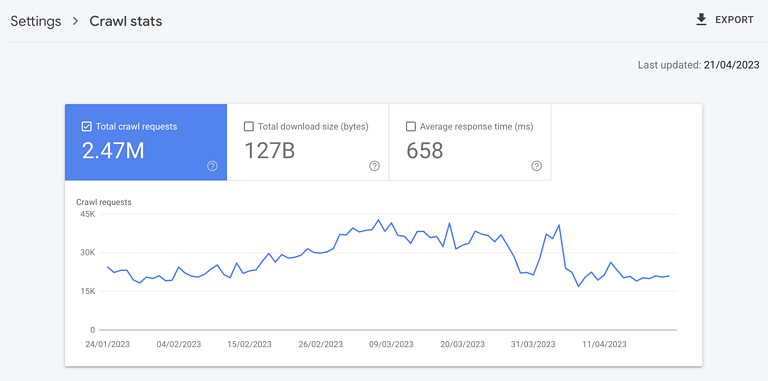 Screenshot from Google Search Console, May 2023
Screenshot from Google Search Console, May 2023But the idea that more crawling is inherently better is completely misguided. The total number of crawls is nothing but a vanity metric.
Enticing 10 times the number of crawls per day doesn’t necessarily correlate against faster (re)indexing of content you care about. All it correlates with is putting more load on your servers, costing you more money.
The focus should never be on increasing the total amount of crawling, but rather on quality crawling that results in SEO value.
Crawl Efficacy Value
Quality crawling means reducing the time between publishing or making significant updates to an SEO-relevant page and the next visit by Googlebot. This delay is the crawl efficacy.
To determine the crawl efficacy, the recommended approach is to extract the created or updated datetime value from the database and compare it to the timestamp of the next Googlebot crawl of the URL in the server log files.
If this is not possible, you could consider calculating it using the lastmod date in the XML sitemaps and periodically query the relevant URLs with the Search Console URL Inspection API until it returns a last crawl status.
By quantifying the time delay between publishing and crawling, you can measure the real impact of crawl optimizations with a metric that matters.
As crawl efficacy decreases, the faster new or updated SEO-relevant content will be shown to your audience on Google surfaces.
If your site’s crawl efficacy score shows Googlebot is taking too long to visit content that matters, what can you do to optimize crawling?
Search Engine Support For Crawling
There has been a lot of talk in the last few years about how search engines and their partners are focused on improving crawling.
After all, it’s in their best interests. More efficient crawling not only gives them access to better content to power their results, but it also helps the world’s ecosystem by reducing greenhouse gases.
Most of the talk has been around two APIs that are aimed at optimizing crawling.
The idea is rather than search engine spiders deciding what to crawl, websites can push relevant URLs directly to the search engines via the API to trigger a crawl.
In theory, this not only allows you to get your latest content indexed faster, but also offers an avenue to effectively remove old URLs, which is something that is currently not well-supported by search engines.
Non-Google Support From IndexNow
The first API is IndexNow. This is supported by Bing, Yandex, and Seznam, but importantly not Google. It is also integrated into many SEO tools, CRMs & CDNs, potentially reducing the development effort needed to leverage IndexNow.
This may seem like a quick win for SEO, but be cautious.
Does a significant portion of your target audience use the search engines supported by IndexNow? If not, triggering crawls from their bots may be of limited value.
But more importantly, assess what integrating on IndexNow does to server weight vs. crawl efficacy score improvement for those search engines. It may be that the costs are not worth the benefit.
Google Support From The Indexing API
The second one is the Google Indexing API. Google has repeatedly stated that the API can only be used to crawl pages with either jobposting or broadcast event markup. And many have tested this and proved this statement to be false.
By submitting non-compliant URLs to the Google Indexing API you will see a significant increase in crawling. But this is the perfect case for why “crawl budget optimization” and basing decisions on the amount of crawling is misconceived.
Because for non-compliant URLs, submission has no impact on indexing. And when you stop to think about it, this makes perfect sense.
You’re only submitting a URL. Google will crawl the page quickly to see if it has the specified structured data.
If so, then it will expedite indexing. If not, it won’t. Google will ignore it.
So, calling the API for non-compliant pages does nothing except add unnecessary load on your server and wastes development resources for no gain.
Google Support Within Google Search Console
The other way in which Google supports crawling is manual submission in Google Search Console.
Most URLs that are submitted in this manner will be crawled and have their indexing status changed within an hour. But there is a quota limit of 10 URLs within 24 hours, so the obvious issue with this tactic is scale.
However, this doesn’t mean disregarding it.
You can automate the submission of URLs you see as a priority via scripting that mimics user actions to speed up crawling and indexing for those select few.
Lastly, for anyone who hopes clicking the ‘Validate fix’ button on ‘discovered currently not indexed’ exclusions will trigger crawling, in my testing to date, this has done nothing to expedite crawling.
So if search engines will not significantly help us, how can we help ourselves?
How To Achieve Efficient Site Crawling
There are five tactics that can make a difference to crawl efficacy.
1. Ensure A Fast, Healthy Server Response
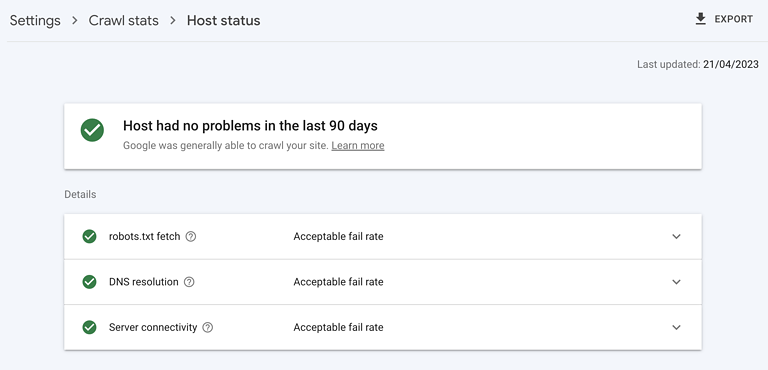 Screenshot from Google Search Console, May 2023
Screenshot from Google Search Console, May 2023A highly performant server is critical. It must be able to handle the amount of crawling Googlebot wants to do without any negative impact on server response time or erroring out.
Check your site host status is green in Google Search Console, that 5xx errors are below 1%, and server response times trend below 300 milliseconds.
2. Remove Valueless Content
When a significant portion of a website’s content is low quality, outdated, or duplicated, it diverts crawlers from visiting new or recently updated content as well as contributes to index bloat.
The fastest way to start cleaning up is to check the Google Search Console pages report for the exclusion ‘Crawled – currently not indexed.’
In the provided sample, look for folder patterns or other issue signals. For those you find, fix it by merging similar content with a 301 redirect or deleting content with a 404 as appropriate.
3. Instruct Googlebot What Not To Crawl
While rel=canonical links and noindex tags are effective at keeping the Google index of your website clean, they cost you in crawling.
While sometimes this is necessary, consider if such pages need to be crawled in the first place. If not, stop Google at the crawling stage with a robot.txt disallow.
Find instances where blocking the crawler may be better than giving indexing instructions by looking in the Google Search Console coverage report for exclusions from canonicals or noindex tags.
Also, review the sample of ‘Indexed, not submitted in sitemap’ and ‘Discovered – currently not indexed’ URLs in Google Search Console. Find and block non-SEO relevant routes such as:
- Parameter pages, such as ?sort=oldest.
- Functional pages, such as “shopping cart.”
- Infinite spaces, such as those created by calendar pages.
- Unimportant images, scripts, or style files.
- API URLs.
You should also consider how your pagination strategy is impacting crawling.
4. Instruct Googlebot On What To Crawl And When
An optimized XML sitemap is an effective tool to guide Googlebot toward SEO-relevant URLs.
Optimized means that it dynamically updates with minimal delay and includes the last modification date and time to inform search engines when the page last was significantly changed and if it should be recrawled.
5. Support Crawling Through Internal Links
We know crawling can only occur through links. XML sitemaps are a great place to start; external links are powerful but challenging to build in bulk at quality.
Internal links, on the other hand, are relatively easy to scale and have significant positive impacts on crawl efficacy.
Focus special attention on mobile sitewide navigation, breadcrumbs, quick filters, and related content links – ensuring none are dependent upon Javascript.
Optimize Web Crawling
I hope you agree: website crawling is fundamental to SEO.
And now you have a real KPI in crawl efficacy to measure optimizations – so you can take your organic performance to the next level.
More resources:
- How & Why To Prevent Bots From Crawling Your Site
- 14 Must-Know Tips For Crawling Millions Of Webpages
- Advanced Technical SEO: A Complete Guide
Featured Image: BestForBest/Shutterstock
